Prompt-based · Point-based Editing / Multimodal Instruction 개념을 정리했습니다.
이미지 생성 모델의 미래를 짚어 보았습니다.
😎 요즘은 어떤 이미지 생성 모델을 연구할까?
안녕하세요, 에디터 배니입니다.
2년 전부터 급부상한 생성 모델은 여전히 비전 분야의 트렌드를 이끌고 있습니다. 많은 사람들이 AI로 생성된 이미지를 한 번쯤 본 적이 있을 것입니다. 이 기술의 성능은 이미 매우 뛰어난 수준에 이르러 실제 서비스로 상용화됐는데요. 앞으로 어떤 점이 더 발전할 수 있을지 주목받고 있습니다.
최근 발표된 논문의 주제를 살펴보면 개인 맞춤형 이미지 편집 기술과 관련된 연구가 활발히 진행되고 있습니다. 다양한 이미지 생성 방법 중에서도 특히 텍스트 프롬프트를 입력해 이에 맞는 이미지를 생성하는 Text-to-Image 기술이 대표적인 방법으로 꼽힙니다. 프롬프트를 상세히 구성할수록 원하는 이미지를 얻을 가능성이 높지만, 상업적으로 사용할 수준의 고품질 이미지를 얻기에는 한계가 있습니다. 이미지 생성 분야가 새로운 산업으로 자리 잡기 위해서는 상상한 결과를 그대로 표현하면서도 높은 품질을 보장하는 기술 개발이 필요한데요. 이러한 배경에서 사용자가 원하는 대로 이미지를 편집할 수 있는 기술이 추가적으로 개발되고 있습니다.
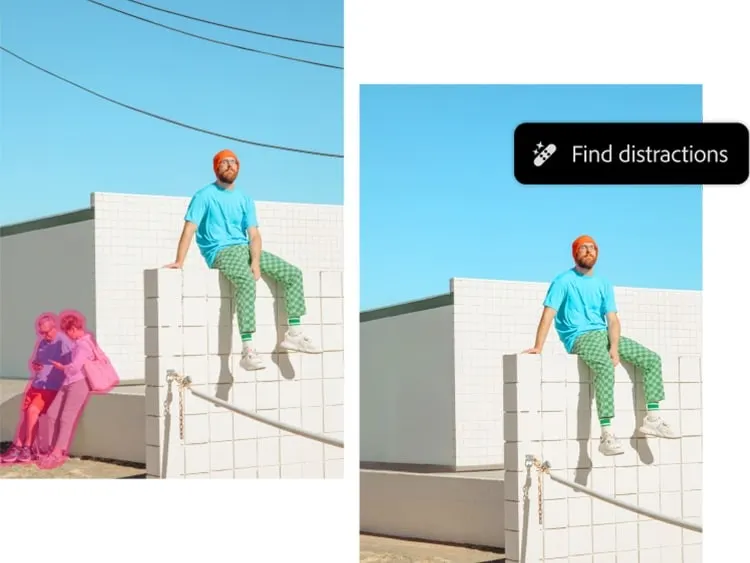
대표적인 사례가 Adobe Firefly입니다. 최근 Adobe는 자사 서비스에 AI 기능을 도입하여 텍스트 프롬프트를 활용해 이미지를 자유롭게 편집할 수 있는 기능을 제공하고 있습니다. 아래 이미지와 같이 신발 옆에 꽃잎을 추가한다거나, 피사체 외의 배경에 나타나는 인물을 제거할 수 있도록 지원합니다. 이는 사용자의 편의성과 창의성을 극대화하는 방향으로 발전하고 있는 기술의 한 예라고 할 수 있습니다.
이처럼 Adobe Firefly가 제공하는 생성 모델은 주변 배경과 어울리게 오브젝트를 추가하거나 제거하는 방식으로 이뤄집니다. 최근 연구는 이보다 더 나아가서 사용자와 직접 상호작용하며 이미지를 편집할 수 있는 기능을 제공하는데요. 이러한 기술의 근간이 되는 연구를 몇 가지 살펴보겠습니다.
Prompt-based Editing
지난해 11월, Meta는 이미지 편집 모델 Emu Edit을 공개했습니다. 이 모델은 Adobe가 상용화한 서비스의 기술을 대부분 포함하고 있는 모델입니다. Emu Edit은 Meta가 자체 개발한 Emu 모델의 확장 버전으로, Emu 모델은 디테일까지 놓치지 않을 정도로 정밀한 이미지 생성을 목표로 했습니다. 이러한 정신을 계승한 Emu Edit은 사용자의 요청을 이해하면서 동시에 컴퓨터 비전 태스크에 활용할 수 있는 결과까지 생성할 수 있다는 점이 특징입니다.
위 예시는 고양이 이미지로부터 의상, 배경 등을 편집하고 더 나아가 Depth Map과 분할(Segmentation) 결과까지 추출하는 과정을 보여줍니다. (a) 고양이 이미지부터 (j)의 고슴도치 이미지까지 계속 수정 사항을 입력해 생성한 결과물입니다. 여러 차례 연속적인 편집이 가능하다는 점에서 사용성이 높습니다. 이처럼 Emu Edit은 일부 영역의 대상을 추가 및 제거하는 지역 기반 편집(Region-based Editing), 스타일과 배경 등을 자유롭게 편집하는 자유 편집(Freeform Editing), 탐지 및 분할 등 비전 태스크(Vision Tasks)를 지원합니다.
Point-based Editing
Emu Edit이 프롬프트 기반으로 동작한다면, 포인트 기반 방식은 사용자가 직접 이미지를 조작하는 방식입니다. 이미지 내 특정 포인트를 선택하고 이를 드래그하여 원하는 대로 변형하는 방식이에요. 지난해 공개된 DragGAN과 DragDiffusion이 대표적인 예입니다. ‘아, 이 부분이 조금만 바뀌었으면 좋겠는데…’ 하고 생각했던 적이 있다면, 이 모델의 기능이 아주 반가울 것입니다.
예를 들어, 고양이의 시선을 조금 오른쪽으로 옮기거나 버스의 크기를 조정하고 싶을 때, 특정 지점(빨간 점)을 선택하고 원하는 위치(파란 점)로 옮기기만 하면 됩니다. 이 방식의 학습 방법을 간단히 설명하자면, 사용자가 지정한 포인트를 추적하며 조금씩 이미지를 변형해나가면서 기존 객체의 형태를 유지하고 완성도 높은 결과를 제공합니다. 프롬프트 방식은 모델이 입력을 잘못 해석해 엉뚱한 결과를 낼 수 있지만, 드래그 방식은 더욱 정확한 편집 영역을 지정하고 결과를 직관적으로 해석할 수 있다는 점에서 큰 장점이 있습니다.
Multimodal Instruction
앞선 방법들이 하나의 이미지 내에서 편집을 수행하는 방식이었다면, Multimodal Instruction 모델은 사용자의 다양한 요청을 받아 이미지를 생성하는 모델입니다. 이러한 요청에는 텍스트 프롬프트뿐만 아니라 이미지, 마스크, 스타일 이미지 등이 포함됩니다. 이는 새로운 아이디어와 영감을 얻기에 최적화된 생성 모델이라고 할 수 있습니다.
지난 1월, Google은 Instruct-Imagen 논문을 발표했습니다. 이 모델은 Google의 생성 모델인 Imagen을 응용한 것으로, 다양한 모달리티의 지시 사항을 입력받을 수 있다는 점이 특징입니다.
텍스트 프롬프트만 사용한다면 원하는 결과를 보장하기 어렵습니다. 하지만 간단한 스케치나 그림 스타일을 함께 제시하면 내가 원하는 결과물에 훨씬 더 가깝게 이미지를 생성할 수 있습니다. 여기서 가장 중요한 점은 학습 데이터 외에 새로운 대상에 대해서도 추론을 잘할 수 있는 능력을 보유했냐는 것입니다. 이를 ‘일반화(Generalization)’라고 합니다.
예를 들어, 멀티모달 지시 사항으로 가장 아래 예시와 같이 'monster toy'이미지를 입력받으면 일반적으로 알려진 ‘빨간 괴물’이 아니라 사용자가 제공한 이미지 속에 포함된 구체적인 ‘빨간 괴물’의 형상을 정확히 생성해야 합니다. 일반적인 괴물을 그리는 건 어렵지 않을 것입니다. 하지만 사용자가 제공한 이미지는 모델이 한 번도 학습한 적 없는 데이터일 가능성이 높습니다.이때 사용자가 제공한 'monster toy' 에 대한 기본적인 특성을 파악해야 높은 품질의 이미지를 생성할 수 있습니다.
특히, 이미지나 마스크 등 텍스트 외의 멀티모달 데이터를 입력받는 특성 때문에 훈련 과정에서도 이러한 데이터를 포함시키는 것이 중요합니다. 이를 위해 Google은 검색 증강 방식(Retrieval-augmented)으로 인터넷 데이터를 활용하여 모델을 훈련시켰습니다. 덕분에 사용자는 상상하던 결과물에 더욱 가까운 이미지를 얻는 동시에, 생성 모델이 만들어낸 창의적인 결과물을 받아볼 수 있는 장점이 있습니다.
이렇게 이미지 생성 모델의 3가지 트렌드를 알아봤습니다. 앞서 언급한 것처럼 이미지 생성 모델 성능이 아무리 뛰어나다고 해도 아직 실제 상품화까지 이르진 못했죠. 하지만 생성 모델보다 더 중요한 것은 창작하고자 하는 인간의 마음입니다. 생성 모델은 그것을 도와줄 뿐이죠. AI가 아무리 생성을 잘한다고 하더라도 생성된 결과물을 해석하고 활용하는 것은 역시 인간의 몫입니다.
또한 생성 모델이 더 실용적인 결과물을 제공하기 위해서는 예술이 이뤄지는 과정과 그 의도를 이해해야 합니다. 단순히 무엇인가를 생성한다고 작품이 되는 것은 아닙니다. 하지만 반대로 생성된 결과물이 어떻든 그것에 의미를 부여한다면 새로운 작품이 될 수 있기도 하죠. 앞으로 이미지 생성 모델에 추상적인 의미를 파악하도록 하고, 생성 결과에 반영할 것인지 연구해 나가야 하지 않을까 생각합니다.