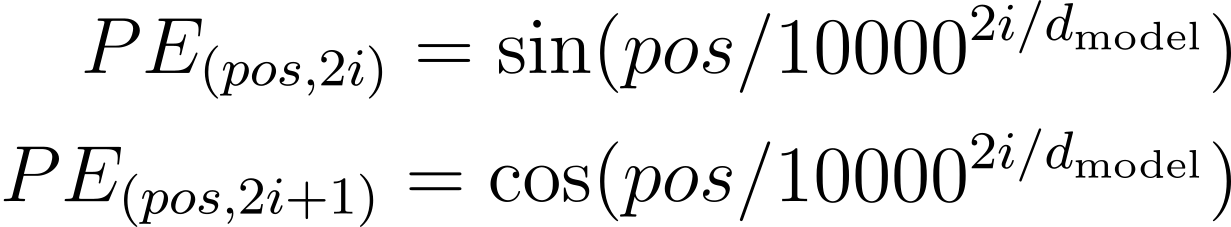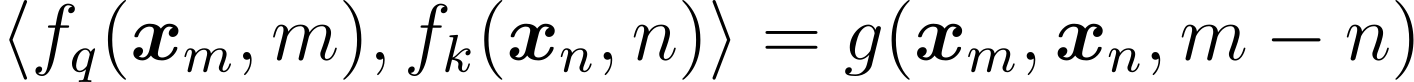트랜스포머의 위치 인코딩은 어떤 변화를 겪었는지 살펴봅니다. # 68 위클리 딥 다이브 | 2024년 12월 4일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 트랜스포머의 위치 인코딩에 대해 설명합니다.
- 상대적 위치 인코딩과 절대적 위치 인코딩을 비교합니다.
- Rotary Position Embedding(RoPE)를 소개합니다.
|
|
|
🗨️ 언어 모델이 단어의 순서를 이해하는 방법 |
|
|
안녕하세요, 에디터 민재입니다.
2017년 구글이 발표한 논문, Attention Is All You Need (Vaswani et al., 2017)을 통해 트랜스포머가 등장한 이후 벌써 7년이 넘는 시간이 지났습니다. 크고 작은 변화는 있었지만, 트랜스포머는 여전히 굳건한 입지를 지키고 있죠. 이전 뉴스레터에서는 트랜스포머가 기존의 언어 모델과 무엇이 다른지를 살펴봤습니다.
가장 큰 차이점은 RNN을 전혀 사용하지 않고, 셀프 어텐션이라는 메커니즘만을 사용해 문장을 표현했다는 것입니다. 그런데 셀프 어텐션의 실체를 뜯어보면, 가장 단순한 신경망인 완전 연결(Fully Connected, FC) 레이어라는 걸 알 수 있습니다. 그러면 왜 기존에는 FC 레이어를 사용해서 문장을 표현할 생각을 하지 못했을까요? |
|
|
우선 FC 레이어의 생김새를 살펴보겠습니다. FC 레이어는 입력 뉴런과 출력 뉴런으로 구성되는데, 모든 입력과 출력 뉴런이 연결되어 있습니다. 그리고 각각의 뉴런이 연결된 강도를 가중치(Weight)로 표현하죠. 이런 성질 덕분에 FC 레이어는 입력과 출력을 구성하는 모든 요소 사이의 관계를 표현할 수 있다는 장점이 있습니다. 게다가 그 관계를 한 번에 계산할 수 있다는 장점까지 갖습니다. |
|
|
문제는 FC 레이어가 뉴런 사이의 순서를 생각하지 않는다는 것입니다. 자연어의 상황에 대응하면, 문장 내 단어의 순서를 고려하지 않는다는 뜻이죠. 즉, 원래의 FC 레이어는 “고양이가 쥐를 쫓아갔다.”와 “쥐가 고양이를 쫓아갔다.”라는 문장을 구분하지 못합니다. |
|
|
FC 레이어가 갖는 문제를 해결하기 위해서 트랜스포머 논문에서는 위치 인코딩(Positional Encoding)이라는 개념을 제안합니다. 문장을 구성하는 각 단어를 FC 레이어의 각 노드로 표현할 때, 각 단어에 대한 정보에 위치 정보를 더해서 함께 표현하겠다는 의도이죠.
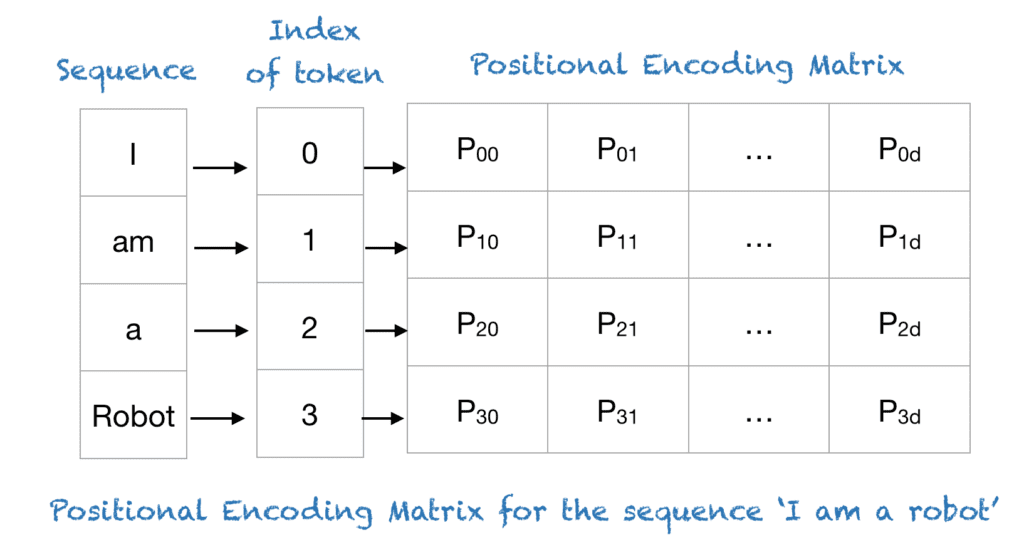
위치 인코딩이 만들어지는 과정을 살펴보겠습니다. 먼저 아래 그림과 같이 문장을 이루는 각 단어에 순서를 매깁니다. 이를 인덱스(Index)라고 하는데, 그다음에 인덱스를 벡터로 변환합니다. 그리고 이 값을 단어의 의미를 나타내는 벡터에 더해주는 것이죠. 그러면 최종적으로 각 노드는 단어의 의미와 순서에 대한 정보를 동시에 표현할 수 있게 됩니다. |
|
|
|
트랜스포머에서는 위치 인코딩에 아래 수식과 같이 사인과 코사인 함수를 사용했습니다. 단어의 위치 정보를 나타내는 것이 목적이라면, 단순히 인덱스를 사용하면 될 텐데 왜 이렇게 복잡한 식을 사용했을까요? |
|
|
우선 인덱스를 그대로 사용하는 방법에는 몇 가지 문제가 있습니다. 문장의 길이가 길어지면, 문장 후반에 나오는 단어의 인덱스는 그에 따라 커지게 됩니다. 그러면 이 값이 단어의 의미를 나타내는 벡터, 즉 단어 임베딩(Word Embedding)에 더해졌을 때, 단어 임베딩이 제대로 된 역할을 하지 못하게 될 수 있습니다. 단어 임베딩과 위치 인코딩이 더해진 벡터는 두 정보를 조화롭게 표현해야 하는데, 위치 인코딩의 값이 과도하게 커지면서 단어 임베딩의 역할이 무시될 수 있죠.
그렇다면 인덱스를 문장의 길이로 나눠서 더해주면 어떨까요? 예를 들어, 위 예시 문장의 첫 번째 단어인 “I”의 인덱스를 1 대신 문장의 길이인 4로 나눈 1/4로 표현하는 것이죠. 이런 문제는 위치 인코딩의 영향력을 줄일 수는 있지만, 같은 위치라도 문장의 길이에 따라 다른 값이 더해진다는 문제가 있습니다. 결국 위치 정보를 일관되게 표현할 수 없게 됩니다.
그래서 트랜스포머는 사인과 코사인 함수를 사용한 것입니다. 이 함수는 값의 범위가 제한되어 있으며, 일관된 방식으로 위치 정보를 표현할 수도 있죠. 그런데 문득 이런 생각이 들 수도 있습니다. “사인 함수는 주기를 갖는데, 문장의 길이가 매우 길어지면 같은 값이 반복될 위험이 있지 않을까요?”
그럴듯한 생각이지만, 사실 그럴 일은 거의 없습니다. 위치 인코딩은 실제로 하나의 값이 더해지는 게 아니라 벡터입니다. 그래서 벡터의 각 요소는 모두 다른 주기를 갖는 사인 또는 코사인 함수의 값에 대응합니다. 위 식을 자세히 다시 살펴보면, pos가 단어의 실제 위치를 나타낸다면, i는 위치 인코딩 벡터에서 몇 번째 요소인지를 의미합니다. 결과적으로 이 벡터의 모든 요소가 같아질 가능성은 거의 없습니다.
|
|
|
위치 인코딩을 도입한 트랜스포머는 언어 모델의 성능을 크게 개선했지만, 여전히 문제는 있었습니다. 성능이 개선된 모델이 더 길고 복잡한 입력을 처리하길 기대했는데, 문장의 길이가 매우 길어지면 성능이 떨어졌습니다. 이 문제의 원인은 기존의 위치 인코딩이 정의되는 방식에 있었습니다.
위치 인코딩은 크게 두 가지 방법으로 구분할 수 있습니다. 각각 절대적(Absolute)인 방법과 상대적(Relative)인 방법입니다. 트랜스포머의 위치 인코딩은 절대적인 방법을 사용하여, 다른 단어와의 관계를 고려하지 않고 단순히 스스로의 위치 정보만을 포함합니다. 물론 트랜스포머를 제안한 연구진은 위치 인코딩에 사용하는 함수의 성질을 고려하면, 모델이 스스로 단어 간의 상대적인 위치를 학습할 거라고 기대했죠.
그 가정은 어느 정도 통하는 듯 했지만, 문장의 길이가 길어질수록 문제가 뚜렷해졌습니다. 그러면서 절대적 위치 인코딩이라는 방식에 의문이 제기되었죠. 우리가 문장 내 단어의 의미를 생각할 때, 단어 사이의 거리가 실제로 얼마나 떨어져 있느냐는 크게 중요하지 않습니다. 그저 얼마나 떨어져 있는지 그 상대적인 위치 관계가 중요합니다.
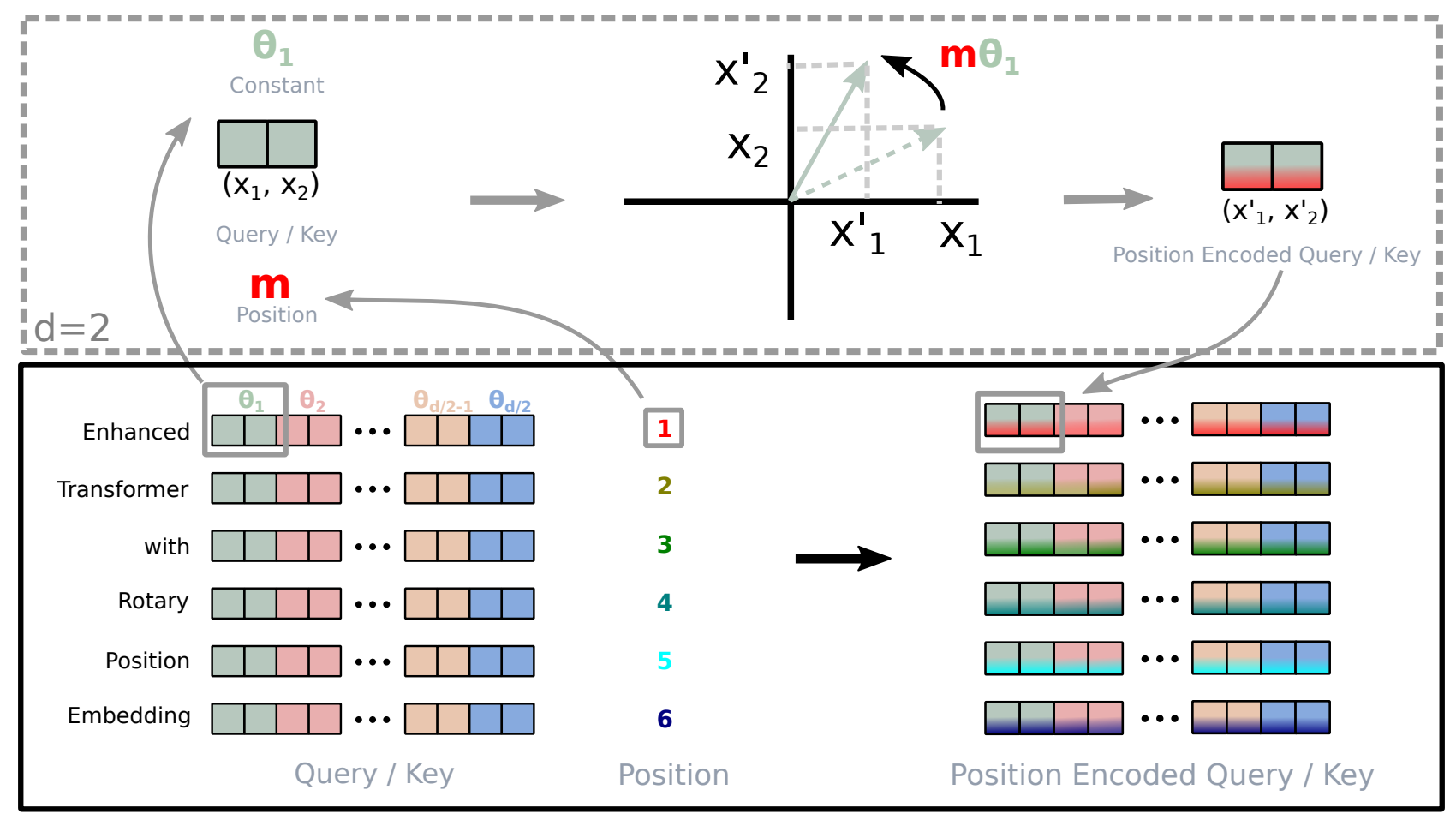
이런 의문에서 출발한 연구는 곧 RoPE(Rotary Position Embedding)라는 방법으로 이어졌습니다. RoPE는 RoFormer: Enhanced Transformer with Rotary Position Embedding (Su et al, 2021)에서 제안된 방법으로, 회전 행렬(Rotation Matrix)이라는 개념을 사용합니다. 회전 행렬은 두 단어의 관계를 계산할 때, 즉 Query와 Key의 연산이 이뤄질 때 사용되며, 회전 행렬에는 각 단어의 절대적인 위치 정보가 포함되지만, 연산 과정에서는 상대적인 위치 관계를 표현할 수 있게 됩니다. |
|
|
결국 RoPE의 목적은 단어 사이의 상대적인 위치 관계를 나타내는 것입니다. RoPE는 m번째 위치의 단어와 n번째 위치의 단어의 위치 관계를 표현하기 위해, 각 단어의 임베딩인 x_m과 x_n, 그리고 둘 사이의 상대적 위치 m-n을 입력하는 함수 g를 사용합니다. 그리고 이 함수를 m번째 단어의 Query와 n번째 단어의 Key의 내적으로 표현하고자 합니다. 실제로 내적을 통해 벡터 사이의 유사도를 구할 수 있으므로, 이는 단어 사이의 관계를 표현하기 적절한 도구입니다.
위에서 복잡하게 설명한 내용을 식으로 나타내면 아래와 같은데, 결국 아래 수식의 해를 구하면 RoPE의 목적을 달성할 수 있습니다. 연구진은 벡터의 기하학적 성질을 바탕으로 이 식의 해가 회전 행렬을 사용하여 나타낼 수 있음을 발견하였고, 그 결과 RoPE가 탄생하게 되었습니다. |
|
|
RoPE의 위치 임베딩이 만들어지는 과정을 그림으로 표현하면 아래와 같은데, 트랜스포머의 위치 인코딩과 다르게 RoPE는 각 단어의 Query와 Key가 실제로 사용되는 단계에서 위치 임베딩이 계산됩니다. 따라서 앞서 언급했듯, 단어 사이의 상대적인 위치를 고려할 수 있게 되며, 그 거리가 매우 멀어져도 일반화가 잘 된다는 장점이 있습니다. 이런 성질 덕분에 LLM이 처리할 수 있는 문맥의 길이가 매우 길어져도 효과적으로 텍스트를 이해할 수 있게 됩니다. |
|
|
지금까지 살펴본 것과 같이 지난 7년간 딥러닝을 지배한 트랜스포머는 대체되지 않기 위해서 크고 작은 변화를 겪었습니다. LLM의 시대에서 트랜스포머는 연산 효율이 매우 낮은 편이기 때문에, 대부분의 변화는 그런 부분과 관련이 있죠. 하지만 LLM의 연산 효율 문제는 아직까지도 계속해서 지적되고 있는 문제입니다. LLM이 인간 못지않은 성능을 가졌음에도, 널리 사용되고 있지 못하는 이유도 여기에 있습니다.
물론 최근에는 LLM의 연산 효율을 개선하는 방향보다는, LLM 자체의 규모를 줄이는 방향의 연구가 다수 이뤄지고 있습니다. 그러면서 빠르고 강력한 성능을 보이는 모델이 계속해서 등장하고 있죠. 그럼에도 여전히 LLM의 효율성과 성능 사이의 균형을 맞추기 위한 연구는 중요한 과제로 남아 있습니다. RoPE 또한 이러한 맥락에서 이뤄진 시도이죠. 앞으로는 어떤 획기적인 연구를 통해 빠르고 강력한 LLM이 등장할지가 기대됩니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|