PEFT의 등장 배경을 이해하고, 기존 PEFT 방법론들의 한계를 극복한 LoRA에 대해 알아봅시다. # 66 위클리 딥 다이브 | 2024년 11월 20일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- PEFT가 등장한 배경에 대해 알아봅니다.
- 초기 PEFT의 문제점을 이해합니다.
- LoRA에 대해 알아봅니다.
|
|
|
안녕하세요, 에디터 잭잭입니다.
인공지능 모델의 규모가 점점 커지면서, 효율적인 학습방법이 주목을 받고 있습니다. 오늘은 그중 하나인 Parameter-Efficient Fine-Tuning (PEFT)에 대해 소개하려고 합니다. 초거대 모델이 중심이 되는 시대에, 모든 매개변수를 미세 조정하는 방식은 막대한 자원을 소모합니다. 약 40억 개의 매개변수를 가진 모델을 훈련하려면 A100 80GB의 GPU가 최소 1,000~2,000대가 필요하다고 해요. 이처럼 모든 매개변수를 조정하는 방식은 시간과 비용의 문제, 그리고 최근 주목받고 있는 에너지 문제를 가지고 있습니다.
이제 모델 전체를 파인튜닝하는 것은 웬만큼 큰 기업이 아니면 시도하기 어렵습니다. 또한 특정 작업에 활용하기 위해 독립적으로 파인튜닝된 모델이 여러 개라면, 이를 각각 저장하고 배포하는 데 드는 비용도 급격히 증가합니다. 미세 조정된 모델이 원래 사전 학습된 모델과 동일한 크기를 가지고 있기 때문에, 파인튜닝된 모델이 늘어날 때마다 비용도 그만큼 증가하는 것이죠.
이러한 문제를 해결하기 위해 PEFT 접근법이 등장했습니다. PEFT는 대규모 모델의 전체가 아닌 일부 매개변수만 조정하는 여러 가지 방법을 도입하여 대규모 모델을 보다 효율적이고 경제적으로 활용할 수 있도록 합니다.
그렇다면 어떤 방법들이 있는지 살펴볼까요? |
|
|
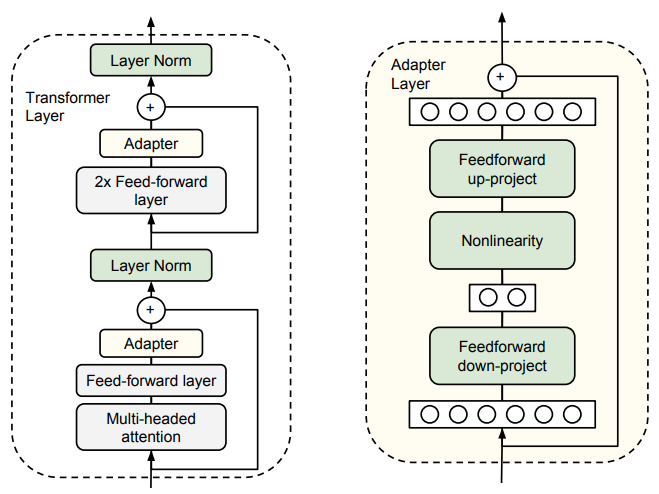
PEFT의 시작이 되는 연구인 <Parameter-Efficient Transfer Learning for NLP>(Houlsby et al., 2019) 에서는 Adaptive PEFT를 소개합니다. Adaptive의 사전적 정의는 “적응할 수 있는” 이라는 뜻인데요. 이처럼 특정 작업이나 데이터 셋의 요구사항에 맞게 모델 아키텍처 내에 학습 가능한 어댑터를 추가하는 방법입니다.
사전 학습된 백본을 변경하지 않기 때문에, 만일 특정 작업을 위해 파인 튜닝을 하게 되면, 추가된 어댑터의 매개변수만 업데이트 되므로 저장 공간과 메모리를 크게 절약할 수 있습니다. |
|
|
위 그림에서 각 트랜스포머 블록에 두 개의 어댑터 모듈이 있는데, 하나는 멀티 헤드 어텐션(Multi-headed attention) 레이어 뒤에 추가되고 다른 하나는 FFN(Feed-forward) 레이어 뒤에 추가되었습니다. 멀티 헤드 어텐션 레이어 뒤의 어댑터는 입력 데이터의 관계나 컨텍스트(문맥) 정보를 처리하고, 학습한 정보에 맞춰 매개변수가 업데이트됩니다. 그리고 FFN 레이어 뒤의 어댑터는 어텐션 이후의 표현을 기반으로, 모델이 학습한 정보의 특징을 보완하고 강화해요. FFN은 어텐션 레이어에서 처리된 정보를 비선형적으로 확장하고 축소하므로, 어댑터가 뒤에 배치되어 이를 효율적으로 조정하며 학습의 효과를 극대화합니다.
이처럼 트랜스포머 블록 안에 어댑터 레이어를 순차적으로 배치하는 방법을 순차적 설계(Sequential design)라고 해요. Parameter-Efficient Transfer Learning for NLP에서는 BERT 모델에 작은 어댑터 모듈을 추가해 다양한 작업에 적용하는 실험을 진행하였습니다. 실험 결과, 거의 기존 성능을 유지하면서도 추가되는 어댑터 매개변수의 수는 모델 크기의 3~4%에 불과했는데요. 이처럼 Addaptive PEFT는 기존 모델의 모든 매개변수를 고정하고 특정 작업에 필요한 추가 모듈만 학습하기 때문에 자원 효율성이 뛰어나다는 장점이 있습니다.
그러나 이 방법은 추론 지연(Inference time latency)을 초래합니다. 순차적으로 설계된 어댑터 계층은 병렬 처리가 불가능하여, 모델의 규모가 커질 수록 병목현상이 일어난다는 문제점이 있습니다. |
|
|
|
프롬프트 튜닝(Prompt Tuning)은 모델의 성능을 높이기 위한 새로운 접근법으로, 기존 모델의 모든 파라미터를 바꾸지 않고, 입력에 약간의 "힌트"를 더하는 방식입니다.
기존에는 모델이 특정 작업을 잘 수행하도록 하려면, 모델의 많은 부분을 다시 학습시키는 파인튜닝을 해야 했습니다. 하지만 프롬프트 튜닝에서는 이렇게 하지 않고, 소프트 프롬프트(Soft Prompt)라고 불리는 조정 가능한 벡터를 입력 데이터의 시작 부분에 추가합니다.
소프트 프롬프트는 일반 텍스트 프롬프트(예: "질문: 이것은 무엇인가요? 답변:")처럼 고정된 문구가 아니라, 모델이 학습을 통해 유연하게 최적화할 수 있는 연속적인 값들로 표현됩니다. 이 방식은 모델이 입력 데이터를 더 잘 이해할 수 있도록 도와주며, 기존 모델 구조를 거의 바꾸지 않으면서 성능을 향상시킬 수 있다는 장점이 있습니다.
그러나 이 방법은 프롬프트 최적화가 매우 어렵다는 것, 그리고 학습 가능한 매개변수의 변화에 따라 성능이 불규칙적으로 변화한다는 문제점이 있습니다.
|
|
|
앞서 설명한 PEFT 방법이 모델 전체를 파인튜닝하는 것보다 유용해 보입니다. 그러나 모델의 규모가 커지면 성능을 보장하기 어렵다는 문제가 있습니다. 모델의 규모가 점점 커지기 시작하자, 연구자들은 규모에 상관없이 효율적이고 안정적으로 파인튜닝 할 수 있는 방법을 고민하였습니다.
LoRA는 Low-Rank Adaptation의 약자로, 사전 학습된 모델의 일부 가중치만을 저랭크(Low-rank) 구조로 업데이트하는 방법입니다. 기존의 파인튜닝 방식은 모델의 모든 매개변수를 재학습해야 했지만, LoRA는 핵심 가중치 행렬 업데이트를 저랭크 분해를 통해 간소화 한다는 점이 핵심입니다.
내재적 차원(Intrinsic dimension)이란, 모델이 특정 작업을 학습하거나 적응하는 데 꼭 필요한 최소한의 표현 공간을 뜻합니다. 예를 들어, 모델의 가중치 행렬은 보통 고차원 공간에 존재하지만, 실제로 학습에 사용되는 중요한 정보는 그보다 훨씬 낮은 차원으로 표현될 수 있습니다. LoRA는 이 개념을 활용하여, 사전 학습된 모델의 가중치를 고정하고, 필요한 가중치의 업데이트를 저차원 공간에서만 수행합니다. 이 방법을 사용하면 원래 모델이 가진 복잡한 고차원 공간을 단순화하면서도 성능은 그대로 유지할 수 있기 때문에, 규모가 큰 모델에도 효과적으로 사용될 수 있습니다.
쉽게 말해, LoRA는 "모든 것을 학습하는 대신, 꼭 필요한 부분만 작은 공간에서 효율적으로 조정한다"고 이해할 수 있습니다. 학습해야 할 매개변수 수를 기존 방식보다 10,000배나 줄이면서도, 모델의 속도나 성능에는 영향을 주지 않아요.
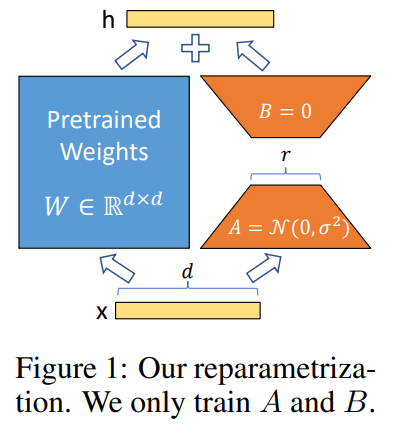
LoRA의 핵심 아이디어는 저랭크 분해입니다. 기존의 가중치 행렬 W를 고정한 상태에서, 학습 가능한 업데이트인 dW를, W = W_0 + dW = W_0 + BA 로 분해합니다. 훈련 중에는 사전 학습된 가중치 W_0는 고정되며, 학습 가능한 저랭크(Low-rank)인 B와 A만 최적화 됩니다. 이 방법은 기존 모델을 수정하지 않으면서도, 모델이 작업 특화 정보를 효율적으로 학습할 수 있게 해줍니다. |
|
|
왼쪽에 있는 파란색 상자는 사전 학습된 모델의 Weight 입니다. 이 Weight는 완전히 고정되어, 모델을 학습시킬때 변화되지 않는 부분입니다. 그리고 오른쪽의 주황색 박스 중 아래에 있는 A가 LoRA_A 계층, 그리고 위의 B가 LoRA-B 계층 입니다. 두 계층은 각각 {d x r} 차원과 {r x k} 차원을 가지고 있으며, 모델이 학습되면 LoRA_B x LoRA_A 계층의 행렬이 사전학습된 모델에 더해지게 됩니다. 즉, 사전학습된 모델의 Weight에 (LoRA_B x LoRA_A)의 행렬 값을 더해주기 때문에, 사전학습된 모델의 Weight를 고정해도 Inference 시 사용되는 Weight 값은 업데이트 됩니다.
LoRA는 특히 초거대 모델에서 학습해야 할 매개변수를 기존 모델의 약 0.1~0.5% 수준으로 줄이면서도, 전체를 파인튜닝 하는 방법보다 우수한 성능을 보였습니다. |
|
|
대규모 모델을 학습시키는 것 뿐만 아니라 모델 전체를 파인튜닝하는 것도 이제는 개인이나 소규모 회사에서 수행하기는 어려워 보입니다. 컴퓨터가 상용화 되었을 때, ‘정보의 불균형’이라는 단어가 대두되었죠. 컴퓨터를 잘 사용하지 못하는 사람들이 불평등과 소외감을 느낄 수 있다는 문제점이 있었는데요. 인공지능도 마찬가지인 것 같습니다. 항상 ‘공평’할 수는 없지만, 공평하게 사용할 수 있도록 최대한 노력해야 한다고 생각해요. 따라서 PEFT와 같이 적은 자원으로도 모델을 특정 작업에 특화시킬 수 있는 방법이 더욱 연구되면 좋겠습니다 🙂 |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|