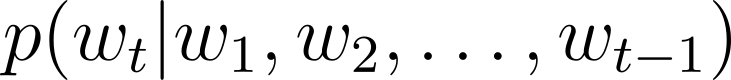RNN부터 트랜스포머까지, 언어 모델이 어떻게 발전해 왔는지를 알아봅니다. # 65 위클리 딥 다이브 | 2024년 11월 13일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 언어 모델이 자연어를 처리하는 데 공통적으로 사용하는 원칙을 정리합니다.
- 언어 모델이 어떻게 현재와 같은 모습을 갖추었는지, 그 역사를 살펴봅니다.
- 트랜스포머의 주요 특징과 한계에 대해 소개합니다.
|
|
|
🤖 트랜스포머는 어떻게 딥러닝을 지배할 수 있었을까? |
|
|
안녕하세요, 에디터 민재입니다.
제프리 힌턴이 노벨상을 받으면서 인공지능은 다양한 학문에 미치는 영향과 가치를 공식적으로 인정받았습니다. 역전파 알고리즘(Backpropagation), 제한된 볼츠만 머신(Restricted Boltzman Machine)을 비롯한 그의 여러 연구는 딥러닝의 발전에 중대한 기여를 했고, 이러한 공로로 노벨상의 영광을 안았습니다. 제프리 힌턴의 업적이 딥러닝의 초석을 놓았다면, 현대 딥러닝의 발전을 한층 가속한 연구는 무엇일까요?
딥러닝을 공부한 분들이라면 대부분 트랜스포머를 떠올릴 것입니다. 실제로 트랜스포머는 현대 딥러닝을 지배하는 핵심 개념이라고 봐도 과언이 아닙니다. 트랜스포머는 2017년 구글이 발표한 논문 Attention Is All You Need (Vaswani et al., 2017)에서 제안된 아키텍처인데요. 셀프 어텐션(Self-Attention)이라는 알고리즘을 기반으로 작동하는 트랜스포머는 어떤 방식으로 혁신을 일으켰을까요? |
|
|
논문에서는 트랜스포머를 Sequence Transduction 모델이라고 소개합니다. 형식 언어학에서는 Transduction을 어떤 문자열(String)이 입력되었을 때, 다른 문자열을 출력하는 것이라고 정의합니다. 또한 시퀀스는 순차적으로 이어지는 데이터를 의미하는데, 예를 들어 문장은 단어가 순차적으로 나열된 시퀀스입니다. 쉽게 생각하면 트랜스포머는 결국 시퀀스 변환 모델이라고 할 수 있습니다.
트랜스포머를 통해 해결하려는 문제는 언어라는 영역에 초점이 맞춰져 있었지만, 트랜스포머는 데이터의 실체가 무엇이든 시퀀스의 형태라면 모두 처리할 수 있습니다. 자연어 처리(Natural Language Processing, NLP)를 넘어서 모든 분야에서 영향력을 발휘할 수 있었던 이유이죠.
여기서는 특별히 딥러닝 모델이 언어를 처리하는 방식이 어떻게 변화했는지에 집중할 것이기 때문에, 시퀀스 모델링을 언어 모델링과 같다고 생각하겠습니다. 트랜스포머가 등장하기 이전의 언어 모델은 두 가지 치명적인 한계를 갖고 있었습니다. 장기 의존성 학습 문제와 병렬 처리가 불가능하다는 문제였는데, 이를 자세히 알아보기 전에 한 가지 짚고 넘어가야 할 사실이 있습니다. |
|
|
모든 언어 모델은 두 가지 주요 전제를 바탕으로 자연어를 이해하고 처리합니다. 첫 번째는 문장이 이전에 나온 맥락을 바탕으로 이어진다는 것입니다. 즉, 이전 단어나 문장이 이후에 올 단어나 문장의 의미와 구조에 영향을 미친다는 가정입니다. 이를 수식으로 표현하면 아래와 같은데, 문장 내에서 t번째 단어 w_t가 등장할 확률이 그 이전 단어들(w_1부터 w_t-1까지)에 의해 결정된다는 것을 의미합니다. 현재 가장 널리 알려진 언어 모델인 GPT 또한 이런 방식으로 문장을 생성합니다. |
|
|
두 번째는 단어의 의미가 주변 단어에 의해 결정된다는 것입니다. 이 전제는 언어학의 분포 가설(Distributional Hypothesis)에 기반하는데, 1957년 언어학자 존 루퍼트 퍼스가 “단어는 곁에 두는 친구를 보면 그 의미를 알 수 있다 (You shall know a word by the company it keeps)”고 표현한 이후 널리 알려졌습니다. 실제로 컴퓨터가 단어의 의미를 표현할 때 사용하는 문맥 창(Context Window)과 같은 개념은 이러한 가설에 근거합니다.
이 두 전제를 바탕으로 언어 모델은 문맥을 이해하고 자연스러운 언어를 생성하는 능력을 갖추게 됩니다. |
|
|
딥러닝을 활용한 언어 모델의 초기 단계에서는 주로 순환 신경망(Recurrent Neural Network, RNN)이 사용되었습니다. 딥러닝 모델은 입력과 출력의 형태가 정해져 있어야 한다는 제약이 있지만, 문장의 길이는 항상 똑같게 만들 수가 없습니다. 이런 문제를 해결하기 위해 등장한 RNN은 문장 내의 각 단어를 순차적으로 처리하여, 입력과 출력의 길이에 제약을 받지 않는다는 장점이 있었죠.
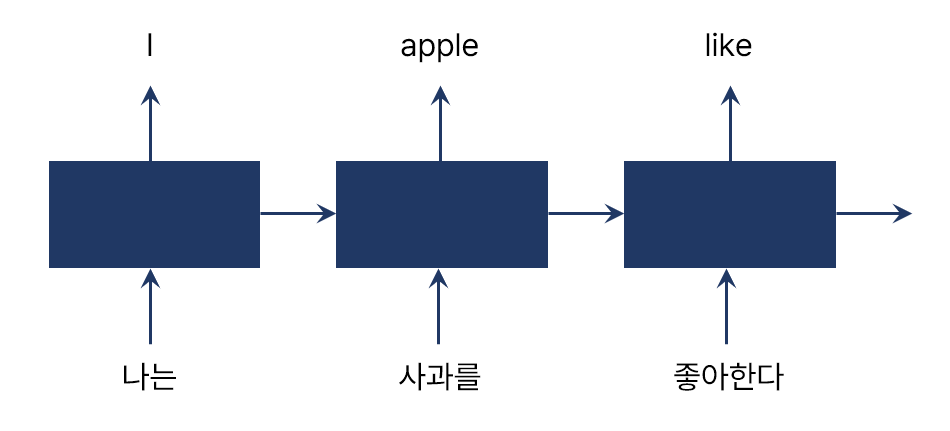
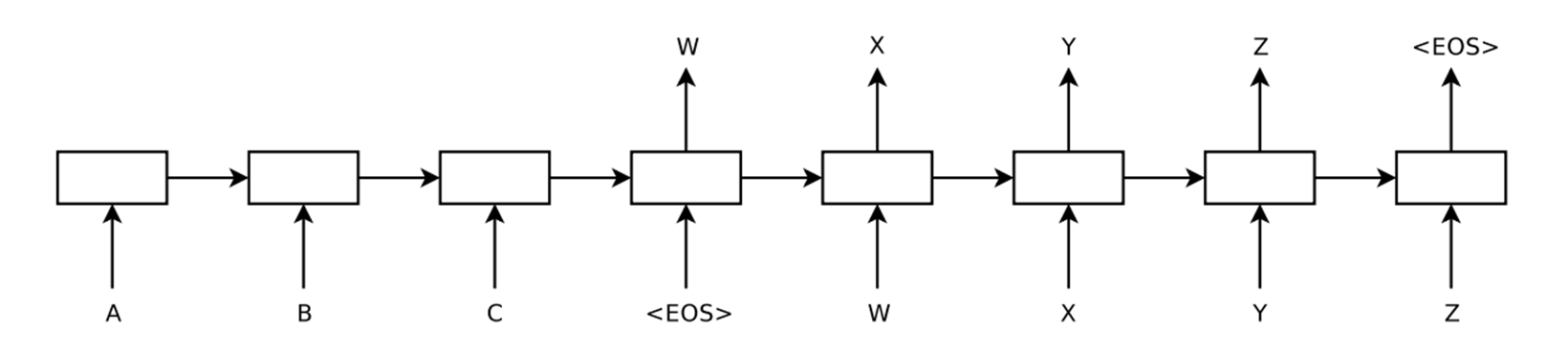
하지만 RNN에는 한 가지 큰 문제가 있었는데, 바로 입력과 출력 사이의 단조로운 정렬(Monotonic Alignment)을 전제한다는 것입니다. RNN은 문장 전체를 한 번에 받아들이지 않기 때문에, 뒤에 어떤 입력이 주어질지 모릅니다. 그렇기 때문에 현재까지 주어진 정보만을 바탕으로 출력을 생성해야 합니다. 따라서 아래와 같이 서로 다른 어순을 갖는 언어 사이의 번역을 할 때는 어려움을 겪게 되죠. 과거의 구글 번역기가 어땠는지를 생각해 보면 직관적으로 이해가 될 것 같습니다. |
|
|
RNN은 입력과 출력 사이의 단조로운 정렬을 전제로 한다.
ⓒ deep daiv. |
|
|
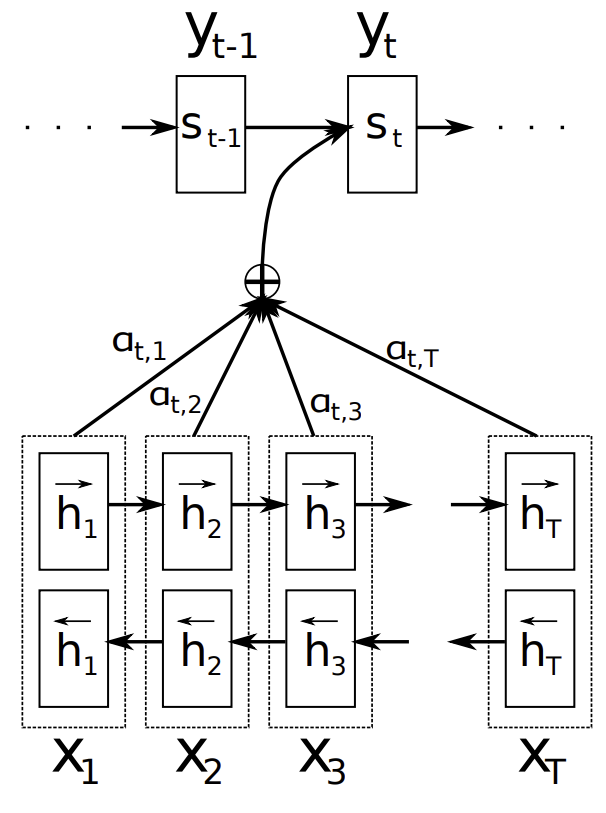
하지만 인코더-디코더 아키텍처도 여전히 몇 가지 문제가 있었습니다. 대표적인 문제가 정보 병목(Information Bottleneck)입니다. 이 구조는 입력 시퀀스의 길이와 관계 없이 모든 정보를 고정된 차원의 벡터에 압축해야 합니다. 그러다 보면, 입력 시퀀스가 갖는 정보의 일부가 손실되는 문제가 발생합니다. 비유를 들자면, 상자의 크기보다 큰 물건을 상자에 억지로 넣으려다 물건의 일부가 훼손되는 것과 같은 경우이죠. 그래서 제안된 방법이 바로 어텐션(Attention) 메커니즘입니다.
Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014) 논문에서는 매번 전체 문장을 압축하는 대신, 출력을 생성할 때는 맥락에 따라 특정 범위의 단어에만 집중하자는 아이디어를 제안했습니다. 이런 방법을 사용하면 입력의 길이와 관계없이 모든 정보를 정해진 공간에 억지로 압축하는 대신, 항상 일정한 정보만을 표현하면 되었기 때문에 정보 병목 문제를 해결할 수 있었습니다. |
|
|
시퀀스 투 시퀀스 구조와 어텐션 메커니즘은 모두 기존의 방법론이 갖던 문제를 하나씩 해결했지만, 여전히 해결하지 못한 문제가 남아있었습니다. 이 둘은 모두 주어진 입력을 처리하는 방식만을 변형한 것일 뿐, 입력을 처리하기 위해서는 여전히 LSTM, GRU와 같은 RNN 기반의 레이어를 사용했습니다.
RNN이 입력을 순차적으로 처리한다는 특징은 두 가지 문제를 갖습니다. 먼저 초기에 얻은 정보를 뒤로 갈수록 잊게 된다는 것입니다. 어텐션 메커니즘은 항상 일정한 양의 정보를 저장하도록 하여 이런 문제를 완화했지만, 그럼에도 불구하고 나중에 얻은 정보가 더 많이 유지되는 건 변하지 않습니다.
최신 정보는 초기에 얻은 정보에 비해 출력과의 거리가 상대적으로 가까울 것이기 때문에 분포 가설에 의하면 이는 큰 문제가 되지 않을 수 있습니다. 하지만 언어의 복잡성을 생각했을 때, 분포 가설이 통용되지 않는 상황도 분명히 존재할 것이며, 이는 언어 모델의 한계로 작용합니다. 이러한 사실은 서로 멀리 떨어져 있는 단어 간의 관계를 제대로 이해하지 못한다는 장기 의존성(Long Term Dependency) 문제를 낳습니다.
두 번째 문제는 병렬 처리 문제입니다. RNN은 단어를 순차적(Sequential)으로 처리합니다. 따라서 문장의 길이가 길어질수록, 언어 모델의 구조가 복잡해질수록 처리 시간이 길어집니다. 현대 딥러닝의 발전이 가능했던 여러 이유 중 하나가 바로 GPU에 의한 병렬 처리가 가능하다는 점인데, 병렬 처리가 불가능하다는 것은 그 자체가 치명적인 한계로 작용합니다. |
|
|
드디어 다시 트랜스포머로 돌아왔는데요, 트랜스포머는 RNN 자체를 사용하지 않음으로써 앞서 언급한 모든 문제를 해결했습니다. 트랜스포머는 RNN 대신 쿼리, 키, 값(Query, Key, Value)으로 구성된 어텐션 레이어를 사용하는데, 셋의 실체는 단순한 선형 레이어입니다. 이 레이어는 병렬 처리가 가능하다는 장점이 있지만, 한 가지 문제가 있긴 합니다. 바로 단어 간의 순서를 전혀 고려하지 않는다는 점입니다. 하지만 트랜스포머는 위치 인코딩(Positional Encoding)이라는 개념을 도입하여 이 문제마저 해결했습니다. |
|
|
트랜스포머 아키텍처
출처: Attention Is All You Need (Vaswani et al., 2017)
결국 트랜스포머는 위치 인코딩을 결합한 선형 레이어를 기반으로 하는 어텐션 메커니즘을 채용하여, 입력 전체를 한 번에 처리하는 병렬성을 확보했습니다. 그와 동시에 이전의 어텐션 메커니즘이 단어의 의미를 이해할 때, 특정 범위에만 집중했다면 트랜스포머는 모든 단어와의 관계를 고려하여 장기 의존성 문제마저 해결했습니다. 정리하면 기존의 언어 모델이 갖는 병렬 처리 불가능, 장기 의존성 학습 문제를 한 번에 없애버린 것이죠.
기존의 문제를 모두 해결한 트랜스포머는 곧 확장이 가능하다는 사실이 발견되었습니다. 과거의 언어 모델은 자체적인 한계를 갖고 있었기 때문에 크기를 키워도 성능에 한계가 있었습니다. 반면에 트랜스포머는 그런 문제를 해결했기 때문에 규모가 커짐에 따라 언어의 복잡성을 더 잘 이해하게 되었고, 마침내 지금과 같이 거대 언어 모델(Large Language Model, LLM)이라 불리는 수준까지 이르게 된 것입니다. |
|
|
트랜스포머는 발표된 이후 분야를 막론하고 현재까지 가장 널리 사용되는 아키텍처가 되었습니다. 처음에는 자연어 처리에서 적극적으로 활용이 되었지만, 확장 가능성(Scalability)을 비롯한 여러 장점을 인정받고 이미지, 오디오와 같은 다양한 모달리티 처리에도 사용되고 있습니다. 하지만 결점이 없어 보이는 트랜스포머에도 분명한 한계가 있습니다. 단점이 없이 완벽한 모델은 적어도 현재까지는 없습니다. 트랜스포머의 가장 큰 문제는 연산 효율입니다.
언어 모델에 대한 최신 연구가 규모 확장을 포기하고, 오히려 작은 모델에서 성능을 효율적으로 끌어올리는 방법에 집중하고 있는 이유도 이런 데 있습니다. 트랜스포머도 어딘가 문제가 있다는 사실을 모두 알고 있기 때문이죠. 하지만 지금까지 쌓아온 연구가 모두 트랜스포머를 기반으로 하고 있기 때문에 그 그늘에서 벗어나기는 쉽지 않습니다. 그럼에도 불구하고 언어 모델의 구조에 새로운 혁신이 일어난다면, 그 시작을 알릴 연구는 과연 무엇이 될까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|