모델을 경량화한 1.58비트 LLM을 알아봅니다. # 64 위클리 딥 다이브 | 2024년 11월 6일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 컴퓨터가 숫자를 표현하는 방법을 요약했습니다.
- 비트 양자화 개념을 정리했습니다.
- BitNet b1.58의 원리와 특징을 소개했습니다.
|
|
|
안녕하세요, 에디터 배니입니다.
최근 AI 열풍이 한층 꺾인 느낌입니다. 이미 LLM 성능이 너무 뛰어나서 포화 상태에 이르렀기에 그렇다고 볼 수 있겠죠. 최근 연구는 이보다 더 성능을 높이기보다 에너지와 비용을 절약할 수 있는 방법에 초점을 맞추고 있는 듯합니다. 즉, 같은 성능을 보이더라도 더 가벼운 모델을 개발하는 것이죠. 지난 저희 뉴스레터(🔗 링크)에서도 이와 유사한 연구를 소개하기도 했습니다.
여기서 모델이 가볍다는 말은 일반적으로 파라미터 수가 경우를 말합니다. 아마 인공지능에 조금이라도 관심 있으신 분들은 모델 뒤에 7B, 13B 등의 숫자가 붙는 것을 보신 적이 있을 것입니다. 일례로, Meta가 개발한 오픈 소스 언어 모델인 LLaMA도 LLaMA-7B / LLaMa-13B 등으로 구분되어 있죠. 이 B는 Billion으로 7B의 경우는 70억이고 이 숫자가 모델의 파라미터 수를 의미합니다. 그리고 파라미터가 많을수록 모델 성능이 개선된다는 연구가 계속 발표되어 왔습니다.
물론 파라미터 수를 줄이면 그 자체로 모델의 용량도 줄어들 것입니다. 하지만 파라미터 수가 아니라 하나의 값을 표현하는 단위를 바꾸는 방법도 있습니다. 이는 컴퓨터에서 숫자를 표시하는 단위인 비트(Bit)와 큰 관련이 있는데요. 오늘은 비트 이야기를 시작으로 최근 발표된 1.58비트 모델에 대해 소개합니다. |
|
|
비트(Bit)는 Binary Digit의 줄임말로 정보의 나타내는 최소 단위이자 컴퓨터가 처리하는 이산 데이터의 양을 표기하는 단위입니다. 즉, 0과 1로 표현하는 방식을 의미하죠. 1비트로는 0 또는 1을, 4비트로는 0000, 0001…1111과 같이 표시할 수 있습니다.
보통 딥러닝 파라미터로 활용하는 값은 32비트의 소수점으로 표현합니다. 사실 32비트로도 숫자를 표현할 수 있는 방법은 다양합니다. 간단하게 8비트로 예를 들면 우리는 0000 0011을 2+1인 3으로 생각합니다. 하지만 소수점을 표현한다고 하면 어떻게 해야 할까요? 일부 비트는 소수점을 표시하는 데 활용할 수 있고, 나머지는 정수 부분을 표현하는 데 활용할 수 있습니다.
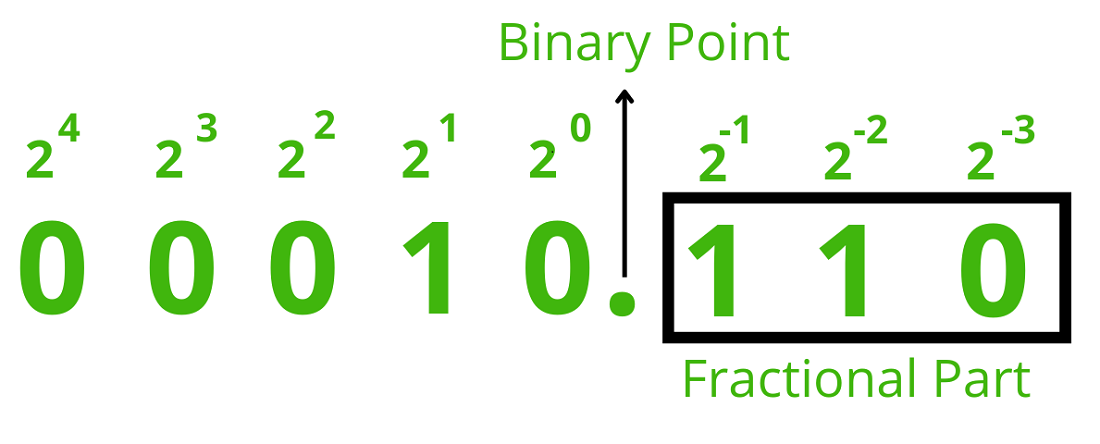
8비트를 0001 0110이라는 표현에서 0001 0.110과 같이 가상의 점이 있다고 생각하고 점 아랫부분은 소수 부분으로 계산합니다. 즉, 아래의 예시는 2 + 1/2 + 1/4 = 2.75로 해석할 수 있겠죠. 이와 같이 고정된 위치에 소수점이 있다고 가정하고 이진 표현을 해석하는 방법을 고정 소수점 표현(Fixed Point Representation)이라고 합니다. |
|
|
출처: GeeksforGeeks <Fixed Point Representation>
하지만 이 방식은 소수점 위치가 고정되었기 때문에 수를 표현하는 데 범위에 한계가 클 수밖에 없습니다. 이에 조금 더 유연한 방식으로 소수점 위치를 표현하기 위해서 부동 소수점 표현(Floating Point Representation) 방식을 고안합니다. ‘부동’이라는 말이 움직이지 않는다는 것이 아니라 반대로 소수점이 고정되지 않고 ‘떠다니는(浮動; Floating)’ 방식을 의미합니다.
고정 소수점 방식에 비해서 부동 소수점 방식은 바로 이해하기 쉽지 않을 수도 있는데요. 그래도 한 번만 차근히 이해해봅시다. 부동 소수점은 총 3가지로 비트를 역할로 구분합니다. |
|
|
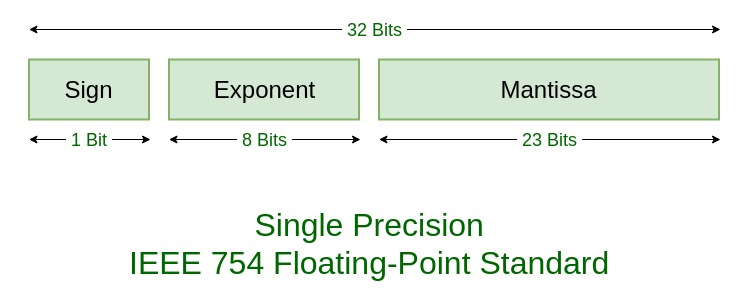
출처: GeeksforGeeks <IEEE Standard 754 Floating Point Numbers>
먼저, 양수와 음수를 구분하는 Sign 비트입니다. Sign 비트는 0이면 양수, 1이면 음수를 나타냅니다.
다음으로 Exponent(지수) 부분은 소수점의 위치를 결정하는 역할을 합니다.
마지막으로 Mantissa(가수)는 숫자의 정밀도를 담당하며, 실제 수의 소수 부분을 표현합니다. IEEE 754 표준에서는 가수를 1.xxxx의 형식으로 가정하기 때문에 가수 부분에서는 소수 부분만 저장합니다.
이론적으로는 조금 더 복잡하지만 원리를 쉬운 이해하기 위한 예시를 들어보겠습니다. 이진수 10.75를 IEEE 754 단정밀도로 변환하면 10.75는 이진수로 1010.11로 나타낼 수 있습니다. 이를 IEEE 754 방식으로 정규화하면 1.01011 × 2^3이 됩니다. 따라서 지수는 3, 가수는 01011이 됩니다. 가수가 101011이 아닌 이유는 앞서 말한 것처럼 1.xxxx의 형식을 가정하기 때문입니다. 이와 같이 부동 소수점 방식은 소수점의 위치를 고정하지 않고 자유롭게 이동시킬 수 있어, 훨씬 더 넓은 범위의 실수를 표현할 수 있습니다.
이때 Exponent, Mantissa 비트 개수를 조절해 필요에 따라 표현 범위를 다르게 가져갈 수도 있습니다. 하지만 모든 컴퓨터가 동일한 값을 동일하게 연산하기 위해서는 이를 통일해야 하죠. 이에 국제 표준으로 Exponent를 8비트, Mantissa를 23비트로 표현한 것이 IEEE 754입니다. 그리고 이렇게 표현한 부동 소수점 32비트 Single Precision(단정도)라 부릅니다. 딥러닝 분야에서는 FP32로 표현합니다. |
|
|
그렇다면 부동 소수점 16비트는 FP16으로 표기하고, Exponent와 Mantissa의 영역이 상대적으로 줄어들면서 수의 표현 범위와 정밀도가 달라진다는 것을 알 수 있는데요. 이렇듯 비트 수를 32비트에서 16비트로 조정한다면 정밀도는 떨어지지만 모델이 가벼워지겠죠. 그럼 얼마나 가벼워지는지 알아봅시다.
8비트는 1바이트(Byte)입니다. 즉, 32비트는 4바이트라고 할 수 있죠. 7B 모델이라면 4 * 70B인 280억 바이트로 표현 가능합니다. 엄청 큰 숫자 같지만 실제로는 26GB 정도에 해당합니다. 7B 모델이 32비트로 표현된다면 이 정도 용량을 차지한다고 보면 됩니다. 동일한 모델을 16비트로 표현한다면 그 절반인 13GB로, 8비트로 표현하다면 그것의 또 절반으로 줄어듭니다.
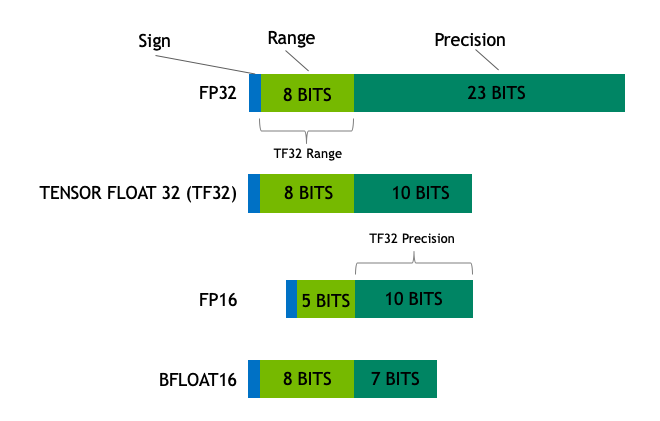
물론 함부로 양자화해서는 안 됩니다. 성능을 유지하면서 양자화하는 것이 중요하죠. 다르게 말하면 어느 정도 정밀도를 유지해야 하죠. 이를 위해서 표현하는 방법을 국제 표준과 다르게 설정하기도 하는데요. 다음 그림에서는 명칭별로 비트 수와 표현 방법에 따라 어떻게 달라지는지 보여줍니다. TF32의 경우에는 FP32의 범위(Range)와 FP16의 정밀도(Precision)를 가지고 있다고 볼 수 있겠네요. |
|
|
지난달 21일, Microsoft에서 흥미로운 기술 보고서를 발표했습니다. 1-bit LLM인 BitNet b1.58을 활용한 추론 성능에 관한 내용인데요. BitNet b1.58은 올해 2월 MS가 개발한 모델입니다. 결과를 살펴보기 전에, 1비트도 아니고 1.58비트는 무엇인지 이해해봅시다.
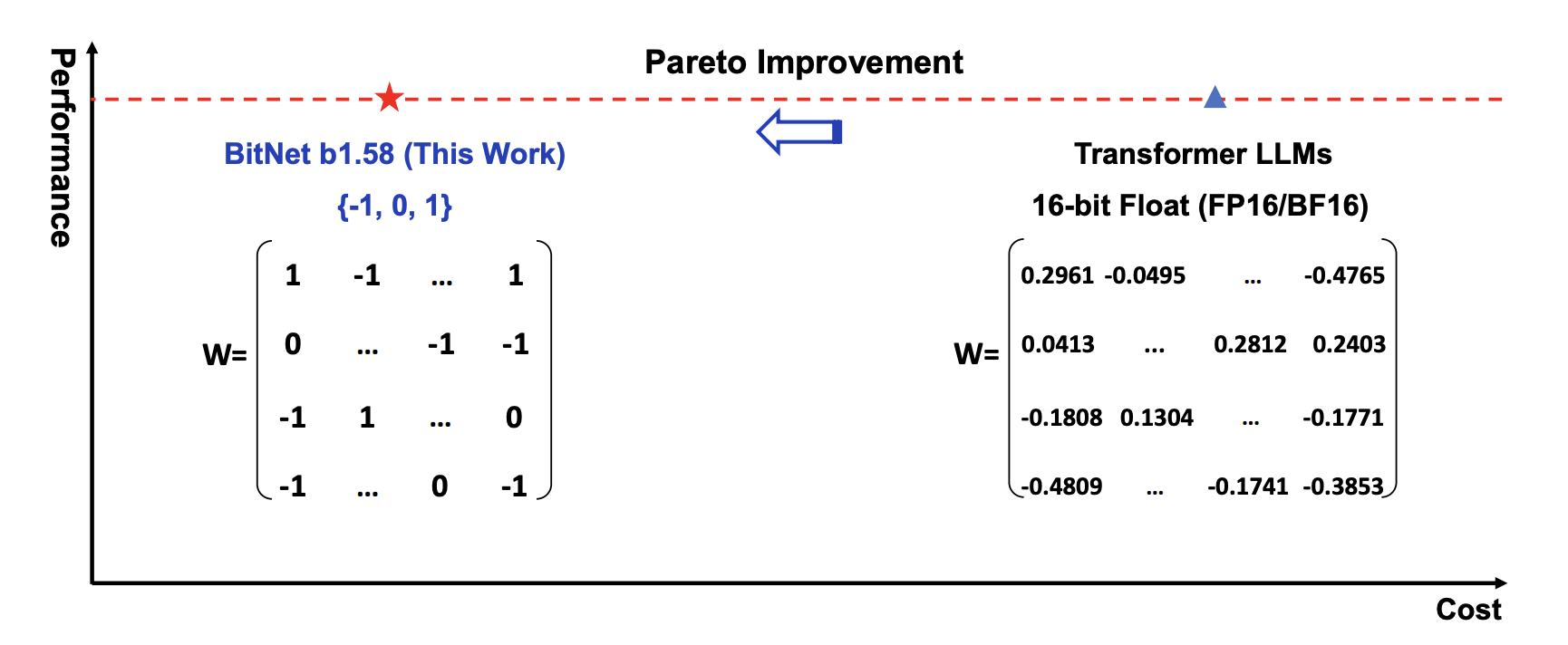
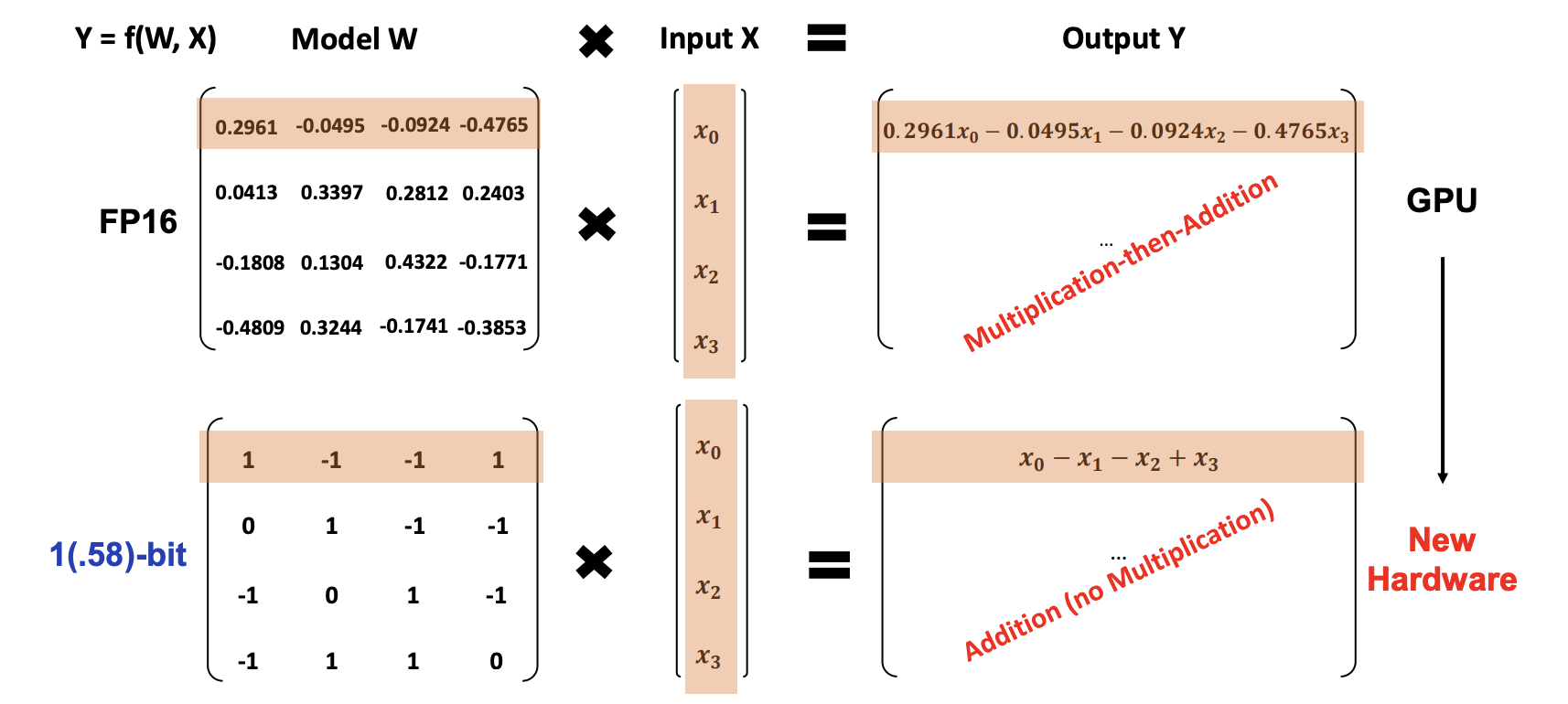
앞서 1비트는 0과 1로 표현되는 정보의 단위라고 말씀드렸습니다. 이는 정보량을 계산하는 방식에 따라 밑이 2인 로그(Log)를 씌워서 계산한 결과인데요. 0과 1이라는 두 가지 정보로 값을 표현할 때는 1비트라고 할 수 있죠. 하지만 이번 논문에서는 {-1, 0, 1}이라는 3가지 정보로 하나의 값을 표현합니다. 즉, 1비트가 아니라 log2_3인 1.58비트로 표현하는 것입니다.
처음부터 1.58비트를 시도한 것은 아닙니다. 지난해 10월 논문에는 0과 1, 즉 1비트만으로 표현하고자 했는데요. 당시에는 성능 그 자체보다는 에너지 효율성에 집중했습니다. 그러나 이번에는 0을 추가하면서 준수한 성능까지 보유하게 됐는데요. 이번 논문이 나오기 전까지는 아직 실제 성능은 보장하기 어렵다는 의견이 있었습니다. 그러나 이번 연구에서 성능을 확실히 보여줬습니다. |
|
|
여기서는 성능보다는 변환되는 과정을 살펴보면 좋을 것 같습니다. 기존 16비트로 학습된 모델을 {-1, 0, 1} 중 하나로 매핑하여 변환했는데요. 변환하는 방법은 절댓값의 평균을 계산한 다음 이를 반올림하는 형식으로 역시 비교적 간단합니다. 이렇게 모델링했을 때 장점이 매우 뚜렷합니다. |
|
|
{-1, 0, 1}밖에 없기 때문에 사실상 곱셈(Multiplication) 연산 없이 덧셈(Addition) 연산만으로 표현이 가능합니다. 기존에 많은 모델들이 행렬곱(Matrix Multiplication) 연산에서 많은 하드웨어 자원을 필요로 했다는 점을 고려할 때, 덧셈 연산에 맞는 하드웨어가 제안된다면 새로운 패러다임으로 전환될 수 있다는 점을 암시하기도 합니다. |
|
|
이렇게 모델을 경량화하고 에너지 효율적인 모델을 개발하기 위해 모델을 경량화하는 방법의 일환으로 비트 양자화와 1 비트 모델링 방법을 소개했습니다. 엄밀히 따지면 비트 양자화 방식과 1.58 비트 모델링 방법은 개념적으로 다릅니다. 그럼에도 MS 연구진은 해당 모델을 FP16 모델과 대응시키며 구현이 가능하도록 만들었고 높은 성능으로 입증했습니다. 앞으로는 이와 같은 모델링 방법이 AI 모델 개발에 새 지평을 열지 않을까 기대됩니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|