LLM 시대를 열게 된 그 시작, Scaling Law에 대해 설명합니다. # 53 위클리 딥 다이브 | 2024년 8월 21일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 대규모 언어 모델의 Scaling Law에 대해 소개합니다.
- Scaling Law를 바탕으로 LLM이 등장한 배경을 설명합니다.
- Scaling Law의 의의와 현재 언어 모델 연구 트렌드를 정리합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
연일 쏟아지는 대규모 언어 모델(Large Language Model, LLM) 관련 뉴스에서, 거의 항상 빠지지 않고 등장하는 키워드가 있습니다. LLM의 규모와 벤치마크 점수인데요, 각각 파라미터 개수를 기준으로 언어 모델이 얼마나 큰지, 특정한 기준에서 성능이 어떠한지를 의미합니다. 이런 표현을 자주 접하다 보니, 언어 모델의 작동 원리를 잘 알지 못해도 모델의 규모가 크면 성능이 좋을 것이라는 어설픈 예측쯤은 누구나 할 수 있습니다. 조금 더 나아가면, 단순히 모델 규모가 아니더라도, 학습에 사용하는 데이터나 하드웨어 자원이 더 많이 투자되어도 그렇겠죠. |
|
|
One might expect language modeling performance depend on model architecture, the size of neural models, the computing power used to train them, and the data available for this training process.
언어 모델의 성능은 모델 아키텍처, 모델의 크기, 학습에 사용되는 데이터와 컴퓨팅 성능에 따라 달라질 것으로 예상할 수 있습니다. |
|
|
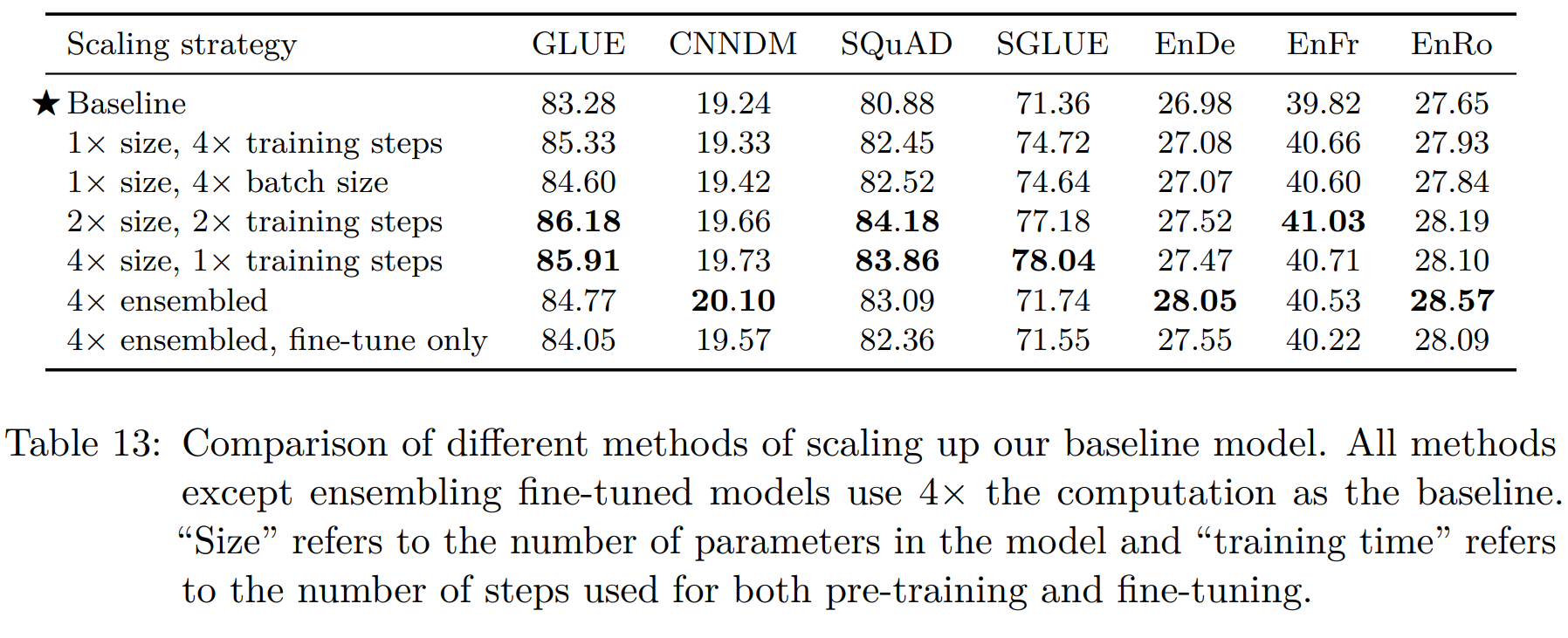
아래 그림은 이제 너무나 흔하고 유명한 그림이 되었는데, 이는 논문의 실험 결과를 단적으로 매우 잘 보여주는 그림입니다. 핵심은 학습에 사용하는 연산량(Compute), 데이터셋의 규모(Dataset Size), 모델의 규모(Parameter)를 늘렸을 때 학습 손실(Training Loss)이 계속해서 감소한다는 것입니다. 물론 세 가지 요인이 완전히 독립적으로 영향을 미치진 않겠지만, 이 논문의 진정한 의의는 모두의 상상에 그친 가설을 실제로 증명해 냈다는 데 있습니다. |
|
|
연산량, 데이터셋 및 모델의 규모에 따른 학습 손실
출처 : Scaling Laws for Neural Language Models (Kaplan et al., 2020)
이 논문도 장장 30여 페이지에 걸쳐 여러 요소가 딥러닝 모델의 성능에 미치는 영향을 면밀히 분석하고 있는데, 그 내용을 조금 더 살펴보겠습니다. 먼저 모델의 규모와 학습 데이터의 양은 각각 증가할수록 성능은 좋아지지만, 성능이 더 이상 증가하지 않는 구간에 들어서게 되면 둘 모두의 양을 늘려주어야 합니다. 즉, 모델의 규모와 학습 데이터의 크기의 균형이 중요합니다. 작은 모델이 너무 다양한 지식을 학습하는 것도, 큰 모델이 너무 적은 데이터를 학습하는 것도 비효율적이겠죠.
다음으로 모델의 아키텍처를 트랜스포머로 고정했을 때, 파라미터의 개수(모델의 규모)가 일정하다면, 모델의 넓이나 깊이는 성능에 영향을 크게 미치지 않습니다. 모델의 넓이는 입력된 데이터를 벡터로 표현하는 데 사용하는 차원의 크기를 말합니다. 예를 들어 언어 모델이 입력받은 텍스트를 768차원의 벡터로 표현한다면, 768이 모델의 넓이가 됩니다. 그리고 모델의 깊이는 내부에 존재하는 레이어의 개수를 말합니다. 결국 전체 파라미터의 개수가 동일하다면, 넓이와 깊이를 각각 적당히 늘리고 줄여도 성능 자체는 거의 일정하다는 것이죠.
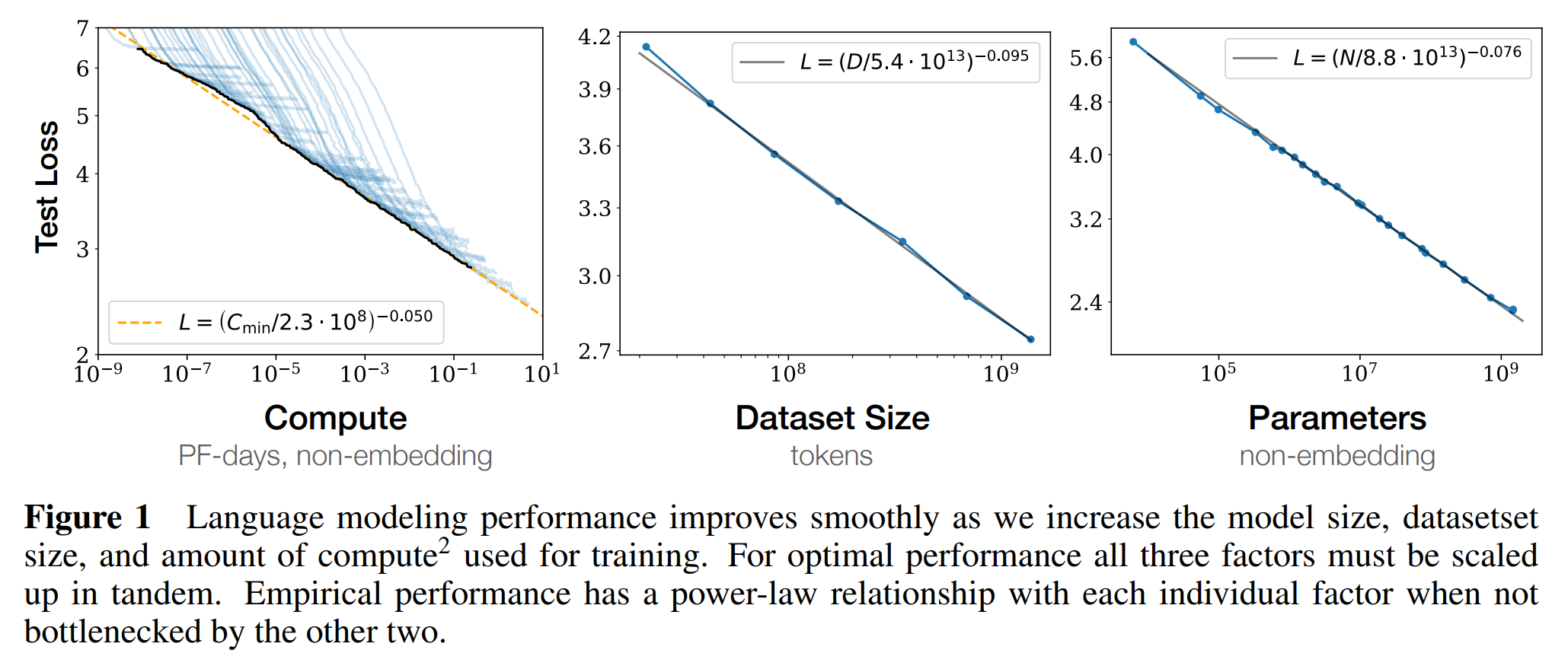
마지막으로 규모가 큰 모델은 작은 모델보다 샘플 효율성(Sample Efficiency)이 좋습니다. 샘플 효율성이 높다는 것은 같은 양의 데이터를 학습해도 더 뛰어난 성능을 보인다는 것입니다. 아래는 다양한 크기의 모델이 학습한 토큰에 따른 테스트 손실(Test Loss)을 나타낸 그래프입니다. 실제로 규모가 큰 모델일수록 적은 데이터를 학습해도 더 나은 성능을 보임을 확인할 수 있습니다.
|
|
|
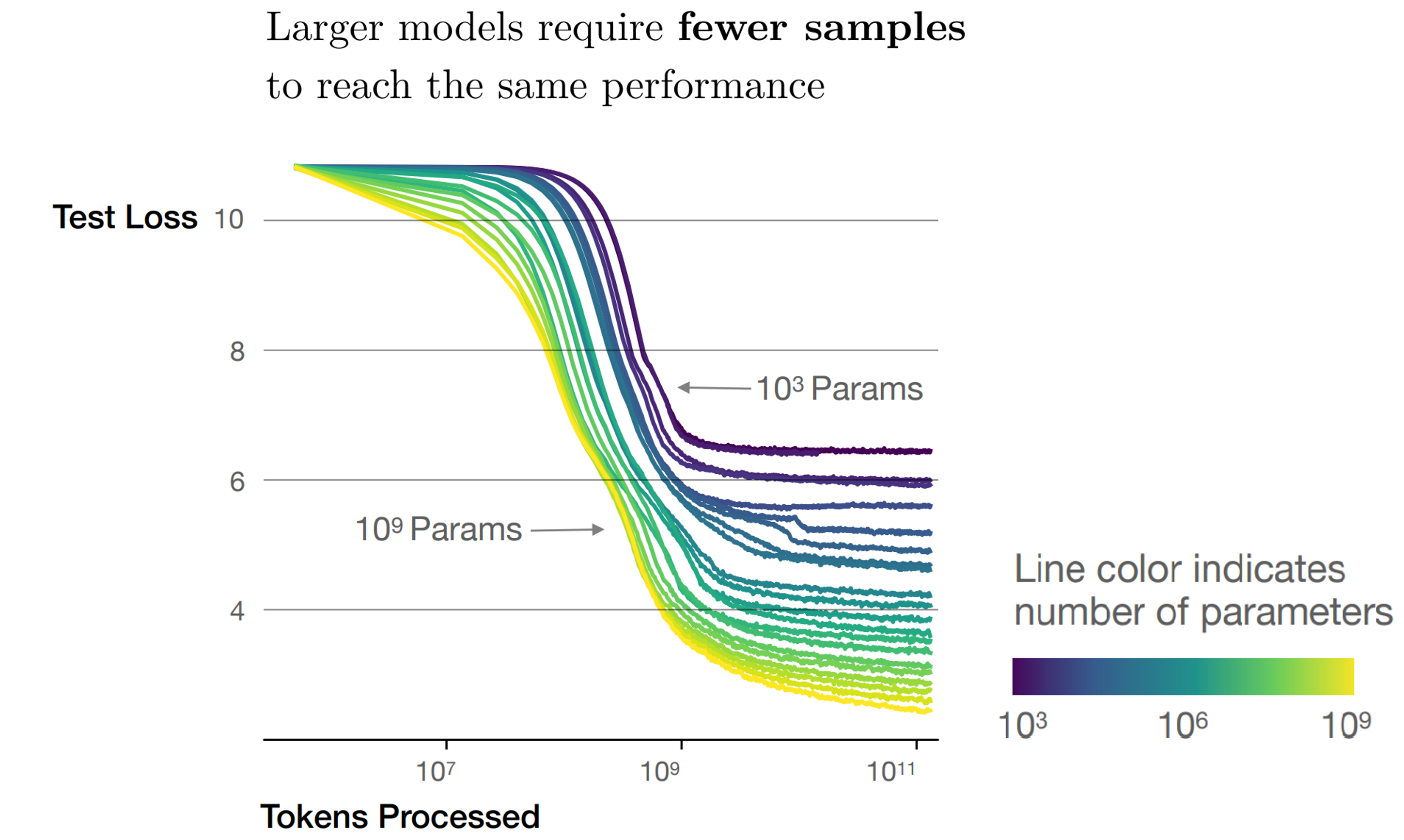
2020년 1월 Scaling Law를 발표한 OpenAI는 같은 해 5월 곧 전세계 언어 모델 연구 트렌드를 뒤바꿀 논문을 발표합니다. 바로 GPT-3를 소개하는 논문, Language Models are Few-Shot Learners (Brown et al., 2020)입니다. 이 논문에서 가장 눈에 띄는 점은 바로 GPT-3의 모델 규모입니다. GPT-3가 등장하기 전까지만 하더라도 언어 모델의 규모는 최대 10B 내외였습니다. 그런데 GPT-3는 그보다 10배 이상 큰 175B의 규모를 자랑했죠. 당시 언어 모델 규모 트렌드를 보면, 정말 뜬금없는 수치가 아닐 수 없습니다. 그런데 OpenAI의 이런 과감한 실험은 무모한 도전은 아니었습니다. |
|
|
언어 모델의 규모 트렌드
출처 : 래블업 블로그, 일부 수정 (2023)
그들은 체계적인 실험을 통해 Scaling Law가 유효함을 증명했고, 이를 근거로 GPT-3라는 모델을 만들게 된 것입니다. Scaling Law의 의의는 바로 여기에 있습니다. 이 연구 덕분에 LLM이 탄생했다고 봐도 과언이 아니죠. 실제로 언어 모델 앞에 거대하다는 형용사가 붙어 LLM(Large Language Model)이라는 용어가 등장한 것도 GPT-3가 세상에 모습을 드러낸 이후입니다.
OpenAI는 언어 모델의 규모 확장으로 큰 성공을 거두고, 문맥 내 학습(In-Context Learning), 프롬프트 엔지니어링(Prompt Engineering) 등 새로운 개념이 탄생하는 데 결정적인 기여를 하면서 언어 모델 연구의 새로운 지평을 열었습니다. 드디어 LLM의 시대가 도래한 것입니다.
|
|
|
언어 모델의 규모가 계속해서 커지고 그에 따라 성능도 좋아졌습니다. 기계에는 과분할 정도의 수식어인 “인간 수준에 준하는”이라는 표현도 사용되며 창발(Emergence), 추론(Reasoning), 계획(Planning) 등 과거엔 상상조차 하지 못한 능력을 인공지능이 갖게 되었습니다.
찬란한 황금기를 맞이한 LLM 연구는 곧 현실적인 문제에 부딪히게 되는데, 바로 실용성 문제입니다. 언어 모델의 규모가 과도하게 커지면서, 이제 이 분야의 연구는 더 이상 연구자들의 것이 아닌 거대 기업의 것이 되어버렸습니다. 모델을 학습하고 운용하는 데 필요한 자원이 천문학적으로 늘어나며, 이제는 반대로 모델의 규모를 작게 만들 필요가 생겼습니다.
최근에는 LLM 학습의 연산 효율성을 높이려는 시도인 PEFT(Parameter Efficient Fine-Tuning), 모델의 규모를 줄이려는 시도의 일종인 양자화(Quantization)와 같은 연구가 활발하게 이뤄지고 있습니다. 그러면서 이제는 이름부터 모순적인 sLLM(small Large Language Model)이라는 용어까지 만들어졌습니다. 대규모 언어 모델이긴 한데, 많은 사람들이 무리 없이 이용하기에는 충분히 작은 모델이라는 의미이죠. |
|
|
기껏 크기를 키워 성능을 한층 높인 언어 모델을 다시 작게 만든다니, 남들이 보기엔 이상하게 보일지도 모릅니다. Scaling Law는 결국 인공지능 연구자들이 허송세월하게 만든 것일까요? 당연히 그렇진 않습니다. 사실 모델의 규모를 작게 하려는 시도는 이미 과거에도 존재했습니다. 하지만 당시에 사용되던 하드웨어의 성능은 현대의 것에 미치지 못했고, 이런 환경에서 연구를 지속하는 방법을 찾는 데 중점이 맞춰져 있었습니다. 즉, 모델의 성능보다는 하드웨어의 성능이 문제였죠.
하지만 현대의 연구는 이미 뛰어난 성능을 갖춘 모델을 모든 사람이 사용할 수 있도록 하는 데 중점을 두고 있습니다. LLM의 시대가 도래하며, 인공지능은 가능성을 충분히 입증했고, 이제는 생활 곳곳에까지 파고들어 우리 모두의 삶을 편하게 만들어주고 있습니다. 하지만 연구자들은 우리가 더욱 편리하게 다양한 일들을 처리할 수 있도록, LLM을 소형화하기 위해 노력하고 있는 것이죠.
결국 최신 연구 트렌드가 어떻게 되든, OpenAI는 Scaling Law를 통해 인공지능 연구 자체의 전환점을 가져왔습니다. GPT-4, GPT-4o를 비롯해 여러 소식을 전할 때마다 세상을 놀라게 하는 그들은 사실 보이지 않는 다양한 시도를 통해 연구의 흐름 자체를 주도해왔던 것입니다. OpenAI는 또 어떤 놀라운 통찰을 통해, 인공지능 시대의 새로운 장을 열게 될까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|