언어 모델의 환각을 지식 그래프로 측정해봅니다. # 54 위클리 딥 다이브 | 2024년 8월 28일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 언어 모델에서 환각 현상이 무엇인지 설명합니다.
- 규모와 환각의 상관관계를 연구한 논문을 소개합니다.
- 환각을 탐지하기 위해 사용한 방법인 KG(Knowledge Graph)를 파헤쳐봅니다.
|
|
|
안녕하세요, 에디터 잭잭입니다.
언어 모델 연구에서 ‘환각’은 모델이 존재하지 않는 정보나 사실을 마치 실제로 존재하는 것처럼 생성하는 현상을 의미합니다. 예를 들어, 언어 모델이 질문에 대한 응답으로 잘못된 정보나 사실과 다르게 왜곡된 정보를 제공하는 현상을 말해요. 이런 현상은 모델이 학습한 데이터에서 유사한 패턴을 바탕으로 새로운 문장을 생성하지만, 확률에 기반하는 딥러닝 모델의 특징에 의해 사실과 다른 내용을 출력할 수도 있기 때문에 발생합니다. 환각은 언어 모델의 큰 문제 중 하나에요. 특히 의학적 조언이나 법률 자문과 같이 정확성, 신뢰성이 중요한 정보에 대해서는 더욱 민감하게 환각 여부를 평가해야 합니다.
생성 및 예측 능력의 급속한 발전에도 불구하고, 환각(Hallucinations)은 여전히 LLM에서 미지의 영역입니다. 연구자들은 모델 성능이 데이터셋과 모델 크기가 증가함에 따라 향상되는 '규모의 법칙'을 연구해 왔지만(Kaplan et al., 2020; Hoffmann et al., 2022), 규모가 환각에 미치는 영향은 아직 완전히 밝혀내지 못했어요. 이에 <Training Language Models on the Knowledge Grpah: Insights on Hallucinations and Their Detectability>(Hron et al., 2024) 의 연구진은 언어 모델의 규모와 환각 사이의 관계를 알아내고자 했어요. 둘 사이의 관계를 알아낸다면, 상황에 알맞게 규모를 조절하는 등의 맞춤형 설정이 가능해지니까요.
앞선 뉴스레터(🔗 #53 언어 모델 규모의 법칙)에서, 언어 모델의 규모에 대해 다음과 같이 언급했습니다. |
|
|
🗣LLM 규모의 법칙의 핵심은 학습에 사용하는 연산량(Compute), 데이터셋의 규모(Dataset Size), 모델의 규모(Parameter)를 늘렸을 때 학습 손실(Training Loss)이 계속해서 감소한다는 것입니다. |
|
|
오늘 소개하는 연구에서도 마찬가지로, 환각 ↔ 데이터셋의 규모, 환각 ↔ 모델의 규모 사이의 관계 모두를 다룹니다. 또한 데이터셋 규모가 같을 때, 학습량(Epoch)이 환각에 미치는 영향과 학습량이 같을 때 데이터셋의 규모가 환각에 미치는 영향까지 깊이 있게 알아보겠습니다. |
|
|
Problem: 환각에 대한 연구가 어려웠던 이유 |
|
|
환각을 탐지하고 평가하는 것도 물론 어렵지만, 환각에 대한 분석이 쉽지 않았던 가장 큰 이유는 모델이 학습 중에 어떤 정보를 접했는지 보통 알 수 없기 때문입니다. 이 정보를 모르는 상황에서는
1️⃣ 모델이 특정 사실을 학습하지 않았기 때문에 잘못된 정보를 생성한 것인지
2️⃣ 해당 사실을 학습했으나 이를 기억하지 못했는지
3️⃣ 모델이 학습 중에 잘못된 정보를 기억했기 때문에 잘못된 출력을 내는지
판단할 수 없습니다. 이 문제를 해결하기 위해서는 모델이 접하는 정보를 완벽하게 제어할 수 있는 구조를 가진 데이터(e.g., 지식 그래프)로 모델을 학습시켜야 할 필요가 있습니다. |
|
|
지식 그래프의 개념은 시맨틱 웹(Semantic Web)이 발전하면서 같이 등장했어요. 시맨틱 웹은 웹 상의 데이터를 인간이 아닌 기계도 이해할 수 있도록 구조화된 형태로 표현하고자 하는 비전에서 출발했습니다. 이를 위해, 웹의 데이터를 RDF(Resource Description Framework), OWL(Web Ontology Language) 등의 기술을 사용해 표현하고, 이를 토대로 의미 있는 관계를 정의하는 접근법이 제안됐습니다.
이후, 2012년 Google이 검색 엔진에 '지식 그래프'라는 용어를 사용하면서 이 개념이 대중적으로 알려졌으며, 이를 통해 사용자가 검색할 때 관련된 정보를 더 풍부하게 제공할 수 있었죠. 이때 사용되는 지식 그래프는 정보와 개념 간의 관계를 그래프 구조로 표현한 데이터베이스입니다. 그래프는 개별 개체를 나타내는 노드(Node)와 그들 간의 관계인 엣지(Edge)로 구성되어 있어요. |
|
|
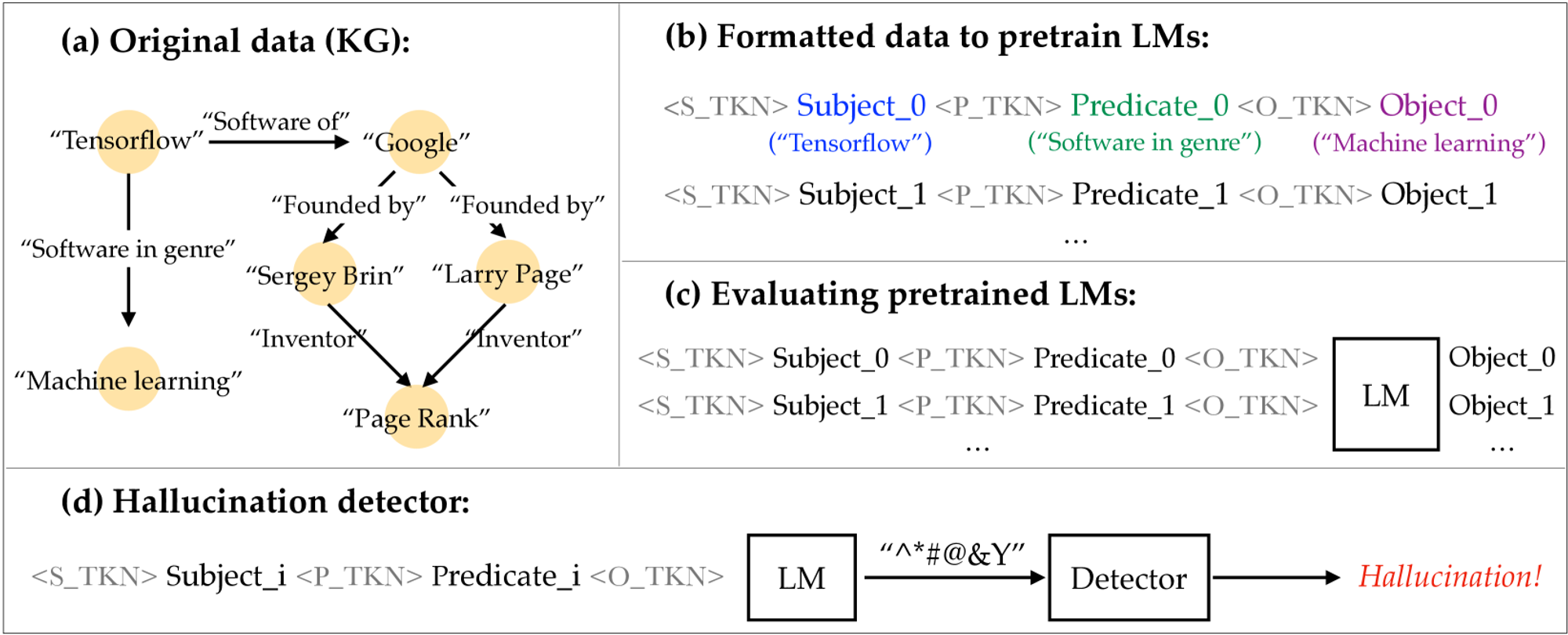
[그림 1] Data and the training Pipeline
출처 : Training Language Models on the Knowledge Grpah: Insights on Hallucinations and Their Detectability (HRON, Jiri, et al., 2024)
[그림 1]의 (a)가 오늘 살펴봐야 할 지식 그래프입니다. 이 지식 그래프는 [주어, 술어, 목적어] 삼중항(Triplet) 형태로 이루어져 있어요. “Tensorflow(주어) → Software in genre(술어)→ Machine learning(목적어)” 와 같이 주어와 목적어를 나타내는 노드들이 술어(화살표)로 연결된 형태의 지식 그래프(KG)로 존재합니다.
(b)에서 나타나는 <S_TKN>, <P_TKN>, 와 <O_TKN>은 각각 주어, 술어, 그리고 목적어를 나타내는 특별한 토큰이에요. 이렇게 구성된 삼중항을 문자열로 연결하여 언어 모델을 학습시키는 것이죠. 평가할 때는 주어와 술어로 모델을 프롬프트로 입력하고, 모델이 목적어를 완성하도록 합니다. 예측이 학습 데이터에서 주어진 주어-술어 쌍과 함께 나타나는 어떤 목적어와도 일치하지 않을 경우, 해당 생성은 환각으로 간주돼요!
이와 같이 지식 그래프는 언어 모델이 생성한 사실이 데이터셋에 실제로 존재하는지 여부를 간단하게 조회할 수 있으므로, 환각에 대한 정량적 측정을 가능하게 합니다. 언어 모델이 훈련 데이터를 얼마나 잘못 표현하는지, 그리고 이 현상이 규모에 따라 어떻게 달라지는지를 연구할 수 있어요.
|
|
|
🗣환각에는 사실적 환각, 합성적 환각, 관계적 환각, 구조적 환각 등이 있으며 본 연구는 훈련 데이터셋에 올바른 답이 그대로 등장하는 환각에만 집중하여 연구합니다.
환각과 관련해 더 자세한 내용을 알고싶으면 아래 논문들을 추천드려요.
- Cognitive Mirage: A Review of Hallucinations in Large Language Models, (Ye, Hongbin, et al., 2023)
- A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, (Tonmoy, S. M., et al., 2024)
- A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, (Huang, Lei, et al., 2023)
|
|
|
규모의 법칙은 언어 모델의 교차 엔트로피(Cross Entropy) 손실이 모델 크기와 학습 데이터셋 크기의 거듭제곱 법칙에 따라 감소하는 현상입니다(Kaplan et al., 2020; Hoffmann et al., 2022). 교차 엔트로피가 모델 예측의 정확도와 관련있기 때문에, 연구자들은 언어 모델의 규모가 커질수록 환각률도 유사한 경향을 따르는지 궁금증을 가졌습니다. |
|
|
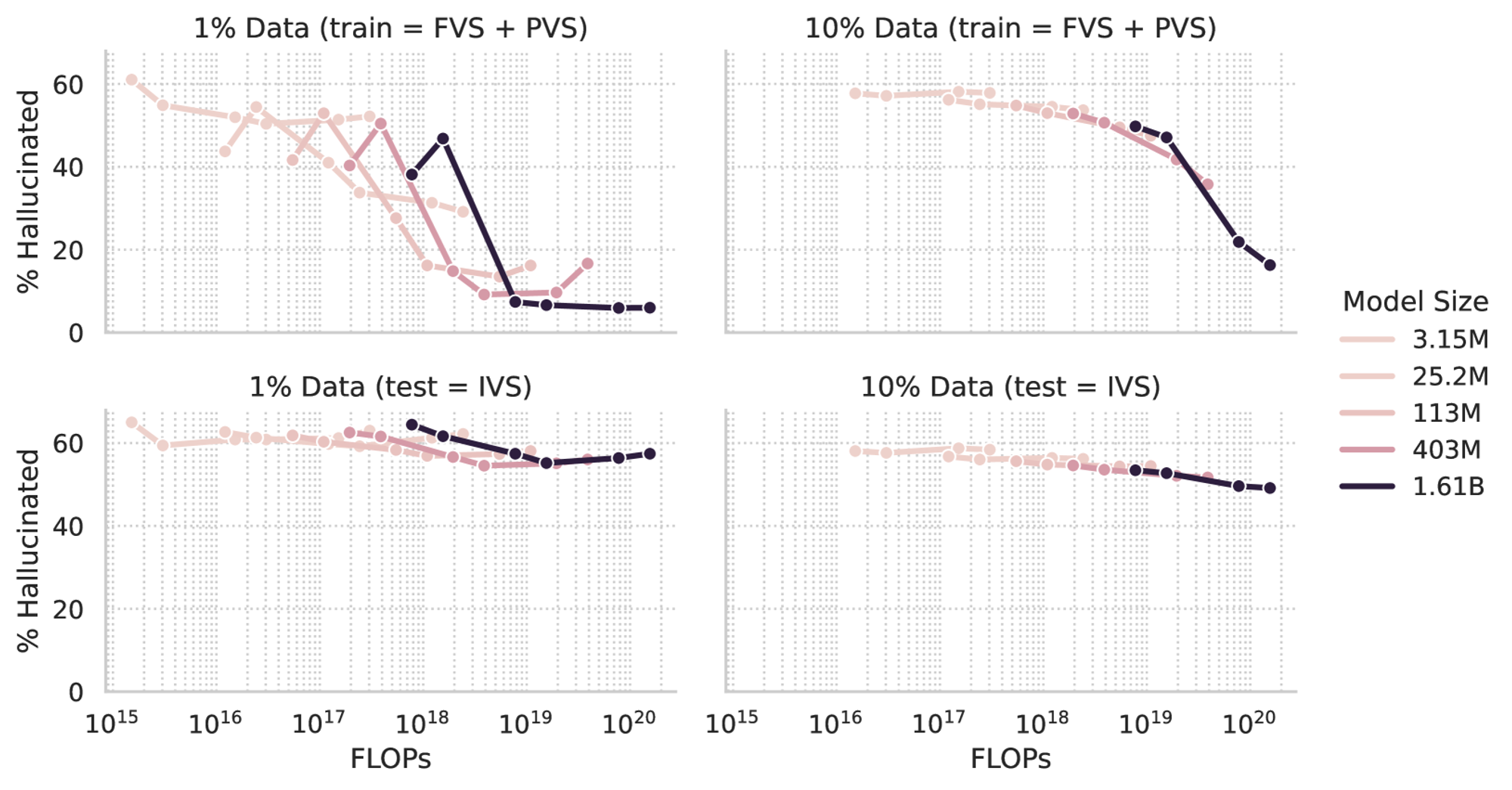
[그림 2] Hallucination rate per LM training FLOPs
출처 : Training Language Models on the Knowledge Grpah: Insights on Hallucinations and Their Detectability (Hron et al., 2024)
하지만 [그림 2]는 그렇지 않다는 것을 보여줍니다. 고정된 데이터셋 크기에서 더 크고, 더 오래 학습된 모델은 환각을 덜 일으키는 경향이 있지만, 데이터셋 크기를 늘리면(상단 왼쪽 vs. 상단 오른쪽) 환각률이 낮아지기보다는 오히려 높아집니다. 고정된 데이터셋에서는 더 크고 더 오래 훈련된 언어 모델이 환각률이 낮은 모습 또한 확인할 수 있어요. 정리하자면, 아래와 같습니다.
- 고정된 데이터셋에서 더 크고 더 오래 훈련된 언어 모델이 환각을 덜 일으킨다.
- 동일한 에포크만큼 훈련되었을 때, 더 큰 규모의 데이터셋이 환각을 더 일으킨다.
이러한 맥락에서 적절한 규모의 데이터셋에서 훈련을 반복하는 것이 환각 문제를 줄일 수 있지만, 반복의 정도와 데이터의 다양성 사이에서 적절한 균형을 찾는 것이 중요합니다. 아시다시피, 과도한 반복은 모델의 과적합(Overfitting)을 초래하여 새로운 데이터에 대한 일반화 능력을 손상시킬 수 있기 때문이죠. 결국 훈련 세트의 환각률과 다른 언어 모델의 성능 사이에는 절충(Trade-off)은 피할 수 없어보입니다.
|
|
|
저는 설명할 수 있는 AI(Explainable AI)에 대해 관심이 많은데요, Explainable AI라는 말을 처음 들었을때는 해당 내용을 공부하면 정말로 딥러닝의 모든 작동 방식이나 원리에 대해 알게 될 줄 알았어요. 그러나 막상 살펴보니결과를 바탕으로 해석하는것과, 해석할 만한 중간 결과를 체크포인트로서 확인하는 것이 중요했던 것 같아요. 예를 들면, CV의 경우 Attention Map을 통해 모델이 이미지의 어느 부분을 표현하고 있는지 확인함으로써 잘 학습이 되고 있는지 중간 점검이 가능하죠. 그러나 언어 모델의 경우 눈에 보이지 않기 때문에 학습 과정을 설명하는것이 더욱 어렵다고 생각해왔습니다. 오늘 소개한 연구에서는 지식 그래프를 통해 데이터셋을 통제하는 방법을 도입하여 환각을 정량적으로 탐지했는데요. 이 접근방식은 언어 모델의 설명가능성에 대해서도 유용하게 쓰일 수 있을 것 같습니다. 🥳 |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|