뉴스레터 오픈율을 기준으로 선정한 TOP 3 뉴스레터의 후속 연구를 소개합니다. # 52 위클리 딥 다이브 | 2024년 8월 14일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 지난 1년 동안 발송한 뉴스레터 중 많은 관심을 받은 뉴스레터를 소개합니다.
- 관심 주제와 유사한 후속 연구를 소개합니다.
- 다이브의 목표와 함께 감사 인사를 전해드립니다.
|
|
|
1주년 기념 총 결산: 오픈율 TOP 3 뉴스레터 다시보기 |
|
|
안녕하세요, 에디터 배니입니다.
지난해 8월 10일, Weekly deep daiv.라는 이름으로 뉴스레터를 첫 발송했습니다. 그동안 인스타그램을 통해 흥미로운 AI 모델을 소개하면서, 늘 짧은 글 속에 많은 내용을 녹여내지 못해 아쉬움이 남았었는데요. 이러한 아쉬움을 남겨두지 않고, 긴 호흡을 통해 더욱 깊이 있게 AI 세계를 이해할 수 있는 글을 전달드리고자 뉴스레터를 시작하게 됐습니다.
그로부터 벌써 1년이라는 시간이 흘렀습니다. 그동안 (딱 1주일 쉬어간 것을 제외하고) 흥미로운 인공지능 소식을, 저희만의 스타일로 전해드리기 위해 꾸준히 뉴스레터를 준비했습니다.
이런 맥락에서 ‘과연 어떤 콘텐츠를 가장 많이 열어봤을까’ 궁금해졌는데요. 이번 뉴스레터는 1주년을 기념해 지난 Weekly deep daiv. 콘텐츠를 돌아보며 오픈율이 높았던 콘텐츠 3가지를 다시 소개드립니다. |
|
|
TOP 3. 파인튜닝은 죽었다: ICL vs PEFT 개념 총정리 |
|
|
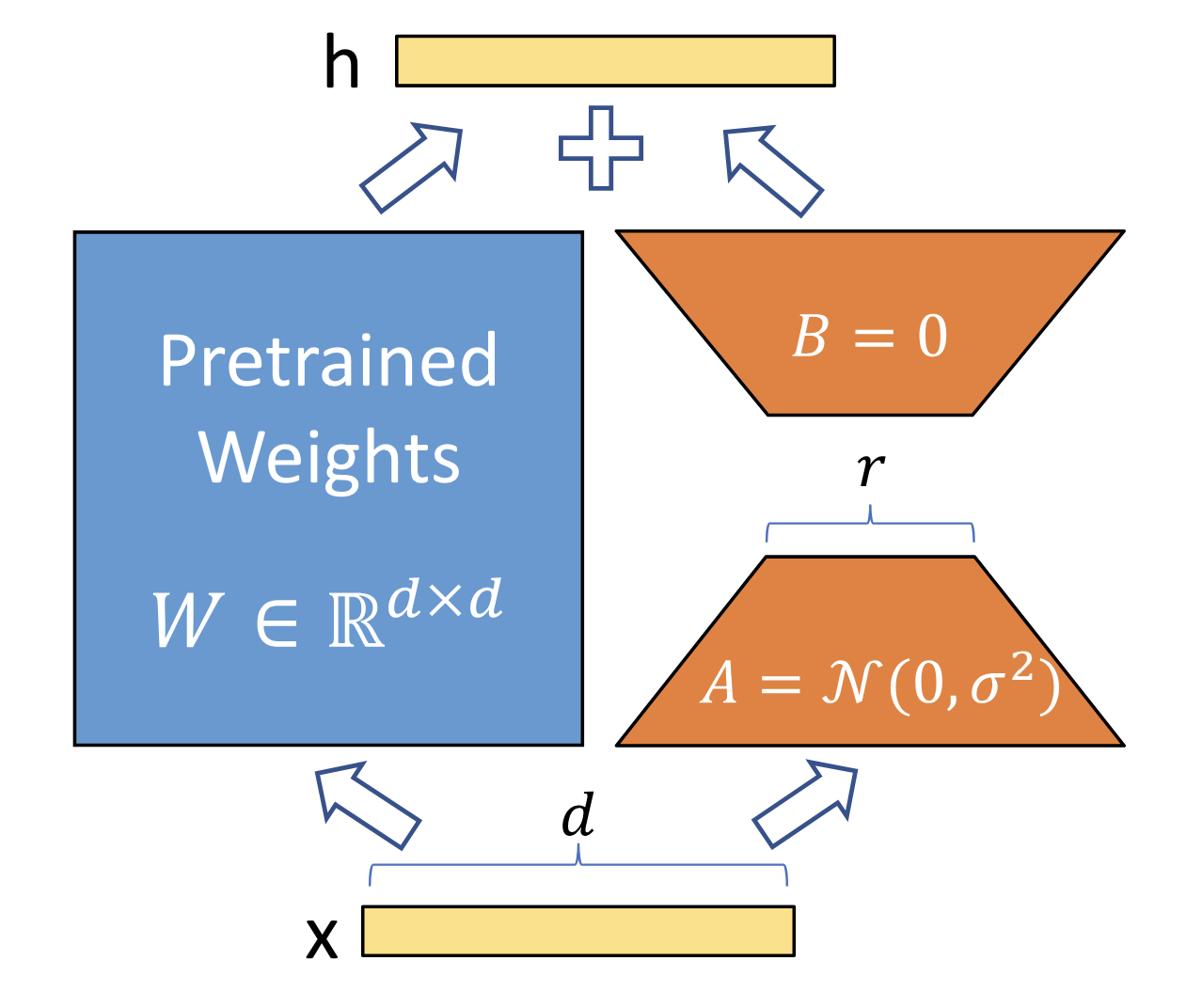
오픈율 3위는 ICL(In-Context Learning)과 PEFT(Parameter Efficient Fine-tuning)을 비교한 뉴스레터 <#38 ICL vs PEFT: 개념 정리> (🔗 링크)입니다. AI 모델이 한 번에 이해할 수 있는 문맥의 길이가 늘어난 것을 Long-Context라고 하는데요. 덕분에 성능을 개선하기 위한 예시(Shot)를 더욱 많이 입력할 수 있게 되면서 파인튜닝 학습에 상응할 정도로 ICL 성능이 개선됐습니다. 상황이 이러다보니 파인튜닝(Fine-tuning)이 필요한가에 대한 의문을 제기하기도 하고요.
각 개념에 대해서 간단히 요약하자면, 파인튜닝(Fine-tuning)은 대규모로 학습된 사전 훈련 모델에 특정한 도메인에 해당하는 적은 데이터셋으로 추가 학습하여 파라미터를 미세(Fine)하게 조정(Tuning)하는 과정입니다. 이렇게 축적된 지식 정보를 활용해 새로운 목적으로 학습 과정을 전이 학습(Transfer Learning)이라고 합니다.
그리고 PEFT는 이런 파인튜닝 과정에 드는 비용을 줄이면서 성능은 그대로 유지할 수 있도록 파라미터를 효율적으로 업데이트하는 여러 방식을 뜻합니다. 사전 훈련된 모델의 파라미터는 규모가 크다보니 학습 시 많은 비용이 드는데요. 이 파라미터는 고정하고 모델의 가장 앞선 단계에서 Prefix Tuning을 진행하거나, 최종 단계에서 Adapter를 부착하는 방식으로 학습 성능을 개선하는 동시에 비용을 절약하는 것입니다. 최근에는 Reparametrization 방식으로 LoRA나 QLoRA가 주로 활용됩니다. 이는 입력 단계나 중간 단계에 Adapter 블록을 삽입하는 것이 아니라, 낮은 차원의 행렬을 업데이트한 뒤 사전 훈련된 파라미터 값에 더하는 방식입니다. |
|
|
한편, ICL은 컨텍스트 안에 주어진 여러 예시들을 학습하여 답변의 패턴을 이해하는 과정입니다. 사용자가 원하는 답을 얻기 위한 문제에 대해서 몇 가지 예제들을 만들어 두고, 이를 언어 모델에게 자연어 형식으로 입력합니다. 모델은 해당 프롬프트를 기반으로 답변을 내놓게 되는데, 이 과정에서 예제를 조건으로 하여 답변을 내기 위해 예제의 패턴을 학습합니다.
직관적으로 생각해봐도 예제가 많을수록 패턴을 파악하는 데 용이하기 때문에 성능은 더욱 개선될 텐데요. 이와 동시에 긴 프롬프트를 처리하는 데 비용이 많이 들게 됩니다. 일반적으로 ICL은 예제의 개수에 따라서 Zero-Shot / One-Shot / Few-Shot 등으로 구분합니다. 최근에는 Long-Context 모델이 개발되고 있는 만큼 Many-shot ICL도 연구되고 있고요.
해당 주제의 시리즈로 <#39 ICL vs PEFT: 올해 트렌드는?> (🔗 링크) 뉴스레터를 전해드렸습니다. 여기서 본격적으로 ICL과 PEFT 중 어떤 것이 주로 활용되는지 설명하는데요. 결론만 말씀드리자면, 목적에 따라 다릅니다. ICL은 모델의 파라미터를 업데이트하지 않아도 되기 때문에 간편하게 학습할 수 있다는 장점이 있지만, 추론 시 비용이 높고 PEFT는 파라미터를 업데이트하는 데 비용은 들지만 추론 시 비용을 아낄 수 있기 때문입니다. 이와 관련해 관심 있는 분들은 후속 뉴스레터도 같이 읽어보시길 바랍니다. |
|
|
TOP 2. 생성 모델로 객체의 깊이를 추정하는 방법: Marigold |
|
|
오픈율 2위는 Depth Estimation 모델인 Marigold를 소개한 <#22 생성 모델로 객체의 깊이를 추정하는 방법> (🔗 링크) 입니다. Depth Estimation은 말 그대로 ‘깊이’를 추정하는 모델인데요. 여기서 ‘깊이’란 객체 사이의 거리감으로 이해할 수 있습니다. 깊이 추정 모델은 여러 산업 분야에서 다양하게 활용될 수 있는데요. 특히 자율주행 자동차가 카메라만으로 주변 사물과의 거리 정보를 추정할 때 유용하게 쓰입니다.
인간은 양안의 시차를 활용해 깊이를 추정합니다. 하지만 한 쪽 눈을 가린 상황에서도 (정확하진 않더라도) 어느 정도 추정이 가능한데요. Marigold는 한 쪽 눈을 가린 상황과 유사하게 2D 이미지 한 장만으로 깊이를 추정합니다. 이를 Monocular Depth Estimation이라고 하고요. |
|
|
Marigold는 Stable Diffusion 사전 훈련 모델의 성능을 그대로 빌려옵니다. 그리고 여기에 Depth Map을 추정하기 위해 파인튜닝을 추가로 진행하는데요. VAE를 활용해 실제 이미지와 Depth Map 이미지 각각을 잠재 공간으로 인코딩한 후에 Depth Map에 노이즈를 추가합니다. 두 이미지를 연결(Concatenation)하고 Diffusion 모델이 노이즈를 제거하며 다시 Depth Map을 생성할 수 있도록 합니다. Stable Diffusion의 기반이 되는 Latent Diffusion Model의 학습 원리를 그대로 활용하되, Depth Map을 생성하도록 만든 것입니다.
이후에도 Diffusion을 기반으로 한 Monocular Depth Estimation 모델에 관한 연구는 계속되었는데요. 그 중 한 연구에서는 이를 응용해 Flow Matching 기법을 도입한 Monocular Depth Estimation 모델 DepthFM을 소개했습니다. Flow Matching은 데이터의 흐름을 모델링하여 입력 이미지에서 깊이 맵으로의 최적 경로를 찾는 방법입니다. 여기서 '흐름'이란 데이터가 입력에서 출력으로 이동하는 경로를 의미합니다. 이 경로는 단순한 직선 경로가 아니라, 최적화된 여러 단계를 거쳐 데이터가 변환되는 과정을 나타냅니다. |
|
|
특히, 사전 훈련된 이미지 Diffusion 모델을 Flow Matching Depth 모델로 활용하여, 합성 데이터만으로도 실제 이미지에 일반화할 수 있도록 했습니다. 이 모델은 생성적 특성 덕분에 깊이 추정의 신뢰도를 효과적으로 예측한다는 특징이 있습니다. 이 모든 것을 낮은 계산 비용으로 달성했다는 점에서 특히 주목받고 있습니다. |
|
|
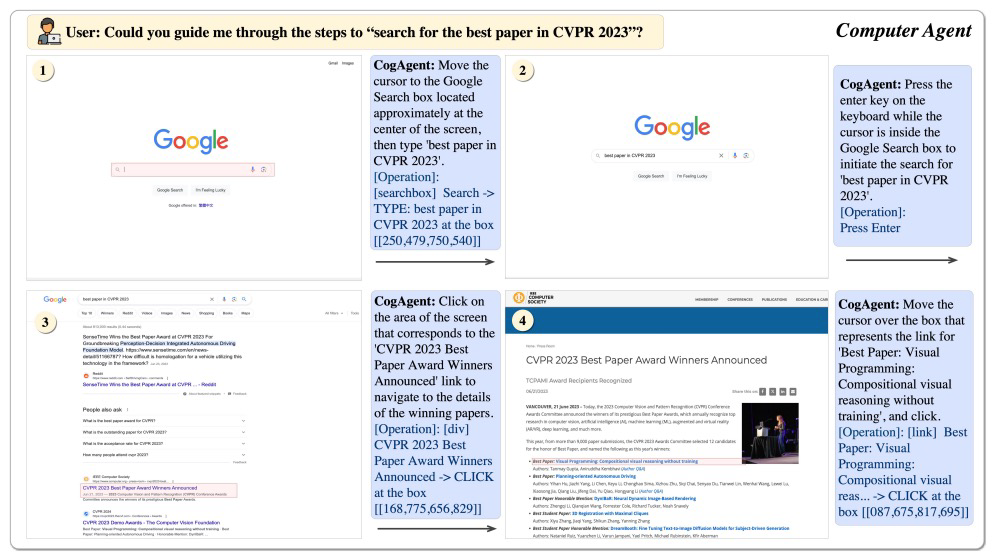
대망의 오픈율 1위는 올해 첫 뉴스레터 메일이었던 <#21 VLM이 온다> (🔗 링크) CogAgent에 관한 내용입니다. CogAgent는 컴퓨터와 상호작용할 수 있는 그래픽 요소인 GUI(Graphical User Interface)를 위한 VLM 기반 에이전트 모델입니다. VLM(Vision-Language Model)이란 시각과 언어 모델을 결합한 모델입니다. 즉, 우리가 보고 말하는 것을 이해할 수 있는 것이죠. 이는 생산성을 높여줄 수 있다는 점에서 연구 가치가 높고, LLM을 기반으로 개발되고 있어 빠르게 발전하고 있는 분야입니다. |
|
|
👨🏫 "CVPR 2023의 최우수 논문을 검색"할 수 있는 절차에 대해서 알려줄래?
Could you guide me through the steps to “search for the best paper in CVPR 2023”? |
|
|
사용자가 구글의 첫 화면을 켜고 CogAgent에게 다음과 같은 요청을 내리면 CogAgent는 검색창을 가리키며 ‘CVPR 2023 최우수 논문’을 입력하고, Enter 키를 누르고, 적절한 정보를 가리키고, 원하는 정보에 접근할 수 있도록 알려줍니다. 마치 사람이 웹을 동작시키는 것과 같이 말이죠.
해당 논문은 지난해 12월 발표되어 많은 관심을 받았었는데요. 당시에는 초기 모델로서 개선해야 할 부분이 많았습니다. 반 년이 넘게 지난 지금도 이와 유사한 연구는 계속되고 있습니다. 지난 7월에는 알리바바의 계열사 중 하나인 Ant Group에서 MobileFlow 모델을 발표했습니다. |
|
|
MobileFlow는 GUI 환경에서의 상호작용을 학습하도록 개발됐습니다. 앞서 웹 환경을 기반으로 학습했던 것처럼 MobileFlow는 사용자가 스마트폰에서 특정 앱을 실행하고, 원하는 기능을 찾기 위해 여러 버튼을 누르거나 메뉴를 탐색하는 과정 등에 최적화됐다고 볼 수 있습니다.
이 모델은 Qwen-VL-Chat이라는 오픈 소스 모델을 기반으로 하여, 다양한 해상도의 이미지 입력을 처리하고 다국어 GUI를 지원할 수 있도록 향상됐는데요. 실제로, MobileFlow는 GUI 에이전트가 모바일 관련 작업을 수행하는 데 있어서 GPT-4V나 Qwen-VL-Max보다 뛰어난 성능을 보여줬다고 설명합니다. 또한 연구진은 실제 비즈니스 환경에서도 성공적으로 적용됐다고 밝히며 실제로 사용 가치가 높다는 것을 입증해보이기도 했습니다. |
|
|
이렇게 오픈율이 높았던 뉴스레터 3편을 소개했습니다. 사실 이외에도 뉴스레터 창간 후 초반 뉴스레터 역시 오픈율이 상당히 높았는데요. 초기 구독자들인 만큼 AI 관심도가 높기 때문에 이러한 결과가 나왔다고 판단해 이는 제외한 결과를 소개드렸습니다.
이번 뉴스레터가 벌써 52호입니다. LLM, 멀티모달, 로보틱스 등 딥러닝 연구 분야에서 논의되는 주제라면 어느 것도 빠짐 없이 전달하기 위해 노력했습니다. 모든 독자분들의 입맛에 꼭 맞을 수는 없다고 생각하기에 오픈율에 편차가 있을 것이라는 점은 당연히 여기고 있는데요.
다행히 어떤 주제를 다루더라도 많은 독자분들께서 꾸준히 저희 뉴스레터 메일을 열고 있습니다. 저희 콘텐츠를 읽고 지속적으로 관심을 가져주시는 독자 여러분들께 감사의 인사를 전합니다. 또한 지금까지 꾸준히 좋은 콘텐츠를 제작해준 콘텐츠 팀 팀원들 환, 유현, 민재에게 다시 한번 깊은 감사를 전합니다. (새로 함께한 잭잭에게도 미리 감사를!)
지난 콘텐츠를 돌이켜 보니 감회가 새롭습니다. 다이브는 앞으로도 소외되는 주제 없이 깊이 있고 재밌는 콘텐츠를 전달하기 위해 노력하겠습니다. 감사합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|