GPT-4를 해석하기 위한 OpenAI의 연구 중 Sparse Autoencoder의 의미를 정리했습니다.
이번 연구의 한계와 앞으로 LLM 연구의 전망에 대해 소개합니다.
😎 언어 모델을 해석하는 방법
안녕하세요, 에디터 배니입니다.
AI 모델의 내부 작동 방식을 파악하기 어렵다는 말을 들어보신 적이 있나요? 모델의 학습 설계는 인간이 하지만 학습이 어떤 방향으로 진행되는지는 파악하기 어렵습니다. 때문에 AI 모델이 예측한 결과에 대해서 이유를 밝히는 것 또한 어렵죠. 이런 특성을 가진 AI에 대해 블랙박스라고 부르기도 합니다.
LLM의 급부상과 함께 그것이 지닌 여러 가지 한계점들도 같이 제기되었습니다. 대표적인 문제가 바로 '환각(Hallucination)'입니다. ‘환각’은 LLM이 실제로 사실이 아닌 것을 실제 사실인 것처럼 답하는 현상을 뜻합니다. 이 문제가 반복되면 LLM의 뛰어난 성능에도 불구하고 신뢰를 잃기 마련이죠.
그외에도 LLM은 유해한 콘텐츠를 생성하거나, 인종과 성별에 관해 혐오 발언 등을 내뱉기도 합니다. 이런 문제를 막기 위해 위험하거나 차별적인 질문에 대해서는 선제적으로 차단하는 방법을 활용하고 있는데요. 이 역시 모델을 공격하는 프롬프트를 주입하는, 이른바 '탈옥(Jailbreak)'을 통해 LLM을 무방비하게 만들어버리기도 하죠. 이런 문제들을 근원적으로 해결하기 위해서 LLM의 작동 방식과 결과에 대한 해석이 필요할 것입니다.
최근 AI 기업들은 LLM을 해석하기 위한 방법에 대해 연구하고 있습니다. 신뢰 가능한 언어 모델을 최우선으로 하는 Anthropic은 자사의 언어 모델 Claude 3를, 가장 많은 사용자를 보유한 OpenAI는 GPT-4를 기반으로 해석하는 방법에 대해 논문을 발표했습니다. 두 연구에는 공통점이 있는데, 바로 LLM 해석을 위해 Sparse Autoencoder를 활용했다는 것입니다.
Sparse Autoencoder가 무엇일까요? 이번주 뉴스레터는 지난 6월 6일 발표된 OpenAI의 연구를 바탕으로 Sparse Autoencoder와 LLM을 해석하는 방법에 대해서 알아보도록 하겠습니다.
Autoencoder는 무엇일까?
우선, 논문을 살펴보기에 앞서 Autoencoder에 대해서 알아봅시다. Autoencoder의 목적은 데이터의 특성을 파악하는 것입니다. 이를 위해서 Autoencoder는 입력 데이터 자기 자신을 예측합니다. 자기 자신을 예측한다니, 이게 무슨 의미가 있는 것일까요? 사실상 입력을 그대로 내보내면 정답률 100%인 것 아닐까요?
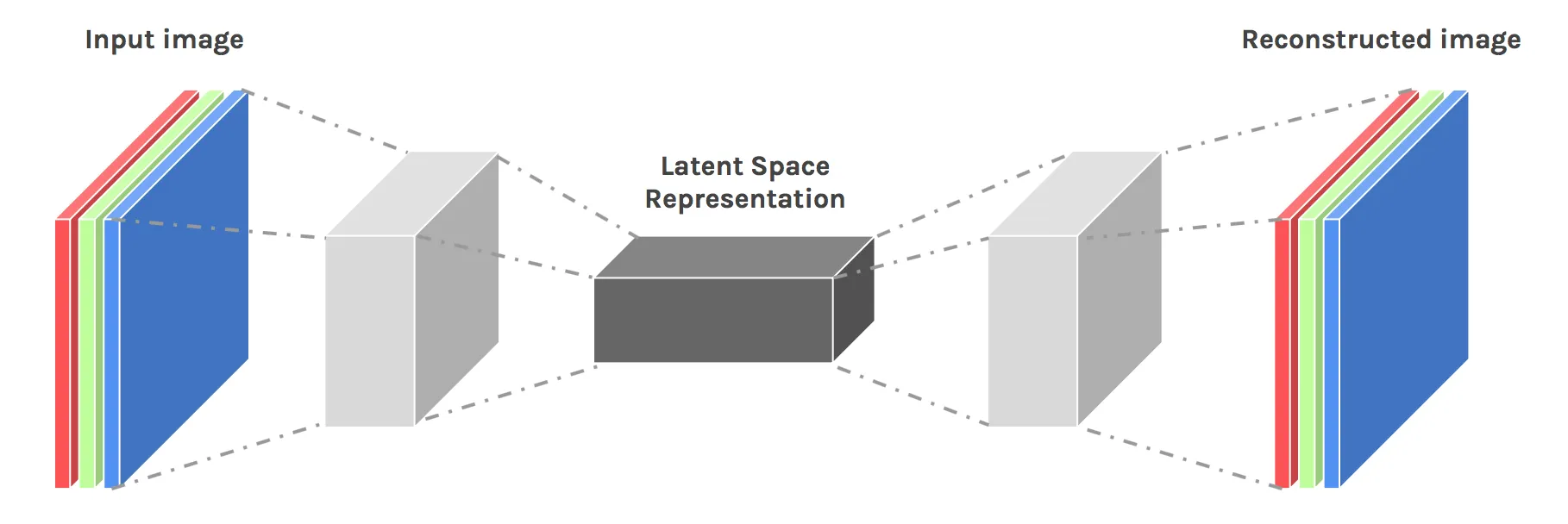
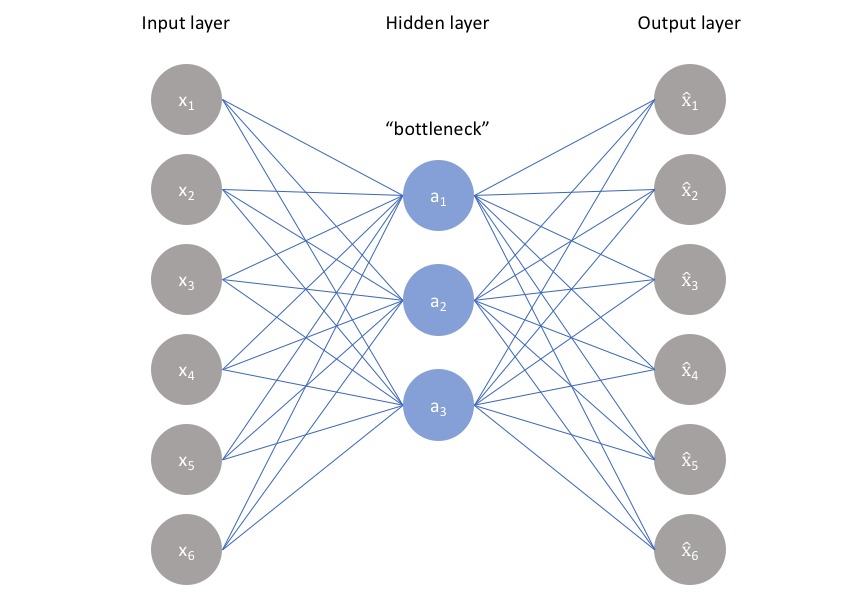
맞습니다. 하지만 Autoencdoer는 데이터의 특성을 파악하기 위해서 네트워크를 병목(Bottleneck) 구조로 만들어서 데이터의 특성(Feature)을 압축한다는 특징을 가지고 있습니다. 아래 이미지를 예시로 Autoencoder의 구조를 살펴보면서 설명하도록 하겠습니다.
Autoencoder는 인코더(Encoder)와 디코더(Decoder)로 구성되어 있습니다. 위의 예는 입력 이미지(Input Image)를 압축하고, 다시 압축된 정보를 복원(Reconstructed Image)하는 과정을 보여줍니다. 복잡한 수식은 제외하고 그 의미를 생각해보면, 인코더는 데이터를 압축하는 역할을 하고, 디코더는 압축된 정보로 다시 원본 데이터를 예측하는 역할을 하도록 학습됩니다. 이 학습 과정이 반복되면서 잠재 공간(Latent Space)에는 원본 데이터의 의미가 압축된 형태로 나타납니다.
Autoencoder로 입력 데이터를 압축한 것만 가지고는 데이터에 대해 해석하기란 어렵습니다. 언뜻 보기에는 무의미한 숫자 집합에 불과한 것처럼 보이기 때문입니다. 이를 해석 가능한 정보로 변환하기 위해서는 정보가 압축(Dense)된 형태가 아니라 조금 더 희소(Sparse)한 형태로 살펴볼 필요가 있습니다.
인간의 뇌로 비유하자면 입력된 정보의 종류마다 처리할 때 활성화되는 부분이 다를 텐데요. 뇌의 복잡하고 넓은 신경망(희소한 공간) 내에서 어느 부분이 활성화되는지 살펴보는 것과 같습니다. Autoencoder는 처리해야 할 정보를 압축하는 개념이라면, 앞으로 소개할 Sparse Autoencoder는 처리해야 할 정보 입력됐을 때 어느 부분이 활성화되는지 살펴보는 것과 같습니다.
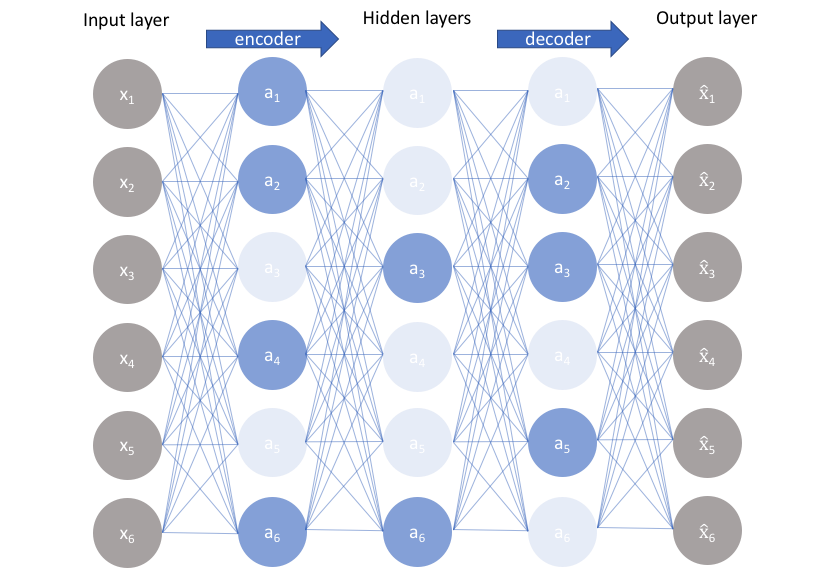
Sparse Autoencoder의 전체적인 구성은 Autoencoder와 유사합니다. 다만, 신경망 전체를 활성화시키는 것이 아닌, 아주 적은 영역만 활성화되도록 제한하도록 구성했습니다. 수학적인 내용이 궁금하다면, 스탠포드 대학 앤드류 응 교수님의 Sparse Autoencoder 강의 노트(🔗링크)를 참고해주세요.
위의 이미지에서 보는 것처럼 왼쪽이 기본적인 Autoencoder라면, 오른쪽은 Sparse Autoencoder를 나타냅니다. 정보가 압축된다기보다는 일부만 활성화하는 것을 볼 수 있습니다.
문맥 정보를 ‘제대로 활용’하는 방법
기존에 작은 언어 모델에 대해 그 특성을 해석하고자 하는 시도는 몇 차례 있었지만 대규모 언어 모델, 즉 LLM에 대해서는 어려움이 있었습니다. 그러나 OpenAI는 <Scaling and evaluating sparse autoencoders> 연구 논문을 발표하며 GPT-4의 작동 원리를 파헤쳤다고 밝히며 오픈 소스로 코드를 공개했습니다.
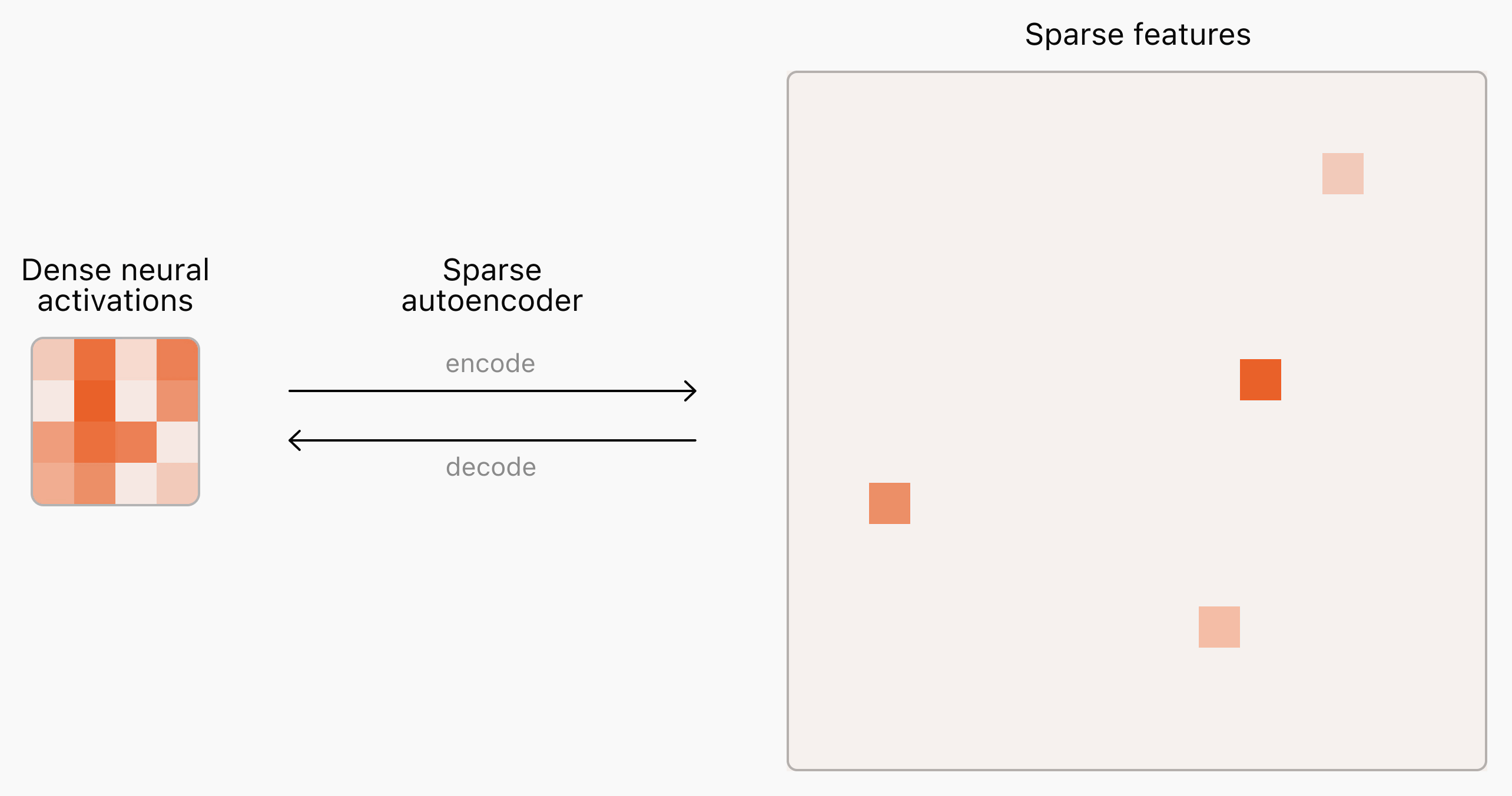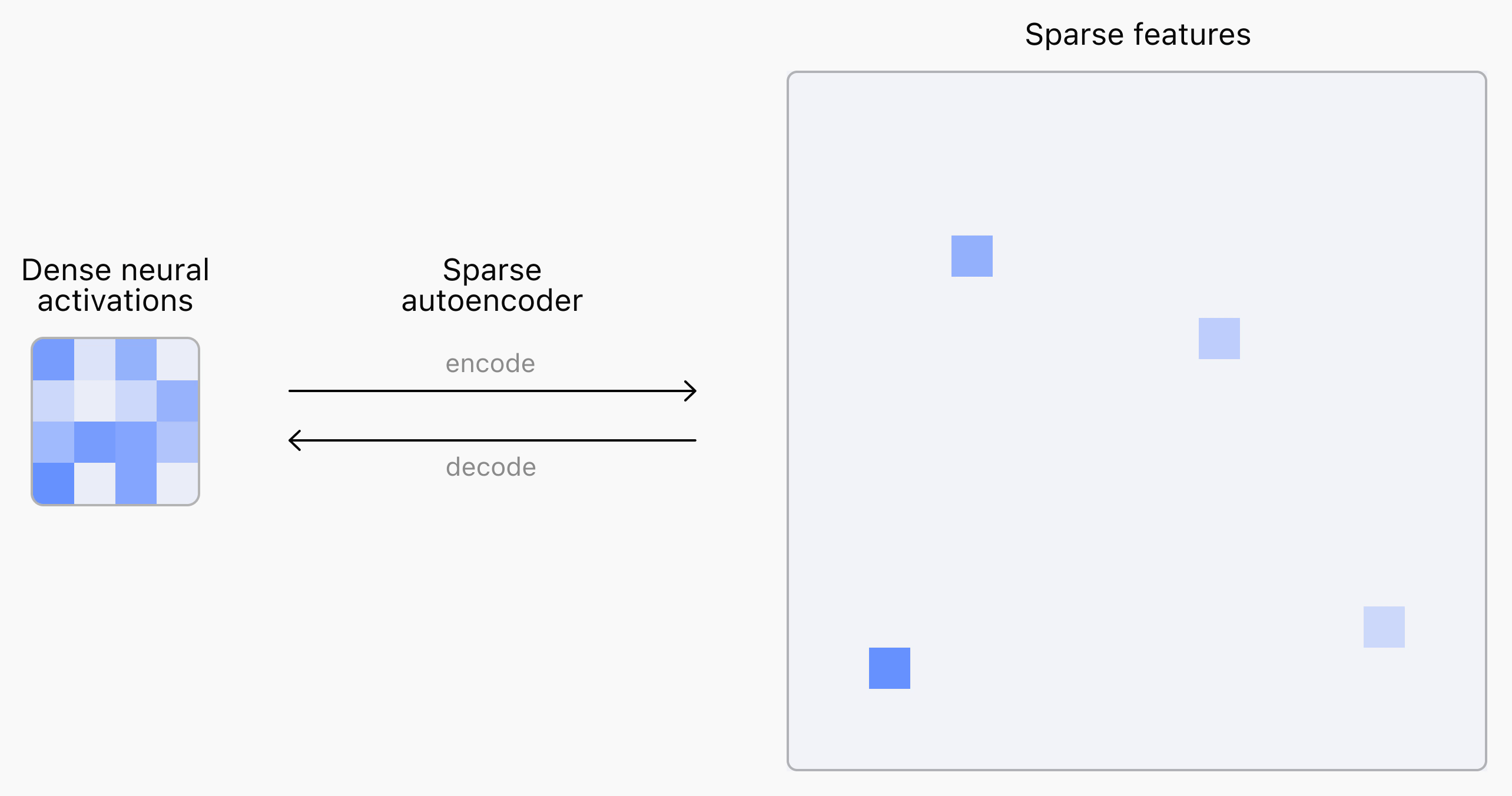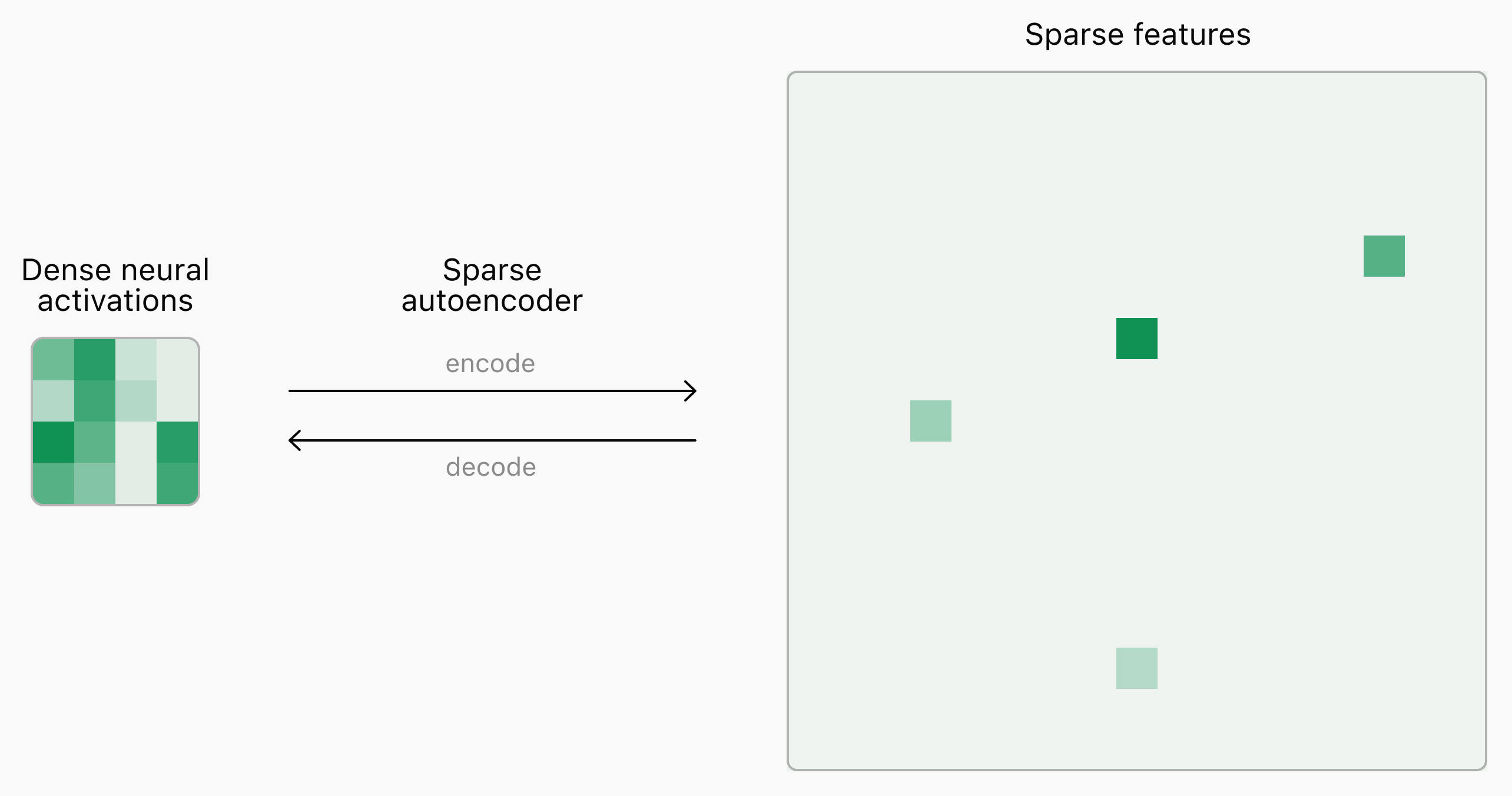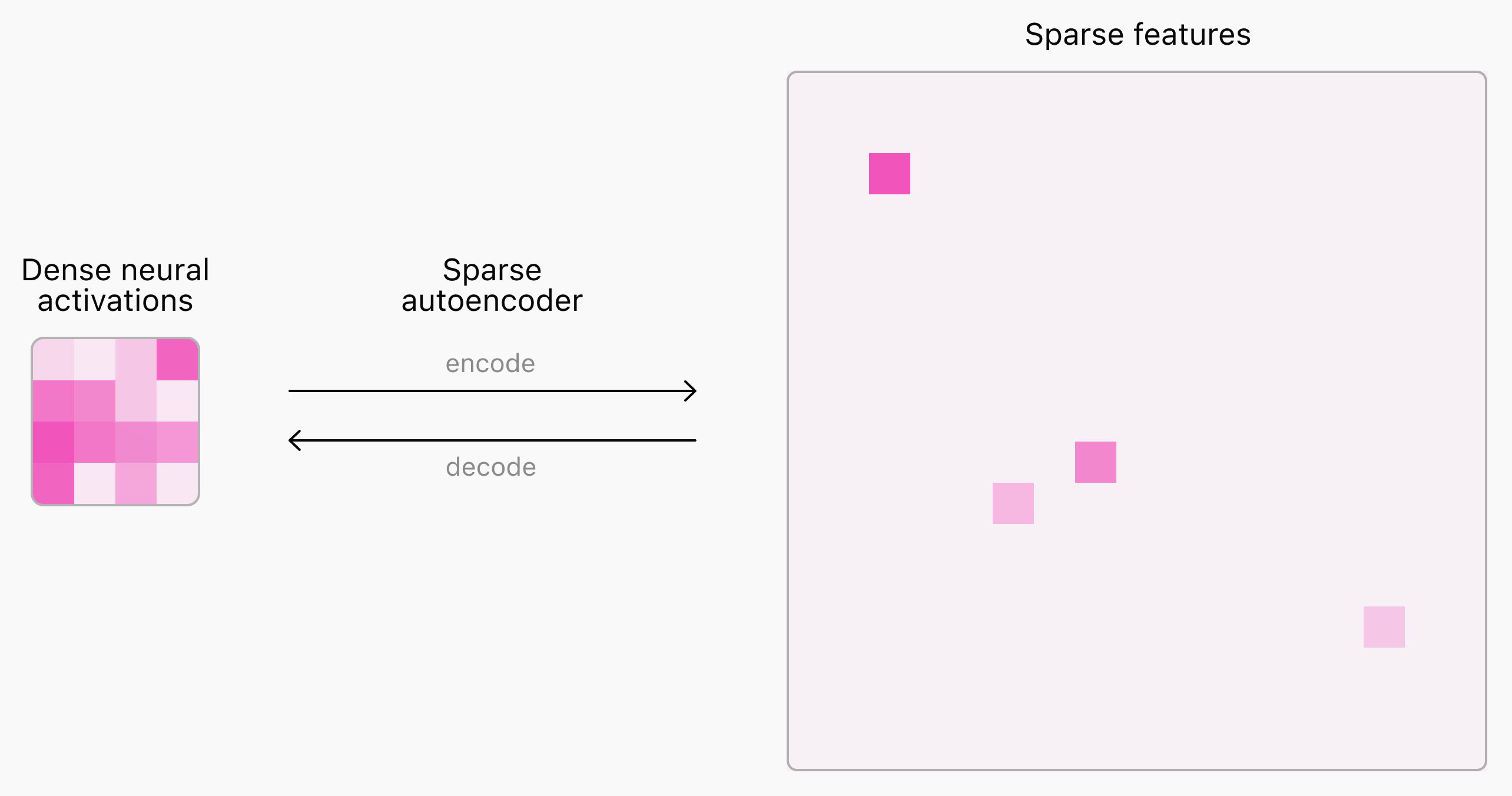
아시다시피 GPT는 여러 개의 Attention 기반의 Transformer 디코더 레이어로 이뤄져 있습니다. OpenAI는 Sparse Autoencoder의 입력 데이터로 GPT의 출력층에 가까운 Transformer 레이어의 활성화 정보를 활용했습니다. 이 활성화 정보는 곧 다음 토큰을 예측하는 데 활용하기 때문에 언어 모델이 예측하기 위해 필요한 정보가 압축되어 있다고 볼 수 있습니다.
위의 그림에서 살펴볼 수 있듯이, 압축되어 나타난 신경망 활성화 정보(Dense Neural Activations)를 기반으로 희소 특성(Sparse Features)을 추출하는 것을 볼 수 있습니다. 사실, 위의 희소 특성만 보고도 당장 해석하기는 어렵습니다. 만약, 유해한 입력 정보가 동일한 곳에서 활성화되어 나타난다면 해당 부분을 개선하도록 만들면 됩니다. 또한 활성화되는 지점이 매핑되는 토큰을 찾는다면 어떤 이유로 환각, 탈옥 등이 발생하는지 찾아볼 수 있습니다.
참고로 OpenAI가 활용한 모델은 기본적인 Sparse Autoencoder 구조는 동일하지만, 상위 K개의 정보만 활성화되고 나머지 정보는 모두 0으로 만들도록 학습시켰습니다. 이를 K-sparse Autoencoder라 부릅니다. 이 구조는 활성화된 정보에 대한 단일 의미(Monosemanticity)를 상승시킨다고 알려졌습니다.
그런데 상위 K개만 선택하도록 만들면서 일부 공간만 활용하게 됩니다. 다른 말로, 활용되지 않은 일부 영역은 쓸모 없는 죽은 잠재 공간(Dead Latent)이 된다는 것인데요. 이 공간은 최소한으로 줄일수록 더욱 효율적인 모델이라고 할 수 있겠죠. OpenAI의 연구에 따르면 (파라미터 기준) 다른 모델의 경우 34M 잠재 공간 내에서 12M 활성화되었을 정도로 낭비가 심했는데요. OpenAI는 16M 잠재 공간 내에서 죽은 공간을 7%까지 줄이며 공간을 효율적으로 활용했습니다.
이러한 연구 성과에도 불구하고 연구진들은 GPT-2와 같은 작은 언어 모델과 달리, GPT-4와 같은 대형 언어 모델에서는 여전히 많은 활성화 특성들이 단일한 의미를 갖지는 않는 것으로 보았습니다. 연구진은 이러한 부분에 대해 지속적으로 연구하겠다고 밝혔습니다. 아직 완전히 LLM을 이해하기는 어렵지만, 그 시도는 이제 막 발을 뗐다고 볼 수 있겠습니다.
OpenAI의 이번 연구는 Anthropic이 지난 5월에 발표한 연구와 비슷한 양상으로 나타났습니다. 불과 1달 사이에 유사한 연구가 이어지면서 앞으로 설명 가능한 AI(XAI; eXplainable AI)에 대해 더욱 많은 연구가 이뤄질 것으로 보입니다.
큰 틀에서 보면 아직 우리는 LLM이 어떻게 동작하는지도 알지 못한 채 활용하고 있습니다. 여러 우려 사항들을 덮어두고 앞을 보며 달려가고 있는 이 상황, 여러분들은 어떻게 보시나요? 조금은 위험해보이기도 하지만, LLM이 주는 편의성이 큰 만큼 기술이 문화에 비해 앞서는 상황을 막을 수 있어보이진 않습니다. 당장 기술 발전을 중단하는 것과 같이 다소 과격한 방식으로 현실을 바꾸기는 어려운 만큼, 우리가 다루고 있는 기술을 해석하려는 시도나 모델의 의미를 설명하려는 노력이 더욱 필요하다고 생각합니다. 이번 연구의 성과가 더욱 반가운 이유이기도 하고요.