Long-Context에서 발생하는 Lost in the Middle 문제와 대안을 소개합니다. # 43 위클리 딥 다이브 | 2024년 6월 12일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- Long-Context에서 나타날 수 있는 Lost in the Middle 문제를 알아봅니다.
- Lost in the Middle 문제가 발생하는 이유를 3가지로 정리했습니다.
- Lost in the Middle 문제의 대안으로 IN2 훈련 방법을 소개합니다.
|
|
|
😰 집중력 잃은 AI, 정신 차리게 만드는 법 |
|
|
안녕하세요, 에디터 배니입니다.
여러분들은 책을 자주 읽으시나요? 한 권의 책을 다 읽고 나면 얼마나 많은 내용이 기억에 남으시나요? 아마 모든 내용을 기억한다고 말하긴 어려울 것입니다. 꼭 독서뿐만이 아니라 업무를 하다 보면 필요한 문서를 읽고 필요한 정보를 요약하거나, 원하는 정보를 찾아야 할 때가 있죠. 집중이 잘 되지 않는 날에는 필요한 정보가 어디 있었는지 잊기도 합니다.
최근에는 AI를 활용해서 문서 내의 정보를 빠르게 찾을 수 있다고 합니다. 일종의 QA(Question&Answering) 태스크입니다. 질문과 관련된 정보를 문서 내에서 찾아서, 적절한 답변을 생성하는 것이죠. AI가 한 번에 이해할 수 있는 문맥의 길이가 길어지면서(이를 ‘Long-Context Window’라고 합니다. 이와 관련된 정보는 🔗 지난 뉴스레터 확인해보세요!) 수십 페이지가 넘는 긴 문서도 이해할 수 있게 됐습니다.
우리는 기억하지 못해도 기계는 정보를 모두 기억할 수 있지 않을까요? 이미 텍스트 데이터 형태로 원하는 정보를 다 가지고 있으니까요. 인간은 어떤 정보가 어디에 있는지 책을 뒤적이며 찾느라 오래 걸리지만, 컴퓨터는 빨리 찾을 수 있을 것이라 기대합니다. 원하는 정보가 몇 페이지에 있든 말이죠.
하지만, 그것은 틀렸습니다! 지난해 7월, 스탠포드 대학은 실험을 통해 LLM 모델에 입력되는 정보의 위치에 따라서 모델의 성능이 달라진다는 연구 결과를 발표했습니다. 이를 Lost in the Middle 문제라고 합니다. 그렇다면 이 문제는 왜 발생할까요? 해결 방법은 없는 것일까요? 이번주 뉴스레터에서는 Lost in the Middle 문제와 대안에 대해 다뤄봅니다. |
|
|
Lost in the Middle 문제가 등장한 이유 |
|
|
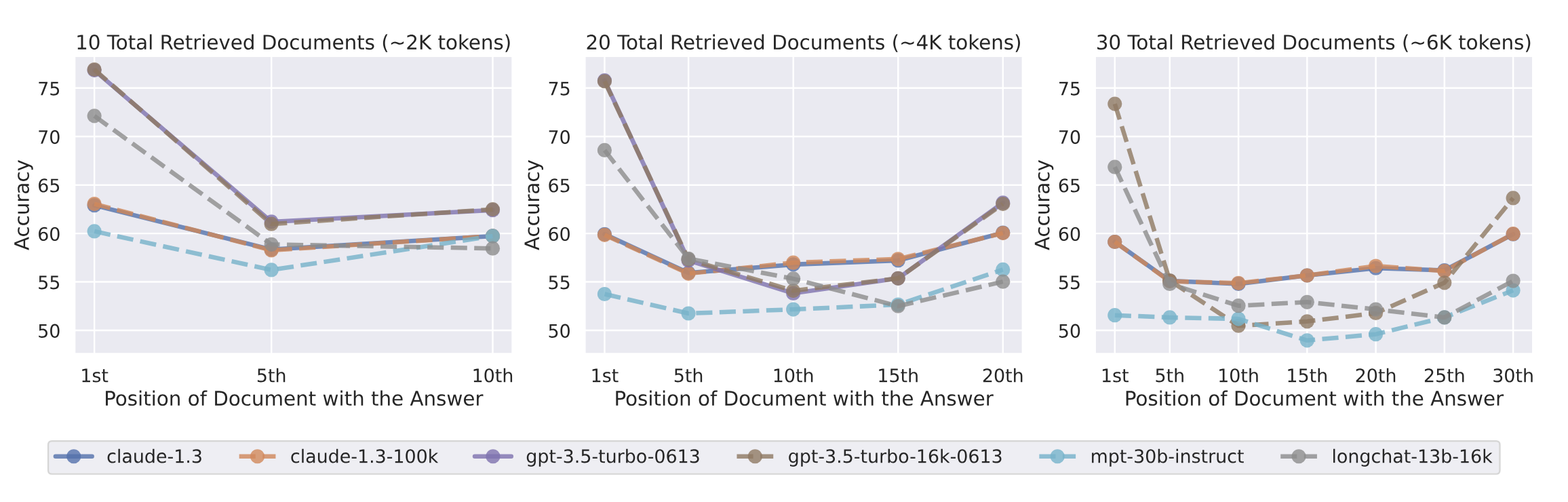
필요한 정보가 초반부와 종반부에 있는 경우 성능이 높고, 가운데에 있는 경우 성능이 낮아지는 U자 형태로 나타납니다.
|
|
|
위의 실험은 질문과 관련 있는 정보가 어디에 위치하느냐에 따라 성능이 달라진다는 것을 보여줍니다. 보다시피 U자 형태로 나타나는데요. 이는 관련 정보가 입력의 초반부와 종반부에 위치할수록 높은 성능을 보인다는 것을 의미합니다. 반대로 말하면 중반부에서는 성능이 저하된다고 말할 수 있죠. 그래서 연구진은 이 문제를 AI가 입력의 가운데 있는 정보를 잃어버린다고 보고, Lost in the Middle 문제라고 불렀습니다. 그리고 초반부에 등장하는 정보에 대해 초두 편향(Primary Bias), 종반부에 정보에 대해 최신성 편향(Recency Bias)이 발생한다고 봤습니다.
그 이유는 무엇일까요? 연구진은 이 이유를 3가지로 분석했습니다.
-
디코더 학습 구조
첫 번째는 모델의 학습 구조로 추측합니다. 우리가 익히 알고 있는 GPT는 Transformer의 디코더 부분으로만 이뤄져 있습니다. 디코더는 그 특성상 앞서 등장한 토큰만으로 다음 토큰을 생성합니다. 인간이 글을 읽어나가는 방식과 비슷하죠. 그래서 그런지 초반부에 무슨 내용인지 파악(핵심 주제)하고, 마지막에 어떤 내용(결론)으로 끝나는지 기억하기는 쉽지만 그것이 어떻게 전개됐는지 모두 기억하기란 쉽지 않습니다.
이와 상대적으로 인코더-디코더 구조의 모델로 학습했을 때 성능저하가 크게 나타나지 않는 것으로 나타났는데요. 인코더는 모델에 입력된 전체 내용에 대해서 동일하게 연관성을 판단하기 때문입니다.
-
질문의 위치
앞서 말씀드린 디코더 학습 구조의 특성상 질문(Query)의 위치에 따라서 학습 성능이 달라질 수 있습니다. 이는 우리가 국어 시험 문제를 푸는 방식과도 비슷한데요. 어떤 강사는 문제를 먼저 읽고 지문을 보라고 하죠. 이는 스타일에 따라 다르겠지만, 디코더에게는 확실히 필요합니다. 왜냐하면 디코더는 지문을 다시 읽을 수 없기 때문입니다. 즉, 질문이 먼저 주어진 경우, 질문에서 필요한 정보가 등장한 부분에 더욱 집중(Attention)해서 판단할 수 있지만, 그렇지 않은 경우에는 더 높은 가중치를 주기 어렵습니다.
-
지시사항 파인튜닝
마지막으로, 파인튜닝 방식의 문제를 지적합니다. 인간의 질문에 답하도록 만들기 위해서는 추가적인 학습이 필요합니다. 사전훈련된 모델에 지시사항(Instruction)을 이해할 수 있도록 훈련하는 과정을 Instruction Fine-tuning이라고 하는데요.
이때 지시사항 일반적으로 질문과 답변을 전체 입력의 앞부분에 구성합니다. 모델은 자연스럽게 초반부의 정보를 더욱 중요하게 학습할 것입니다. 질문에 맞는 정답을 찾기 위해서는 질문에 주어진 정보를 중요하게 판단해야 하기 때문입니다.
그렇다면 해결 방안은 없는 것일까요? 문제의 원인을 알았다면 그것을 제거하는 방법을 제안해볼 수 있겠죠. 하지만 ‘생성 모델’이라는 본질을 생각하면 학습 구조를 변경하기란 어렵고, 지시사항을 부여하지 않기란 어려워 보입니다. 그럼 질문의 위치로 이 문제를 해결할 수 있을까요? 다음으로 지난 4월, 이에 대한 대안을 제시한 연구를 알아보겠습니다. |
|
|
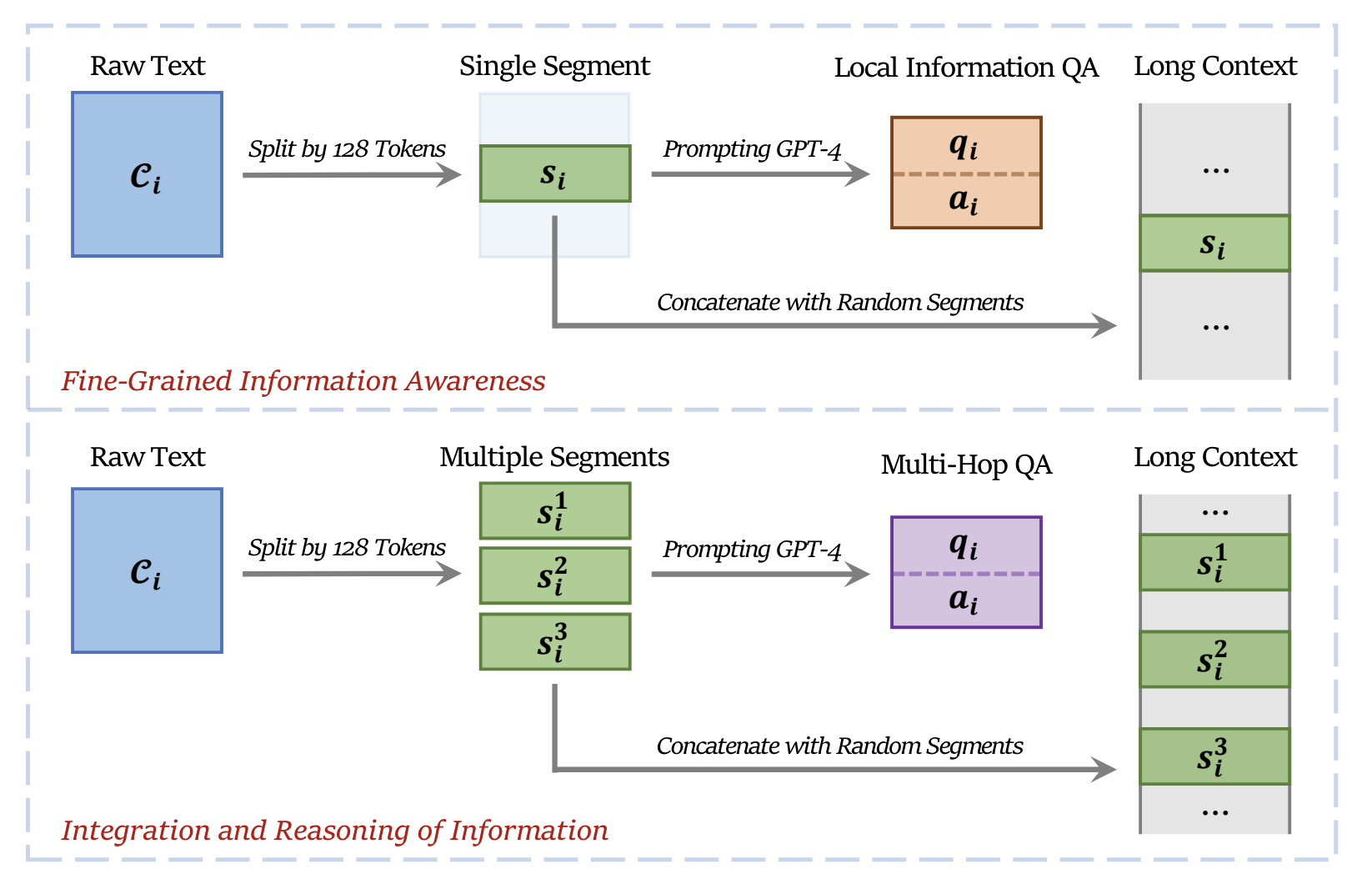
중국 시안 자오퉁 대학에서 발표한 <Make Your LLM Fully Utilize the Context> 논문에서는 Lost in the Middle 문제를 해소하고 긴 문맥 정보를 제대로 활용하기 위한 방법을 제안합니다. 문맥이 길어진다면 당연하게도 주어진 정보에 대해서 풍부하고 깊은 이해가 가능할 것입니다. 하지만 동시에 처리해야 하는 정보가 많아진다는 것을 의미하기도 하죠. 이 때문에 긴 컨텍스트 안에 정보가 산재되어 있다면 정확한 답을 내기가 더 어려워집니다.
그렇다면 정보가 어디에 위치하더라도 제대로 찾아 학습할 수 있도록 만들어야 합니다. 단순히 긴 텍스트를 입력하고 찾으라고 한다면, 정답이 자주 등장하는 위치(예를 들면 문장의 초반부나 마지막 부분, 질문에 대한 답을 찾을 수 있는 바로 다음 문장)에 편향될 가능성이 있겠죠. 그래서 이런 순서를 뒤섞어 학습시킨다면 위치에 대한 편향을 줄일 수 있을 것입니다. 그래서 연구진은 학습 과정에서부터 답이 등장하는 순서를 랜덤하게 뒤섞어 버립니다. 연구진은 이런 학습 방법을 INformation-INtensive(IN2) 훈련이라고 명명했습니다. |
|
|
한 가지 더 고려해야 하는 사항은 질문과 관련된 정보 내에서 원하는 답이 어디에 위치하느냐입니다. 예를 들어서 ‘샌프란시스코에서 반드시 해야 할 일이 무엇이야?’라는 질문과 관련해서, 주어진 텍스트 내에 ‘샌프란시스코에서 반드시 해야 할 일은 항구에서 샌드위치를 먹는 것입니다.’라는 정보를 찾았다면, 답을 ‘항구에서 샌드위치를 먹는 것’이라고 쉽게 찾을 수 있습니다.
이때 ‘샌프란시스코에서 반드시 해야 할 일’과 같이 원하는 답에 앞서 등장하는 부분을 Induction Head라 부릅니다. 모델은 Induction Head 뒤에 따라오는 정보만 찾으면 되기 때문에 주어진 문맥이 아무리 길더라도 답을 명료하게 내릴 수 있습니다. 그런데 이에 익숙해진다면 당연히 긴 문맥 정보를 제대로 활용할 수 없겠죠. 따라서 학습 과정에서 순방향(Forward), 역방향(Backward), 그리고 양방향(Bi-Direction)으로 정보를 찾을 수 있도록 데이터를 구성해야 합니다. |
|
|
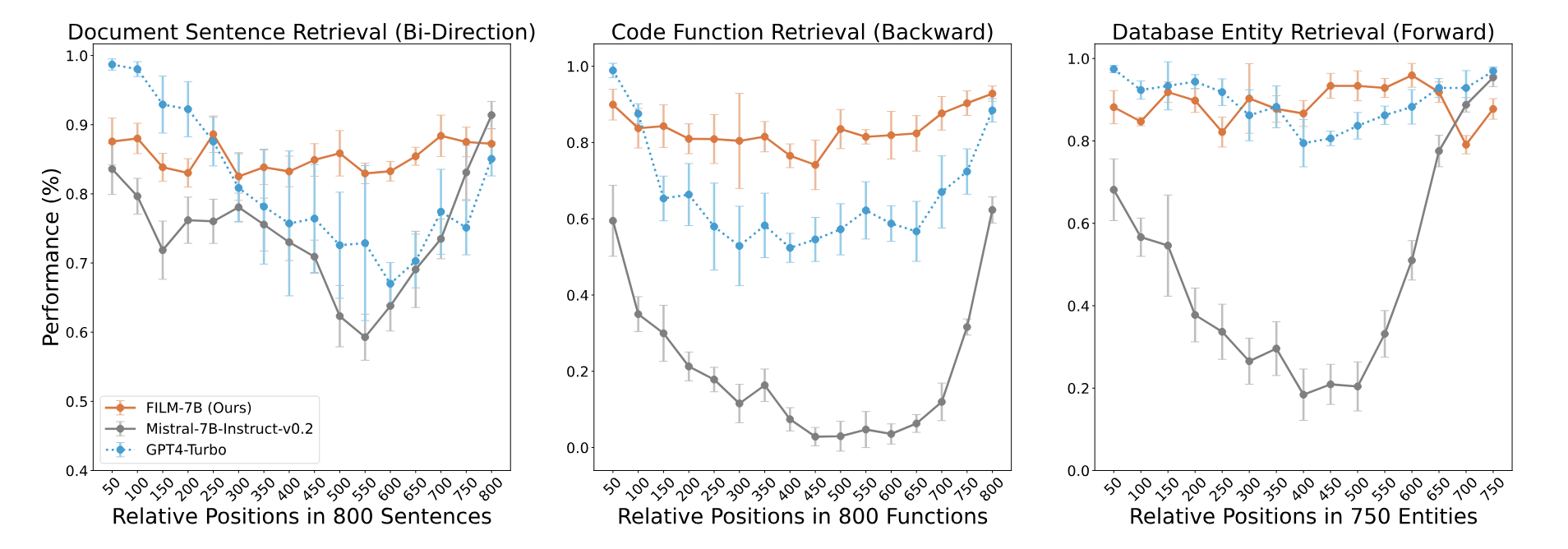
연구진은 Mistral-7B를 기반으로 학습을 진행했고, 앞서 소개한 방법을 활용해 FilM-7B(FILl-in-the-Middlle)를 발표했습니다. 연구진의 가설에 부합하듯, Lost in the Middle 문제는 어느 정도 완화된 모습입니다. 아래 차트에서 살펴볼 수 있듯이 다른 모델에 비해서 뚜렷한 U자 형태라고 보기는 어렵죠. |
|
|
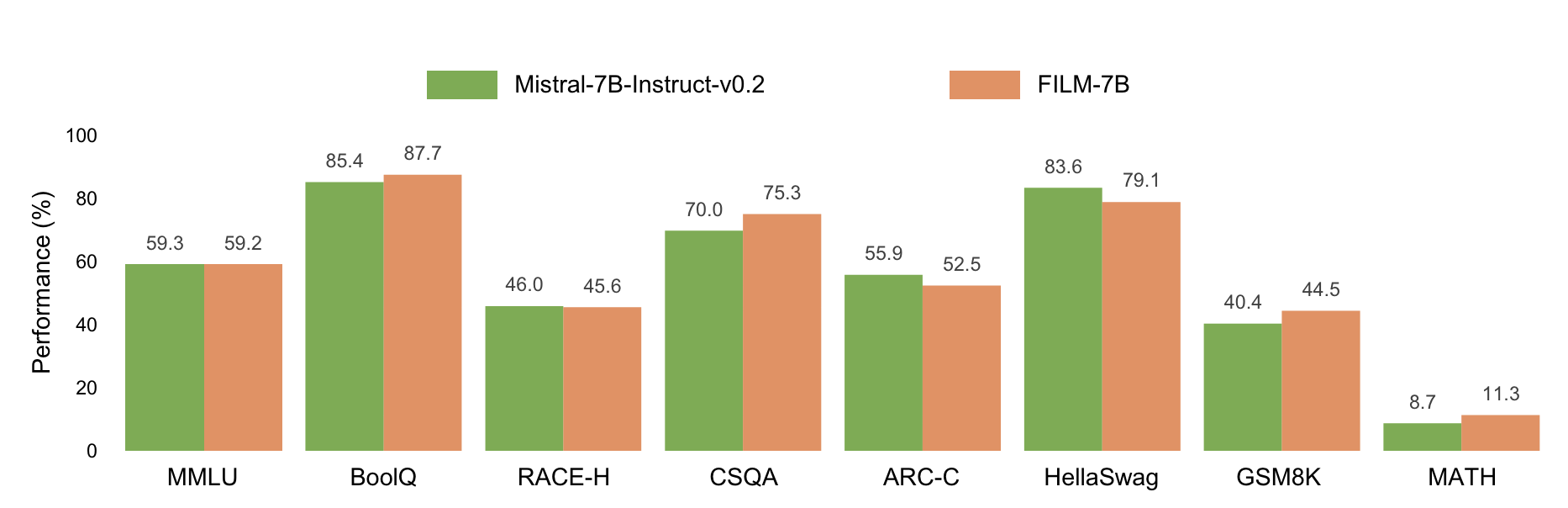
그러나 긴 컨텍스트 학습에 초점을 맞춰 학습 방법을 변경하게 되면 짧은 컨텍스트에 대한 성능이 저하될 수도 있습니다. 그러나 연구진은 실험을 통해 짧은 컨텍스트에 대해서도 기존 성능과 크게 차이나지 않는다고 밝혔습니다. 아래 그래프에서 대표적인 MMLU 벤치마크에서 0.1%p밖에 차이나지 않는 것을 볼 수 있습니다. |
|
|
AI도 아무 글이나 던져주면 중요하다고 생각하는 부분만 집중적으로 읽고 나머지 부분에는 제대로 신경쓰지 않는다는 게 참 신기합니다. AI가 독해하는 방식이 인간과 닮아 있다는 생각도 드는데요. 학습하는 과정에서도 질문에 답을 찾기 위해 질문 속 특정한 표현만 찾으려 드는 것도 어딘가 인간의 모습을 닮은 것 같아 마음이 찔리기도 합니다. 이는 AI와 인간 모두에게 어떻게 새로운 내용을 학습해야 하는지에 대해 근본적인 물음을 던집니다.
단순히 질문에 답하는 방식을 대증 요법으로 해결할 게 아니라, 정말 긴 컨텍스트를 이해하도록 만들고 이를 검증해야 할 것입니다. AI가 학습하는 방식은 인간의 학습 방식에서 많은 영감을 얻고 있는 만큼, 인간을 먼저 이해한다면 더욱 혁신적인 방법론이 등장하지 않을까 기대해봅니다.
|
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|