MoE의 문제점을 해결하기 위해 도메인 단위 Expert를 만든 EMO 논문을 소개합니다. #143 위클리 딥 다이브 | 2026년 5월 13일
에디터 영이 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- MoE의 Expert가 왜 토큰 단위로만 작동하고, 도메인 단위로는 작동하지 않는지 설명했습니다.
- EMO가 도메인 레이블 없이도 어떻게 전문화된 Expert 구조를 만들어내는지 소개했습니다.
- EMO가 메모리 효율, 추론 제어, 해석 가능성 측면에서 시사하는 바를 정리했습니다.
|
|
|
MoE의 Expert, 드디어 진짜 전문가가 됐습니다 |
|
|
Transformer 모델은 토큰 간 관계를 처리하는 어텐션 레이어, 그리고 각 토큰을 독립적으로 변환하는 FFN(Feedforward Network) 레이어로 나뉩니다. MoE는 이 FFN 레이어를 여러 개의 작은 네트워크인 Expert로 쪼개고, 입력 토큰마다 그 중 일부만 골라서 쓰는 구조입니다.
예를 들어 128개 Expert가 있고 토큰당 8개를 활성화하는 모델이라면, 매 토큰마다 Router가 “이 토큰은 Expert 4, 8, 15, 22를 쓰세요”라고 지정합니다. 나머지 120개 Expert는 해당 토큰에 대해서는 아무 연산도 하지 않습니다. 덕분에 파라미터 수는 많아도 실제 연산량(FLOPs)은 dense 모델보다 훨씬 적습니다. DeepSeek V4의 경우 1.6조 파라미터지만 토큰당 활성화되는 건 약 490억 파라미터입니다.
이 구조가 매력적인 이유는 명확합니다. 같은 연산 비용으로 훨씬 큰 모델을 만들 수 있고, 큰 모델일수록 더 많은 지식을 담을 수 있기 때문입니다. 많은 AI 회사가 MoE 구조의 LLM을 지속적으로 내놓는 이유도 이 때문이죠.
여기까지만 들으면, “코드 짤 때는 코딩 관련 Expert만 활성화되니까, 코딩 작업에는 그 Expert만 메모리에 올리면 되는 거 아닌가? 128개를 다 올릴 필요가 없잖아.”라는 합리적인 기대를 하는 사람이 있을지도 모릅니다. 만약 이것이 가능하다면, 700억 파라미터짜리 MoE 모델도 작업에 따라 100억 파라미터만큼의 VRAM으로 실행시킬 수 있을 것이기 때문이죠.
모두의 염원과 달리 실제로 일부 Expert만 골라서 사용하는 방식은 성능 폭락의 원인이 됩니다. 128개 Expert 중 32개(25%)만 골라서 추론해보면 MMLU 벤치마크 기준 10% 이상 성능이 낮아지며, 16개(12.5%)만 쓰면 15% 이상 낮아집니다. 아무리 정교한 Expert 선택 방법을 써도 이 벽을 넘지 못했습니다.
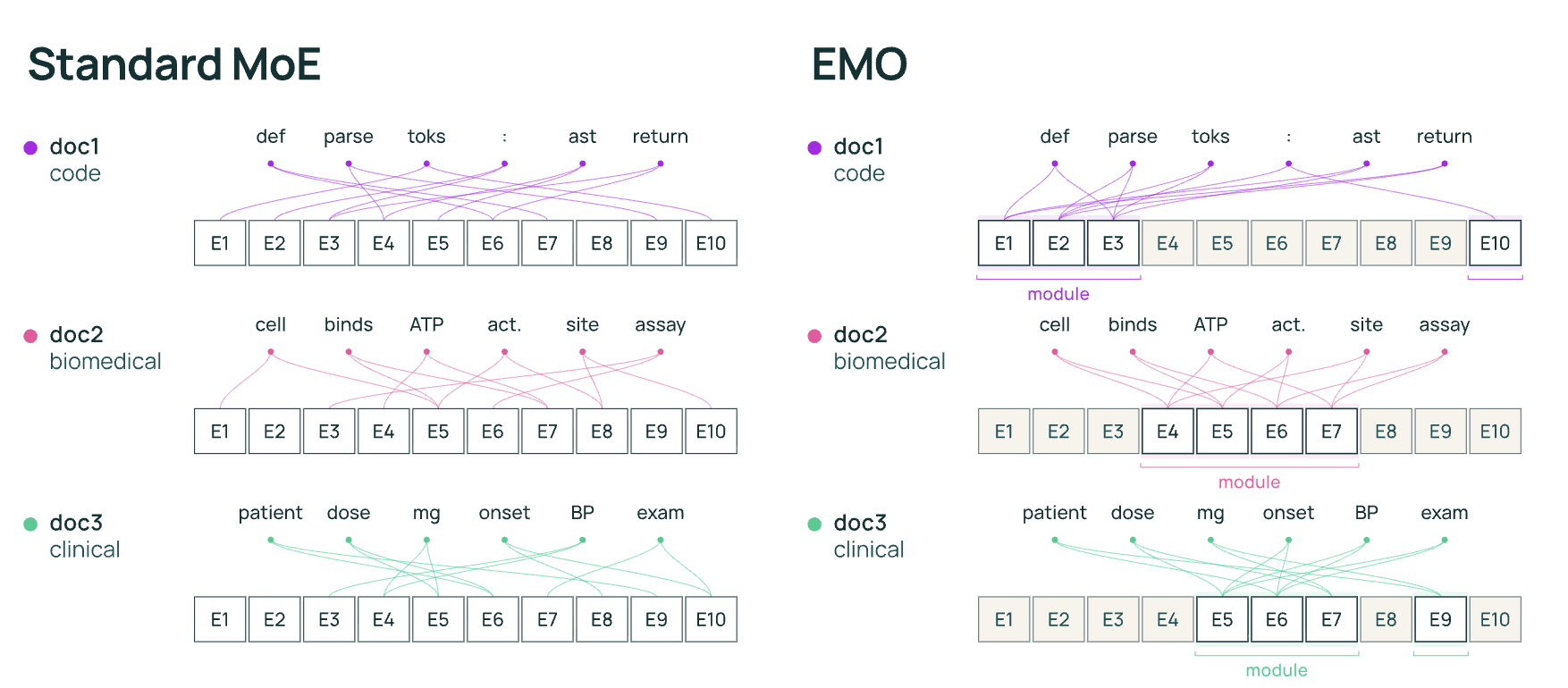
이러한 현상이 나타나는 이유가 무엇일까요? 실제 Routing 패턴을 분석해보면, Expert이 각자 전문성을 띠고 있긴 합니다. 다만 그 기준이 우리가 원하는 방향이 아니었을 뿐입니다. 기존 MoE에서 Expert은 표층적인 문법/어휘 패턴에 특화되어 있습니다. 전치사(of, in, for, to) 담당 Expert, 관사/소유격(the, my, your) 담당 Expert, 동사 담당 Expert, 숫자 담당 Expert... 이런 식이죠. 실제로 Mixtral이나 OLMoE를 분석한 논문에서 이 패턴이 일관되게 발견됩니다.
이것이 왜 문제가 될까요? 전치사와 관사는 코딩 문서에도, 의학 문서에도, 뉴스 기사에도 다 나옵니다. 어떤 도메인의 문서를 처리하더라도 결국 비슷한 Expert가 활성화될 수밖에 없는 겁니다. 코딩 문서의 def, return, class 같은 토큰은 코딩 Expert를 쓰겠지만, 그 사이사이의 the, of, is, :, . 같은 토큰이 전혀 다른 Expert를 마구잡이로 호출합니다. 한 문서를 처리하다 보면 결국 128개 중 대부분의 Expert가 적어도 한 번씩은 쓰이게 됩니다.
결론적으로, 기존 MoE는 토큰 단위의 Sparsity(선택적 활성화)는 달성했지만, 도메인 단위의 Modularity(역할 분리)는 없었습니다. 전자는 “한 토큰을 처리할 때 일부 Expert만 쓴다”는 것이고, 후자는 “한 도메인을 처리할 때 일부 Expert만 쓴다”는 것입니다. 우리가 원했던 건 후자인데, 실제로 구현된 건 전자뿐이었던 겁니다. 물론 사후적으로 좋은 Expert를 골라내려는 시도도 있었지만, 이것도 결국 큰 효과가 없었습니다. Modularity는 사후에 발견되는 것이 아니라 처음부터 학습되어야 한다는 방향이 굳혀진 이유입니다.
MoE의 한계에 대해 더 궁금하신 분은 이전에 발간된 뉴스레터를 참고해주세요. |
|
|
“처음부터 도메인별로 Expert를 학습시키면 되지 않나?”라는 생각도 자연스럽게 드실 수 있는데요. 실제로 이 방향의 선행 연구가 있습니다. FlexOlmo나 BTX 같은 방법은 학습 데이터를 수학/코드/의학 등으로 미리 나눠서, 각 도메인 전용 Expert를 별도로 학습한 뒤 합치는 방식입니다.
이 접근법에는 세 가지 문제가 있습니다. 첫째, 수조 개에 달하는 사전 학습 데이터에 도메인 레이블을 붙이는 건 비용이 크고, 붙이더라도 사람의 편향이 들어갑니다. 둘째, 도메인 정의 자체가 임의로 이루어집니다. ‘의학’과 ‘생명과학’의 경계를 어떻게 칼같이 나눌 수 있을까요? 셋째, 고정된 도메인 체계는 추론 시 새로운 도메인에 대응하기 어렵습니다.
EMO 연구진은 이 모든 것을 우회합니다. EMO의 출발점은 단순한 관찰에서 이루어졌습니다. 연구진은 “도메인 레이블은 없어도 된다. 같은 문서 안의 토큰은 어차피 같은 도메인에서 왔을 가능성이 높다. 문서 경계(Document Boundary)가 약한 도메인 신호 역할을 할 수 있다.”라고 생각했죠.
이를 바탕으로 한 학습 방식은 다음과 같습니다. 매 문서마다, 그 문서의 모든 토큰이 공통으로 쓸 Expert Pool을 먼저 정합니다. 그러면 그 문서의 모든 토큰은 해당 Pool 안에서만 Expert를 선택합니다. 다른 문서는 다른 Pool을 가질 수 있습니다. 구체적으로 어떻게 Pool을 정할 수 있을까요? 처음에는 각 토큰이 자유롭게 선택했을 때 어떤 Expert를 선호하는지 보고, 그 평균을 내서 상위 d개 Expert를 해당 문서의 Pool로 정합니다. 그리고 이후 Routing은 이 Pool 안에서만 이루어집니다. 이 과정에서 도메인 레이블은 전혀 필요 없습니다. “이 문서는 코딩 관련이다”라고 누가 알려주지 않아도, 코딩 문서가 비슷한 Expert Pool을 반복적으로 선택하다 보면 자연스럽게 해당 Expert가 코딩에 특화됩니다. 의학 문서가 의학 관련 Expert Pool을 선택하고, 뉴스 기사는 또 다른 Pool을 선택합니다. 이 패턴이 수조 개의 토큰 학습을 거치면서 고착화합니다. |
|
|
이렇게 간단한 아이디어가 있음에도 불구하고, EMO를 학습시킬 때 기술적으로 까다로운 부분이 있었습니다. MoE 학습에는 Load Balancing Loss라는 보조 목적 함수가 필요합니다. 이 목적 함수는 모든 Expert가 고르게 쓰이도록 유도하는 역할을 합니다. 특정 Expert에만 토큰이 몰리면 해당 Expert만 학습이 되고 나머지는 낭비되기 때문입니다.
문제는 이 Load Balancing이 EMO의 문서 레벨의 Routing 제약과 정반대 방향으로 작동한다는 겁니다. Load Balancing은 “같은 미니배치 안에서 모든 Expert를 골고루 써라”라고 하고, EMO의 Routing 제약은 “같은 문서 안에서는 같은 Pool만 써라”라고 합니다. 같은 문서 안에서는 Expert를 모아야 하는데, Load Balancing은 그걸 흩어버리려 하는 것이죠.
해결책은 Load Balancing의 범위를 넓히는 것입니다. 미니배치 단위가 아니라 전체 Data-parallel Group에 걸쳐 Routing 통계를 집계해서 Load Balancing을 계산합니다. Global Load Balancing이라고 불리는 이 방식을 사용하면, 훨씬 다양한 도메인의 문서에 걸쳐 Expert 활용을 균등하게 유지하면서, 동시에 각 문서 내에서는 Expert를 모을 수 있습니다.
또 다른 문제로는 Pool의 크기가 있습니다. 만약 Pool 크기 d를 고정하면, 모델이 그 크기에만 최적화되어버립니다. 32개로 고정하면 32개를 사용할 때는 잘 되지만, 8개나 64개로 추론하면 성능이 뚝 떨어집니다. 그래서 EMO는 매 문서마다 d를 랜덤하게 샘플링합니다. 덕분에 배포 환경에 따라 메모리 예산이 달라져도, Expert 수를 유연하게 조절하면서 성능을 유지할 수 있습니다. |
|
|
EMO는 전체 모델로 평가했을 때 표준 MoE와 동등한 성능을 보입니다. 1조 토큰으로 학습한 경우, MMLU, MMLU-Pro, MC9, Gen5, GSM8K 전반에 걸쳐 수치가 거의 같습니다. Modularity를 위해 성능을 희생하지 않았다는 뜻입니다.
이 결과는 그 자체로 의미가 있습니다. 같은 문서 안에서 Expert Pool을 제한했을 때, 모델의 표현력이 떨어질 것이라는 우려가 있었기 때문입니다. 그런데 실험 결과, 문서 경계라는 약한 신호만으로도 충분한 구조를 유도할 수 있었습니다. |
|
|
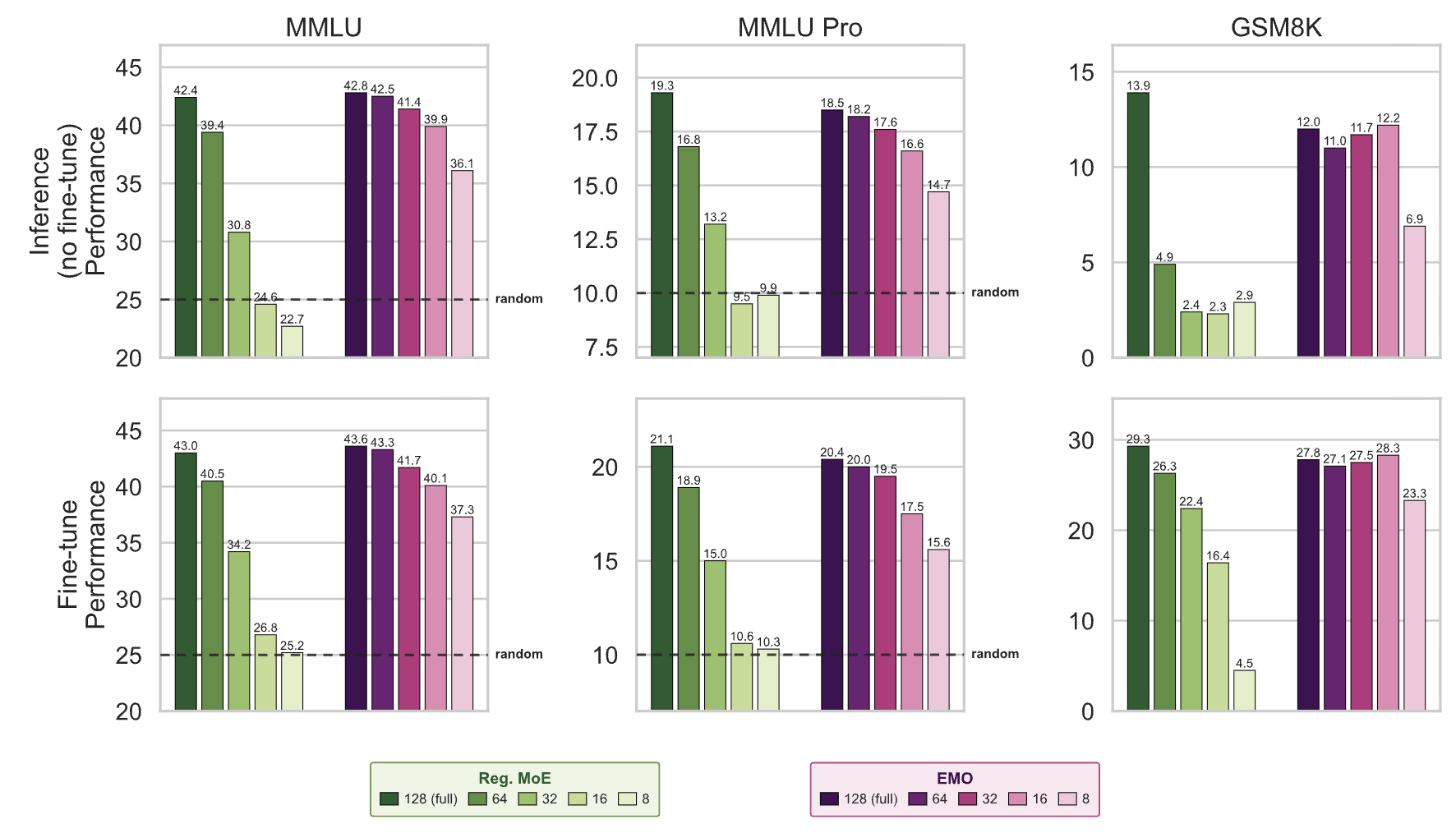
표준 MoE와 EMO의 Expert subset별 성능 비교.
|
|
|
Expert Subset 평가에서 중요한 결과가 등장합니다. 도메인별로 소수의 Expert만 남기고 나머지를 버렸을 때 성능이 얼마나 유지되는지 확인해보았을 때, 표준 MoE는 128개에서 32개(25%)로 줄이면 성능이 MMLU 기준 약 11.6% 낮아지며, 16개(12.5%)로 줄이면 17.8%, 8개로 줄이면 사실상 랜덤 수준까지 떨어지는 것을 확인하였습니다. 반면 EMO는 Expert를 128개에서 32개로 줄이면 약 1.4%, 16개로 줄이면 약 3.9%, 8개로 줄이면 6.7% 성능 저하에 그칩니다. 그리고 이 EMO의 8-Expert 부분집합이, 처음부터 8개 Expert만 갖도록 학습한 Dense 모델보다 성능이 좋습니다. 즉 큰 모델 하나를 잘 학습해두면, 그 안에서 작은 모델 여러 개를 공짜로 얻는 셈입니다.
더 흥미로운 발견은 Routing 패턴 분석에서 나옵니다. 연구팀은 사전 학습 데이터에서 12,000개 문서의 첫 100개 토큰을 샘플링해서 Routing 확률 벡터를 추출하고, 이를 군집화했습니다. 그 결과가 표준 MoE와 EMO 사이에서 극명하게 갈립니다.
- 표준 MoE의 군집 상위 18개: 전치사(of/in/for/to), 관사/소유격(the/my/your), 동사(is/are/was), 숫자/날짜, 접속사(and/or/but), 고유명사, 구두점...
- EMO의 군집 상위 18개: 영화/음악/TV/책 리뷰, 건강/의학/웰니스, 개인 블로그/일상 글, 소스코드, 미국 정치/선거, 비즈니스/마케팅, 뉴스 기사, 생명과학 연구, 종교/철학...
|
|
|
데모를 통해 확인할 수 있는 Routing 패턴 분석 비교 결과.
|
|
|
같은 데이터로 학습했는데, 완전히 다른 분할이 이루어졌다는 점이 보이시나요? 표준 MoE는 "이 단어가 어떤 품사인가"로 나누고, EMO는 “이 문서가 어떤 주제인가”로 나눕니다. 그리고 EMO에서는 같은 문서의 토큰이 대부분 같은 군집에 속합니다. 그림에서 한 문서의 토큰이 흩어지지 않고 모여 있는 걸 볼 수 있습니다.
이 Semantic Specialization이 얼마나 사람이 해석 가능한지도 검증했습니다. WebOrganizer라는 24개 도메인으로 분류된 2,000만 문서 데이터셋을 사용해서, 각 도메인의 Expert Activation 패턴이 얼마나 비슷한지 측정하기 위해 코사인 유사도로 사용했을 때, 표준 MoE에서는 대부분의 도메인 쌍의 유사도가 0.6 이상으로 높고, EMO에서는 관련 없는 도메인 간 유사도가 0.4 이하로 낮았습니다. 그리고 EMO의 도메인 유사도 구조가 인간의 직관적인 도메인 유사도와 잘 일치했습니다. 예를 들어 보면, software와 software_development는 비슷하고, food_and_dining과 engineering은 다르게 취급되었죠.
EMO 모델 연구가 시사하는 바는 크게 3가지가 있습니다. 지금까지 대형 모델의 배포 효율을 높이는 방법으로는 크게 Quantization, Pruning, Knowledge Distillation 등이 있었습니다. 하지만, EMO가 제안하는 Modular Deployment는 이들과 성격이 다릅니다. 모델을 압축하거나 줄이는 게 아니라, 큰 모델 안에서 작업에 맞는 부분만 선택적으로 로드하는 방식이기 때문이죠. 물론 이 둘을 함께 쓸 수도 있습니다. 모델이 조 단위 파라미터 규모로 커지는 지금, VRAM 문제는 더 심각해지고 있습니다. DeepSeek V4가 1.6조 파라미터이고, MoE 구조 덕분에 토큰당 490억 파라미터만 활성화하더라도, 전체 가중치를 VRAM에 올리려면 여전히 수십 개의 H100이 필요합니다. EMO 방식으로 특정 도메인에 대한 Expert 부분집합만 불러올 수 있다면, 메모리 제약이 있는 환경에서의 배포 가능성이 훨씬 커집니다. |
|
|
💡 다양한 대형 모델 배포 방법과 한계
- Quantization: 파라미터를 FP16 → INT8와 같이 낮은 정밀도로 압축하는 방식입니다. 모델 전체를 올려야 한다는 점은 동일합니다.
- Pruning: 덜 중요한 가중치를 제거하여 모델 크기를 줄이는 방식입니다. 제거된 능력은 복구할 수 없습니다.
- Knowledge Distillation: 큰 모델(교사)의 지식을 작은 모델(학생)에 전달하는 방식입니다. 별도의 소형 모델을 새로 학습해야 합니다.
|
|
|
또 다른 가능성은 추론 시간의 조절입니다. EMO의 Expert 군집 중에는 “스팸, 도박, 성인 콘텐츠” 군집도 있습니다. 아동 대상 서비스라면 이 군집에 해당하는 Expert 부분집합을 추론 시 비활성화하는 방식으로 콘텐츠 필터링을 구현할 수 있습니다. 데이터셋을 필터링하는 것보다 훨씬 세밀한 접근이라고 볼 수 있죠. 반대로, 특정 도메인 Expert만 추가로 학습시켜서 전체 모델에 다시 통합하는 것도 가능합니다. 논문에서 32-Expert 부분집합을 파인튜닝해서 다시 128-Expert 전체 모델에 넣어보는 실험을 했는데, 전체 모델 성능이 어느 정도 개선됐습니다. 전체 모델을 재학습하지 않고 특정 능력을 업데이트하는 방향을 기대해볼 수 있는 결과입니다.
마지막으로 흥미로운 시사점은 해석 가능성입니다. EMO에서 Expert Activation은 모델이 어떤 도메인 지식을 동원하고 있는지에 대한 해석 가능한 신호라고 볼 수 있습니다. 만약 수학 문제를 풀 때 작문 Expert 군집이 강하게 활성화된다면, 그건 무언가 잘못 동작하고 있음을 뜻합니다. Expert Activation을 통해 모델의 동작을 모니터링하고 디버깅하는 인터페이스가 생기는 셈이죠.
|
|
|
EMO가 보여주는 것은 학습의 목적 함수 하나를 바꿨더니, 아무도 알려준 적 없는 도메인 구조가 생겼다는 점입니다. 수조 토큰의 사전 학습 데이터에 도메인 레이블을 붙이지 않고도, 문서 경계라는 이미 있는 신호만으로요. EMO는 복잡한 모델 아키텍처 변경이나 새로운 데이터 파이프라인 없이, Routing에 제약을 거는 것만으로 MoE의 오래된 한계를 해소했습니다. MoE가 스케일링의 주류가 된 지금, 다음 질문은 '어떻게 더 잘 쓸 것인가'입니다. EMO는 그 질문에 사전 학습 단계에서 답하려는 첫 번째 시도였습니다. |
|
|
딥 다이브 뉴스레터 잘 보고 계신가요? 여러분의 의견과 피드백을 받습니다 :) |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|