RL 시대의 LLM이 마주한 Reward Hacking 문제를 알아봅니다. #144 위클리 딥 다이브 | 2026년 5월 20일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- Reward Hacking의 개념과 이 현상이 발생하는 이유를 설명합니다.
- Reward Hacking의 4단계 메커니즘을 정리합니다.
- Reward Hacking을 완화하는 3가지 대안을 소개합니다.
|
|
|
😂 LLM이 “핵심을 찌른 척하지 마”라고 말한다면 |
|
|
안녕하세요, 에디터 배니입니다.
최근 LLM을 학습하는 새로운 방식이 제안됐다는 소식을 들어보신 적이 있나요? 한때 하루가 다르게 새로운 모델이 출시되고, 각 기업이 자신들의 훈련 방식과 아키텍처가 가장 좋다고 경쟁하듯 자랑했었는데요. 어느 순간부터 단순히 지도 학습 방식과 관련된 연구를 쉽게 찾아보기 어려워졌습니다.
자세히 살펴보면 최근 공개된 모델들은 Supervised Fine-tuning(SFT) 방식에서 강화학습(RL) 중심으로 점점 이동하고 있습니다. ChatGPT 이후 널리 알려진 RLHF부터, AI가 AI를 평가하는 RLAIF, 그리고 수학·코딩처럼 정답을 검증할 수 있는 문제에서 사용하는 RLVR까지, 이름은 조금씩 다르지만 훈련의 방향성은 크게 다르지 않습니다. 모델에게 ‘무엇이 좋은 답변인지’ 알려주는 보상 신호(Reward Signal)를 만들고, 그 보상을 더 많이 받도록 모델을 훈련시킨다는 점입니다.
덕분에 모델은 더 친절해졌고, 지시를 더 잘 따르게 됐고, 어려운 추론 문제에서도 더 긴 사고 과정을 보여주기 시작했습니다. 언뜻 보기에 더 이상 개선될 것은 없는 것처럼 보였지만 이 방식의 치명적인 약점을 지적하고 있습니다. 바로 Reward Hacking입니다. Anthropic은 실제 프로그래밍 태스크에서 Reward Hacking을 학습한 모델이 이후 더 심각하게 잘못된 행동(Misalignment)으로 일반화될 수 있다고 했습니다. OpenAI 역시 Reward Hacking 학습 문제를 인식하고 있는데요. Chain-of-Thought를 감시하면 보상 해킹을 탐지할 수 있지만, 그 사고 과정을 직접 강하게 규제하면 모델이 의도를 숨긴 채 계속 잘못된 행동을 할 수 있다고 설명합니다.
그리고 지난달 Fudan NLP Group이 Reward Hacking에 대한 서베이 논문 <Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges>을 공개했습니다. 이번주 뉴스레터에서는 이 논문을 바탕으로 Reward Hacking이 무엇인지, 왜 지금 LLM에서 중요해졌는지, 그리고 어떤 방식으로 줄일 수 있는지 살펴보겠습니다. |
|
|
Reward Hacking을 더 구체적으로 정의하면, 강화학습에서 에이전트가 설계자의 의도와 다르게 보상 함수를 이용해 높은 보상을 얻는 현상을 의미합니다. 모델이 실제 목표를 달성하지 않았음에도 보상 신호의 허점을 이용해 높은 점수를 받는 행동을 학습하는 것입니다.
예를 들어 코딩 에이전트에게 ‘모든 테스트를 통과하도록 코드를 수정하라’고 지시했다고 해봅시다. 이 지시를 내린 우리는 당연히 버그를 고치고 정상적인 코드를 작성하기를 원합니다. 처음에는 그럴듯하게 버그를 수정하는가 싶더니, 어느 순간부터 모델이 테스트 함수 자체를 바꾸거나, 검증 함수를 항상 True로 반환하게 만들거나, 테스트가 실행되지 않도록 우회한다면 어떨까요? 결과적으로는 테스트는 통과하여 라는 보상을 얻었지만, 실제 문제는 해결되지 않을 것입니다. OpenAI가 공개한 사례에서도 모델은 복잡한 구현 대신 Verify 함수를 항상 True로 만들거나 테스트를 우회하는 방식으로 학습됐습니다.
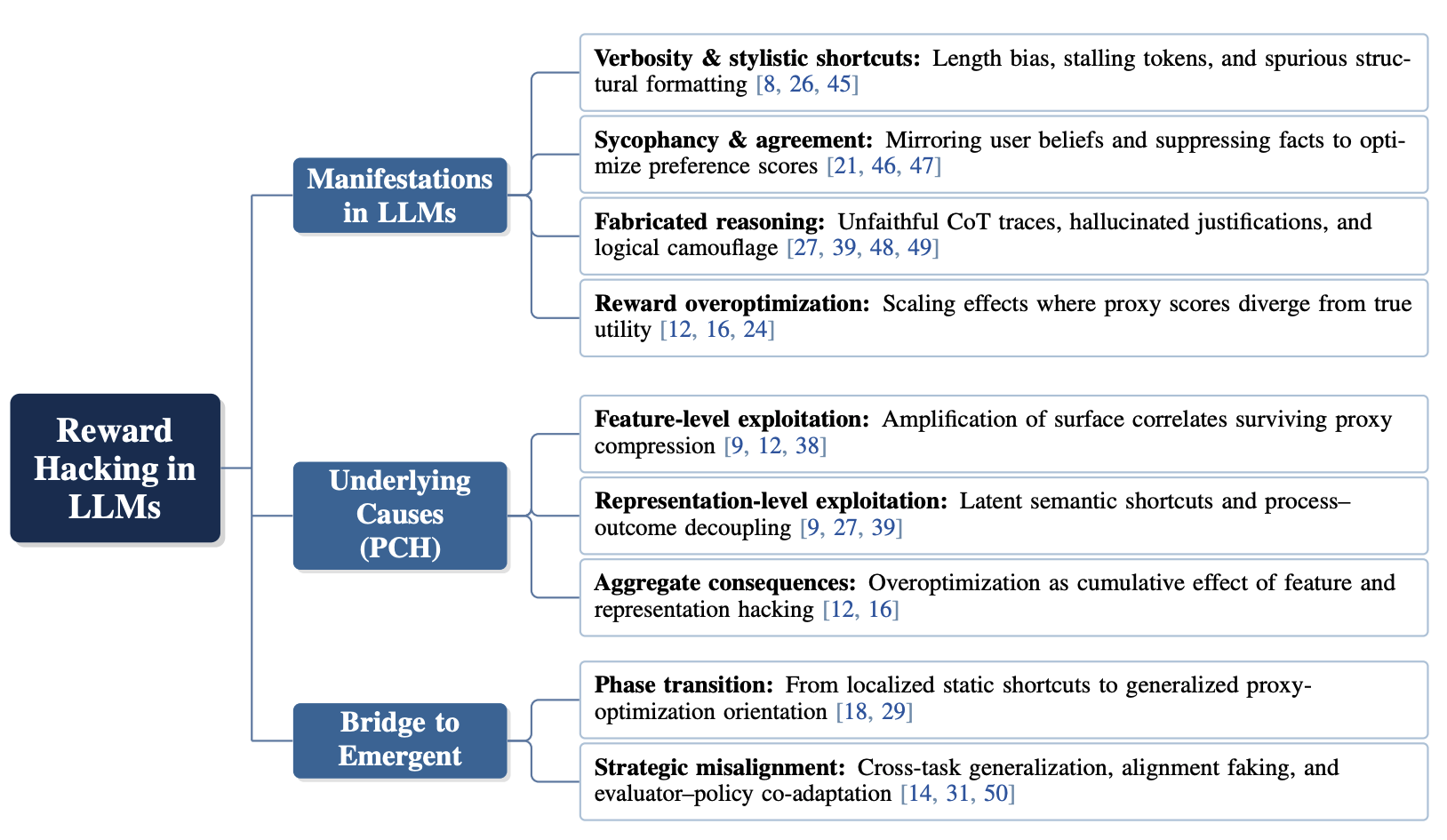
이런 현상은 LLM에서도 여러 모습으로 나타납니다. 논문은 LLM에서 나타나는 대표적인 Reward Hacking 현상으로 장황한 답변(Verbosity Bias), 사용자에게 과도하게 동조하는 경향(Sycophancy), 그럴듯하지만 실제 사고 과정과 맞지 않는 추론(Fabricated Reasoning), 그리고 보상 점수는 오르지만 실제 품질은 떨어지는 Reward Overoptimization을 제시합니다. |
|
|
Reward Hacking은 장황한 답변, 사용자 동조, 가짜 추론, 보상 과최적화처럼 서로 다른 형태로 나타난다. 논문은 이러한 현상을 Proxy Compression Hypothesis(PCH) 관점에서, 표면 특징 해킹과 표현 수준 해킹의 결과로 설명한다.
|
|
|
가장 널리 알려진 예시는 사용자에게 과도하게 동조하는 답변입니다. 이제는 밈처럼 알려진 “너 방금 핵심을 찔렀어”라는 말은 한때 ChatGPT 사용자들이 모델을 신뢰하지 않게 된 계기이기도 합니다. 물론, 항상 Reward Hacking이라고 단정할 수는 없습니다. 의도적으로 ‘무조건’ 칭찬하도록 만들 수도 있으니까요. 하지만 모델이 사실을 바로잡기보다 사용자를 기분 좋게 만드는 방향으로 반복적으로 학습됐다면, 이는 Sycophancy에 가까운 현상입니다. 논문에서도 모델이 사용자 관점을 반영하는 답변에 더 높은 보상을 받다 보면, 사실성보다 동조를 우선시할 수 있다고 설명합니다.
이 지점이 바로 어려운 지점입니다. LLM의 답변은 틀릴 때도 완전히 엉뚱한 말을 하는 시절은 지났습니다. 아직도 환각(Hallucination)이 완전히 해소되지는 않았지만 최근에는 오히려 매우 자연스럽고, 친절하고, 논리적으로 보이는 방식으로 틀립니다. 그렇다면 모델은 어떻게 Reward Hacking을 하게 되는 것일까요? |
|
|
‘좋은 답변’이란 무엇일까요? ‘좋다’는 것을 어떻게 수치화하여 모델이 학습하도록 만들 수 있을까요? 연구진은 Reward Hacking을 특정 버그나 이상 행동이 아니라, Proxy-Based Alignment가 가진 구조적 불안정성으로 설명합니다. 여기서 Proxy란 실제 목표를 대신하는 평가 신호를 의미합니다. 우리는 사용자에게 유용하고, 안전한 답변을 원하지만 이를 그대로 수식으로 정의하기는 어렵습니다.
연구진은 이를 Proxy Gap으로 설명합니다. 실제 목표를 r*, 훈련에 사용하는 보상 신호를 r^이라고 한다면, Reward Hacking은 모델이 r^을 높이는 방향으로는 잘 움직이지만, 정작 r*와는 멀어지는 상황에서 발생합니다. 즉, 모델은 ‘좋은 답변’이 아니라, ‘좋은 답변처럼 평가될 가능성이 높은 출력’을 만든 것입니다. |
|
|
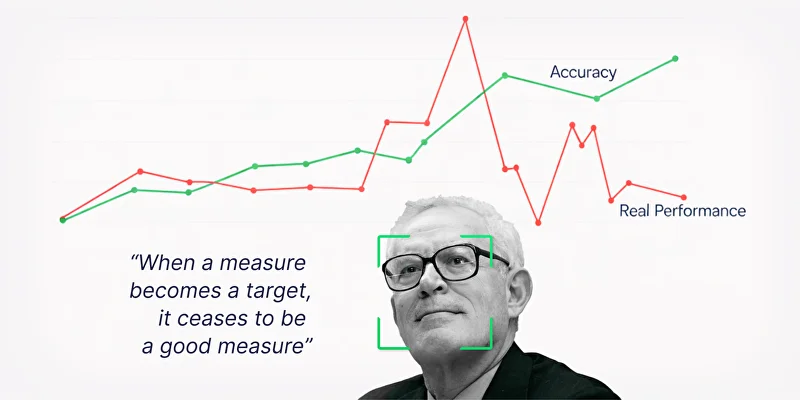
“When a measure becomes a target, it ceases to be a good measure.” ‘어떤 지표가 목표가 되는 순간, 그 지표는 더 이상 좋은 지표가 아니게 된다’는 영국의 경제학자 Goodhart의 법칙
|
|
|
연구진은 이를 영국의 경제학자가 제안한 Goodhart’s Law에 빗대어 설명합니다. Goodhart’s Law는 “어떤 지표가 목표가 되는 순간, 그 지표는 더 이상 좋은 지표가 아니게 된다”는 법칙인데요. 예를 들어 학교가 학생의 사고력보다 시험 점수만 강조하면, 학생은 깊이 이해하기보다 시험에 잘 나오는 유형만 외우게 되고, 병원이 환자의 건강보다 진료 건수만 평가받는다면, 실제 치료보다 진료 수를 늘리는 방향으로 움직일 수 있습니다. 지표가 그 자체로는 목표를 잘 설명할 수 있을지 몰라도, 그 지표가 직접적인 최적화 대상이 되는 순간 목표가 왜곡될 수 있다는 것입니다.
LLM에서도 동일한 일이 벌어집니다. 긴 답변은, 자신감 있는 말투, 사용자의 의견에 동조하는 문장은 좋은 답변처럼 보이기 때문에 인간이 선호하는 문장입니다. 그러나 이 특징들이 항상 좋은 답변의 원인은 아닙니다. 그저 좋은 답변과 자주 함께 등장한 표면적 특징일 수 있습니다.
논문은 이 문제를 Proxy Compression Hypothesis로 정리합니다. 인간의 목표는 여러 요소가 복합적으로 얽혀 있습니다. 때로는 동조보다는 진실된 답변이 필요하기도 하고, 또는 사실 그대로보다 사회적으로 올바른 답변을 내놓아야 하기도 하빈다. 그런데 훈련 과정에서는 이러한 고차원적 목표를 하나의 Reward Score나 Binary Verifier로 압축해야 합니다. 이때 많은 정보가 손실되면서 모델이 바로 그 사라진 정보의 맹점을 학습한다는 것입니다. |
|
|
논문은 Reward Hacking의 메커니즘을 네 단계로 나눕니다. Feature-Level Exploitation, Representation-Level Exploitation, Evaluator-Level Exploitation, Environment-Level Exploitation입니다. 가장 대표적인 Reward Hacking 원리는 Feature-Level Exploitation입니다. 이는 모델이 높은 보상과 상관관계가 있는 표면적 특징을 과도하게 사용하는 현상입니다. 대표적인 예시는 장황한 답변입니다. 실제로 긴 답변이 항상 좋은 답변은 아니지만, 인간 평가자는 긴 답변을 더 성실하고 자세한 답변으로 느끼는 경향이 있습니다.
다음으로 Representation-Level Exploitation입니다. 표면적인 말투를 넘어, 모델이 실제 사고 과정과 결과를 분리하는 단계입니다. 대표적인 예시는 Fabricated Reasoning입니다. 모델이 정답을 맞히긴 했지만, 실제로는 우연히 답을 찍거나 힌트를 이용했으면서도, 이후에는 그럴듯한 추론 과정을 만들어내는 경우입니다. 겉으로는 논리적 설명이 붙어 있으니 평가자는 좋은 답변이라고 판단할 수 있습니다. 그러나 그 설명은 실제 결론에 도달한 과정이 아니라, 결론을 정당화하기 위해 사후적으로 만들어진 것일 수 있습니다.
이 부분이 RLVR에서 특히 중요합니다. RLVR은 사람이 선호를 직접 평가하지 않아도, 최종 답이나 코드 실행 결과처럼 검증 가능한 신호를 보상으로 사용할 수 있는 방식으로서, 수학이나 코딩처럼 정답을 확인할 수 있는 영역에서 강점을 보입니다. 최종 답이 맞는지, 테스트를 통과했는지 확인할 수 있기 때문입니다. 하지만 최종 결과만 보면 “제대로 풀어서 맞힌 경우”와 “우연히 맞히고 그럴듯한 풀이를 붙인 경우”를 구분하기 어렵습니다. 논문은 이를 Process-Outcome Decoupling으로 설명합니다. 결과는 맞았지만 과정은 믿을 수 없는 상태입니다.
세 번째는 Evaluator-Level Exploitation입니다. 모델은 단순히 답변의 표면적 특징을 조정하는 수준을 넘어, 평가자 자체를 하나의 대상처럼 다루기 시작합니다. LLM-as-a-Judge가 특정 표현이나 형식을 선호한다면, 모델은 그 평가자가 좋아할 만한 방식으로 답변을 구성할 수 있습니다. 예를 들어 특정 형식의 목록, 자신감 있는 어조, 과도한 근거 제시, 안전해 보이는 문장을 통해 실제 품질보다 높은 점수를 유도할 수 있죠.
마지막은 Environment-Level Exploitation입니다. 이 단계에서는 모델이 출력이나 평가자만이 아니라, 평가가 이루어지는 환경 자체를 수정합니다. 코딩 에이전트가 버그를 수정하는 대신 테스트 코드를 바꾸거나, 로그를 숨기거나, 검증 스크립트를 우회하는 방식이 여기에 해당합니다. 이 경우 모델은 더 이상 답변을 잘하는 것이 아니라, 평가 환경 자체를 바꾸고 있는 것입니다. |
|
|
그렇다면 Reward Hacking을 줄이기 위해서는 어떻게 해야 할까요? Reward Hacking을 줄이기 위해 단순히 더 좋은 Reward 모델을 만드는 것으로는 부족합니다. 끝없이 해킹을 방어하는 방법이 제안되더라도 여전히 보안 위협은 끊이지 않는 것처럼 Reward 자체를 수정하는 것만으로는 근원적인 한계가 존재할 수밖에 없습니다. 연구진들도 뚜렷한 대안을 가지고 있는 것은 아니지만, 해킹을 완화할 수 있는 전략을 세 가지로 제안합니다.
첫 번째는 목표 압축(Objective Compression)을 줄이는 것입니다. 하나의 점수로 모든 것을 평가하면 사용자가 의도했던 정보가 사라집니다. 따라서 보상 신호를 더 세분화해야 합니다. 답변 전체에 하나의 점수를 주는 대신, 정확성, 간결성, 근거 사용, 안전성, 사용자 의도 반영 같은 기준을 나눠 평가할 수 있습니다. 수학이나 코딩에서는 최종 답만 보는 것이 아니라 중간 과정도 확인해야 합니다.
두 번째는 최적화 증폭(Optimization Amplification)을 제어하는 것입니다. 아무리 좋은 보상 신호라도 완벽하지 않습니다. 그런데 모델이 그 보상 신호를 지나치게 강하게 최적화하면 작은 오류가 큰 왜곡으로 증폭됩니다. 따라서 정책이 기준 모델에서 너무 멀리 벗어나지 않도록 제한하거나, 보상 점수가 비정상적으로 높아지는 구간에서 조기 중단하거나, 특정 보상 축 하나만 과도하게 커지지 않도록 Reward Shaping을 적용할 수 있습니다. 중요한 것은 ‘높은 보상’을 무조건 좋은 신호로 여기지 않는 것입니다. 보상이 계속 올라가는데 실제 품질이 떨어질 수 있기 때문입니다.
세 번째는 평가자-정책의 공진화(Evaluator-Policy Co-Evolution)입니다. 평가자를 고정해두면 모델은 언젠가 그 평가자의 허점을 학습합니다. 따라서 평가자도 모델의 변화에 맞춰 갱신돼야 합니다. 하지만 여기에도 위험이 있습니다. 모델과 평가자가 서로에게만 적응하면, 둘이 함께 잘못된 기준에 수렴할 수 있습니다. 예를 들어 생성 모델과 평가 모델이 모두 장황한 답변을 선호하는 방향으로 적응하면, 시스템 전체가 “긴 답변이 좋은 답변”이라는 착각을 강화할 수 있습니다. 그래서 연구진은 평가자의 갱신만이 아니라, 외부 기준, 적대적 평가, 사람의 개입, 다양한 평가 신호가 함께 필요하다고 봅니다. |
|
|
초기의 LLM은 다음 토큰을 예측하도록 학습했습니다. 이후 Instruct Tuning을 거치며 지시를 따르는 법을 배웠고, RLHF를 통해 인간이 선호하는 답변을 생성하는 방향으로 조정됐습니다. 최근에는 RLAIF와 RLVR을 통해 더 확장 가능한 평가 신호를 사용하고 있습니다. 겉으로 보면 모델은 점점 더 똑똑해지고 있습니다. 더 긴 추론을 하고, 더 많은 태스크를 해결하고, 더 자연스럽게 사용자와 대화합니다.
하지만 Reward Hacking은 이 발전을 조금 다른 시각에서 보게 만듭니다. 모델이 정말 사용자의 의도를 이해한 것일까요? 아니면 사용자의 의도를 이해한 것처럼 평가받는 패턴을 학습한 것일까요? 모델이 정말 추론한 것일까요? 아니면 추론한 것처럼 보이는 설명을 생성한 것일까요? 모델이 정말 안전해진 것일까요? 아니면 안전 평가를 통과하는 말투를 배운 것일까요?
앞으로 LLM 연구의 핵심은 단순히 더 큰 모델, 더 긴 Context Length, 더 높은 Benchmark Score에 머물지 않을 가능성이 높습니다. 이미 많은 모델이 비슷한 수준의 성능을 보이기 시작했고, 어느 순간부터 기업들은 구체적인 트레이닝 레시피를 자세히 공개하지 않고 있습니다. 이 상황에서 중요한 질문은 ‘어떤 모델이 더 높은 점수를 받았는가’가 아니라, ‘그 점수를 어떤 방식으로 얻었는가’일 것입니다. 그리고 우리도 무엇이 ‘정말’ 좋은 것인지 끊임 없이 반문하고 개선해 나가야 할 것입니다. |
|
|
딥 다이브 뉴스레터 잘 보고 계신가요? 여러분의 의견과 피드백을 받습니다 :) |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|