Nemotron-Personas-Korea 데이터셋의 구조와 핵심 특징을 요약했습니다. #142 위클리 딥 다이브 | 2026년 5월 6일
에디터 스더리 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- Nemotron-Personas-Korea 데이터셋의 구조와 핵심 특징을 요약했습니다.
- PGM과 LLM을 결합해 700만 개의 페르소나를 생성하는 과정을 정리했습니다.
- 이 데이터가 AI 모델 학습과 활용에 갖는 의미와 가능성을 소개했습니다.
|
|
|
👯♂️ AI가 만든 700만 명의 한국인, 진짜 같을까? |
|
|
안녕하세요! 에디터 스더리입니다 :)
AI는 사람을 어떻게 이해할까요? 오늘날의 언어모델은 방대한 텍스트를 학습하며 사람의 말과 지식을 흉내 낼 수 있게 되었지만, 그 안에서 '사람'은 종종 하나의 평균적인 이미지로 축소되곤 합니다. 그런데 '평균적인 사람'이라는 개념은 생각보다 현실과 거리가 있습니다. 하나의 예로, 평균적인 조건들을 모아 키와 직업, 급여, 생활 방식이 모두 ‘평균’인 한 사람을 떠올려 봅시다. 막상 그런 사람을 구체적으로 떠올려 보면, 실제로는 잘 그려지지 않습니다. 설령 떠오른다 하더라도, 그 인물을 한국 사회를 대표하는 사람이라고 보기는 어렵습니다.
그렇다면 AI는 이러한 ‘평균’이 아니라, 실제로 존재하는 다양한 사람들을 어떻게 배울 수 있을까요? 최근 NVIDIA가 공개한 Nemotron-Personas-Korea는 이 질문에서 출발한 데이터셋으로, 평균적인 ‘한 사람’이 아닌 사회 전체의 다양성을 반영하려는 시도입니다. 이제 이 데이터셋이 어떻게 만들어졌는지, 그리고 어떤 의미를 가지는지 살펴보겠습니다. |
|
|
Nemotron-Personas-Korea는 한국 사회의 인구 통계 분포를 기반으로 다양한 사람들을 생성한 합성 페르소나 데이터셋입니다. 지금까지 한국어 LLM 학습에 쓰인 페르소나 데이터는 대부분 영어 데이터를 번역한 형태였습니다. 이로 인해 데이터의 분포 자체가 영어권 사회를 바탕으로 형성되어, 한국 사회의 인구 구성이나 문화적 맥락까지 충분히 담아내기에는 한계가 있었습니다. Nemotron-Personas-Korea는 이를 해결하기 위해 출발점을 바꾸는 방식을 택했습니다. 번역이 아닌, 국가통계포털(KOSIS), 대법원, 국민건강보험공단(NHIS) 등 한국의 공공 통계를 바탕으로 데이터를 구성한 것입니다.
약 100만 명에 이르는 페르소나로 구성된 이 데이터셋에서, 각 페르소나는 나이·성별·지역·직업 같은 속성에 생활 방식과 취향 등의 정보가 더해져 하나의 인물로 표현됩니다. 다음은 Nemotron-Personas-Korea 중 하나의 페르소나 예시입니다.
이다연 씨는 제주시의 한 식당에서 서빙하며 보건복지 전공 지식을 살려 거동이 불편한 어르신들의 식사 수발을 세심하게 돕습니다. 이다연 씨는 직장 동료들과 갈등 없이 원만한 관계를 유지하며 주어진 일만 묵묵히 해내는 평온한 직장 생활을 지향합니다.
이러한 통계 기반의 접근 덕분에 Nemotron-Personas-Korea는 한국 사회의 다양성을 보다 세밀하게 반영합니다. 17개 광역시·도와 252개 이상의 기초자치단체, 약 2,000개의 직업, 20만 개가 넘는 고유 이름을 포함하며, 연령 또한 19세부터 99세까지 폭넓게 분포합니다.
실제로 한 분석에 따르면, 이 데이터셋의 인구 구조는 한국 사회의 실제 통계와 정밀하게 맞물립니다. 연령 분포는 50~64세 베이비붐 세대가 가장 두꺼운 항아리형으로 저출산·고령화의 현실을 그대로 반영하고, 80~89세 구간에서는 여성 비율이 남성의 약 1.52배에 이를 만큼 기대 수명 차이까지 드러납니다.
성씨 또한 김·이·박·정·최 다섯 성씨가 전체의 약 54%를 차지하며, 가장 흔한 이름 역시 실제 통계와 동일하게 '김영숙'으로 나타납니다. 지역별로는 세종시가 대학 학력 이상 비율 1위를 기록하고, 직업 분포에서도 온라인 쇼핑 판매원이 1위를 차지하는 등, 전자상거래 확장과 도시 노동시장의 변화까지 함께 반영됩니다. 즉, 단순히 평균을 흉내 내는 것이 아니라, 한국 사회의 분포와 맥락이 반영되어 있다는 의미입니다.
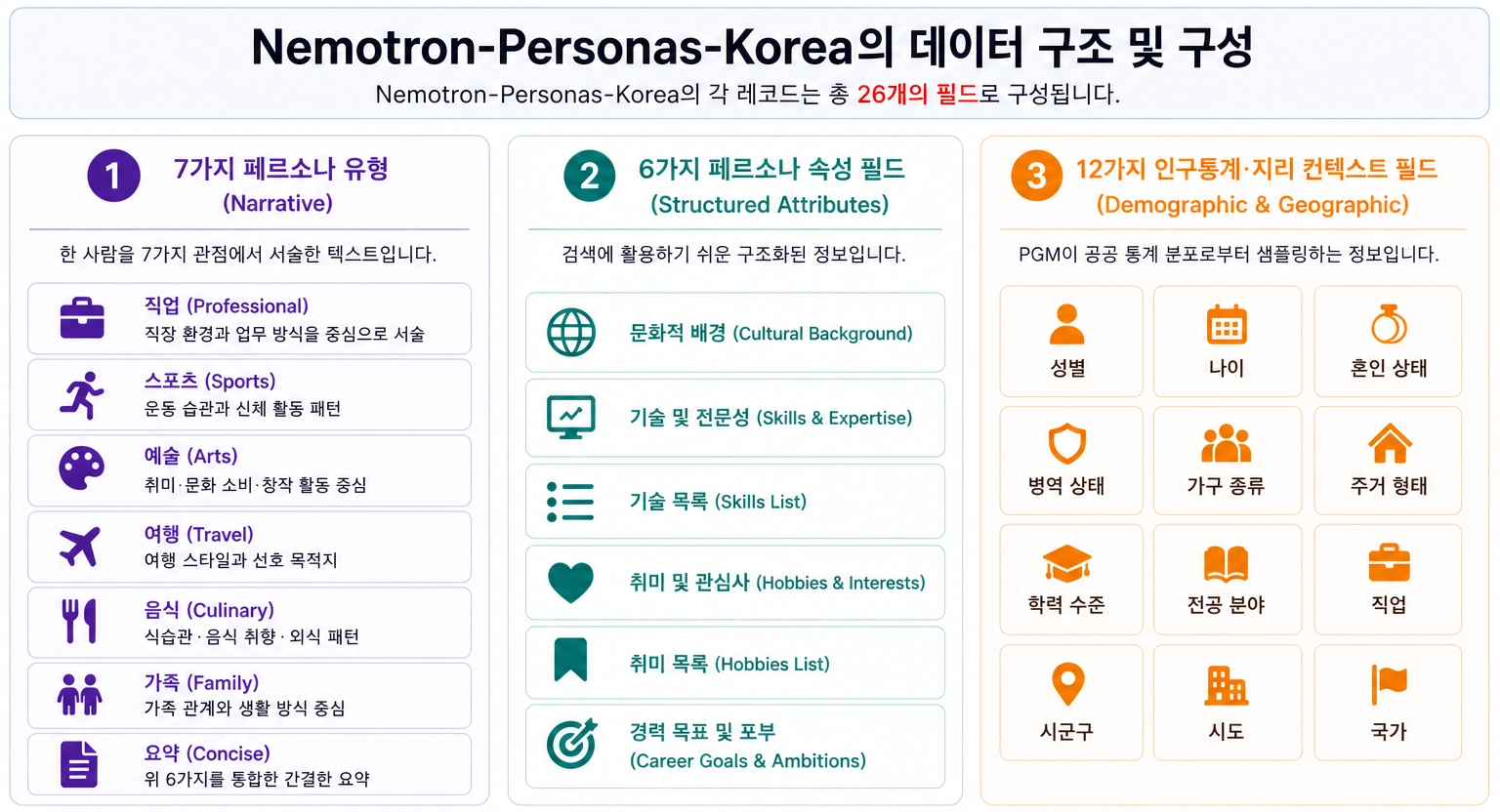
이처럼 통계 위에 한 사람의 일상이 얹힌 페르소나는 일정한 구조를 바탕으로 저장되며, 전체 데이터셋의 구성을 한눈에 정리하면 다음과 같습니다. |
|
|
이처럼 현실의 맥락을 반영하려는 설계와 함께, 데이터 활용 측면에서도 주목할 만한 특징이 있습니다. 이 데이터셋은 CC BY 4.0 라이선스로 공개되어 있어, 출처를 표기하면 상업적 활용까지 자유롭게 가능합니다. 또한 모든 페르소나는 실제 인물이 아닌 통계 기반으로 생성된 합성 인물이기 때문에, 개인정보(PII)가 포함되지 않으며 한국 개인정보 보호법(PIPA)을 고려해 설계되었습니다. |
|
|
그렇다면 이러한 700만 명의 페르소나는 통계로부터 어떻게 만들어졌을까요? Nemotron-Personas-Korea를 만든 도구는 NVIDIA의 오픈소스 합성 데이터 시스템 NeMo Data Designer입니다. 이 시스템은 통계의 정합성은 확률 그래프 모델(PGM)에, 자연어 생성은 LLM에 맡기는 분업 구조로 설계되었습니다.
먼저 사람의 ‘속성’을 만드는 단계가 있습니다. 여기서는 PGM이 사용됩니다. PGM은 KOSIS·NHIS 같은 공공 통계로부터 변수 간의 의존 관계를 학습합니다. 단순히 연령, 성별, 지역, 직업 같은 요소를 각각 따로 뽑는 것이 아니라, 결합 분포(Joint Distribution)에서 함께 샘플링한다는 점이 중요합니다. 예를 들어, 30대·의사·박사라는 속성을 각각 따로 뽑는 것이 아니라, 그러한 조합이 실제로 얼마나 존재하는지를 반영해 생성하는 방식입니다. 이를 통해 생성된 인구통계 레코드는 한국 사회의 구조를 보다 자연스럽게 따르게 됩니다.
이 과정으로 약 100만 건의 구조화된 인구통계 레코드가 만들어지지만, 아직은 숫자와 속성의 조합에 머물러 있어 ‘페르소나’라고 부르기는 어렵습니다. 통계적으로 타당한 구조에서 인간적인 서사로 변환되는 단계가 필요한 것이죠.
여기서 LLM이 등장합니다. 대규모 언어모델인 Gemma-4-31B는 PGM이 만든 인구통계 레코드들을 서로 다른 관점을 반영한 7가지 페르소나 서술로 확장합니다. 이 과정에서 존댓말과 반말의 구분, 상황에 따른 말투 변화, 한국식 관계 표현까지 함께 반영됩니다. 이후 NeMo Data Designer 내 검증 및 품질 평가를 거치고 최종적으로 700만 개의 텍스트(약 17억 토큰)가 생성됩니다.
만약 PGM 없이 LLM만으로 페르소나를 생성한다면 어땠을까요? Tencent의 Persona Hub(2024)처럼 대규모 데이터 생성은 가능하지만 분포 정합성이 보장되지 않습니다. 서울의 20대 IT 종사자처럼 자주 등장하는 패턴은 과도하게 반복되고, 드문 집단은 상대적으로 쉽게 사라지게 되는 것이죠. 반대로 PGM만으로는 자연어 서사를 생성할 수 없습니다. 이처럼 Nemotron-Personas-Korea는 ‘분포의 정확성’과 ‘서사의 자연스러움’을 동시에 확보하기 위해 두 모델을 결합한 구조라고 볼 수 있습니다. |
|
|
💡 Persona Hub (2024)
Tencent AI Lab가 2024년에 공개한 약 10억 명 규모의 합성 페르소나 데이터셋입니다. 웹 텍스트에서 인물 묘사를 추출하거나(Text-to-Persona), 추출된 페르소나 간의 관계를 따라 새로운 페르소나로 확장(Persona-to-Persona)하는 방식으로 만들어집니다. 페르소나의 분포는 웹 데이터와 LLM의 생성 패턴을 따라가기 때문에, 실제 인구 통계와의 정합성은 별도로 보장되지 않습니다. |
|
|
이렇게 만들어진 700만 명의 페르소나는 어떻게 활용될 수 있을까요?
가장 직관적인 활용은 에이전트의 시스템 프롬프트에 적용하는 방식입니다. 최근에는 응답의 맥락을 설정하기 위해 페르소나를 정의하는 것이 하나의 기본적인 단계로 자리 잡았습니다. 하나의 페르소나를 넣는 것만으로도 모델의 응답이 그에 맞게 조정되기 때문입니다. 특히 요약(Concise) 페르소나는 여러 속성과 서사를 하나로 압축해 표현하기 때문에, 실제 서비스에 바로 적용하기에 적합한 형태입니다.
다음으로, 모델 학습 단계에서의 다양성 확장에 활용될 수 있습니다. 페르소나별로 서로 다른 Instruction 데이터를 구성하면, 모델은 다양한 관점에서 학습할 수 있게 됩니다. 늘 서울의 20대 IT 종사자처럼 비슷한 시점으로 답하던 모델이, 부산의 60대 자영업자나 강원도의 50대 농업인 시점에서도 응답할 수 있게 되는 것이죠. 이러한 Demographic-aligned Persona Conditioning(인구 분포 기반 페르소나 학습)은 모델의 응답 다양성과 일반화 성능을 높이는 데 기여합니다. |
|
|
더 나아가, LLM 기반 사회 시뮬레이션이 있습니다. 정책 설계, 사용자 반응 예측, 시장 조사 같은 영역에서 ‘실제 한국 인구를 닮은 가상 응답자 집단’을 구성할 수 있다는 의미입니다. 한 연구에 따르면, 인구 분포에 정합한 페르소나로 조건을 부여했을 때 사회 시뮬레이션에서 모델의 응답이 실제 인구의 반응과 어긋나는 정도가 모델에 따라 약 37.9~49.8% 감소하는 결과가 보고되었습니다. 단순히 그럴듯한 사람을 만드는 것을 넘어, 실제 분포에 가까운 실험이 가능해진 것이죠.
마지막으로, 모델 평가에도 활용될 수 있습니다. 다양한 인구 집단을 반영한 입력을 구성하면, 모델이 특정 집단에 편향되지 않고 공정하게 응답하는지를 측정하는 Demographic Fairness Benchmark의 기반이 될 수 있습니다.
이러한 활용 가능성은 한국이라는 맥락에서 더 큰 의미를 갖습니다. 2025년 한국 정부가 약 240억 원을 투입해 출범한 Sovereign LLM 컨소시엄(NAVER, SKT, LG AI Research, NC AI, Upstage)과 HyperCLOVA X·SOLAR 같은 한국어 모델들은 모두 한국적 맥락에 정합한 데이터를 필요로 하기 때문입니다. CC BY 4.0 라이선스로 공개된 700만 페르소나는 이러한 흐름에 곧바로 투입할 수 있는 보기 드문 자산입니다. |
|
|
합성 데이터로 사람을 그려내는 일에는 분명한 한계가 있습니다. PGM은 일부 변수 간의 독립을 가정하기 때문에 한국 사회의 복합적인 결합까지 모두 담아내지는 못하고, 자연어 서사 생성을 맡은 LLM 역시 영어 중심 학습에서 비롯된 미세한 편향을 완전히 벗어나기 어렵습니다. 여기에 통계 기반 접근의 특성상 통계적 소수 집단이 비례에 비해 적게 표현되거나, 통계 자체가 시점에 따라 변하면서 데이터가 시간이 지나면 현실과 어긋나게 되는 문제도 함께 존재합니다.
그럼에도 불구하고 Nemotron-Personas-Korea는 단순한 합성 데이터셋을 넘어, 한국 사회의 분포와 맥락을 반영한 고품질 학습 자원입니다. 이제 한국 사회의 다양한 사람들이 한국어 AI가 학습하는 세계 안으로 들어오기 시작했습니다. 평균이 아닌 현실을 학습하는 한국어 AI의 다음 장이 시작된 것입니다. |
|
|
딥 다이브 뉴스레터 잘 보고 계신가요? 여러분의 의견과 피드백을 받습니다 :) |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|