1M Context Length를 지원하는 DeepSeek V4에 적용된 기술을 알아봅니다. #141 위클리 딥 다이브 | 2026년 4월 29일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- DeepSeek V4의 100만 토큰 Context Length가 어떤 의미를 갖는지 정리합니다.
- DeepSeek V4에 반영된 mHC와 CSA + HCA Hybrid Attention Architecture를 설명합니다.
- DeepSeek V4가 에이전트 시대에 어떤 변화를 만들 수 있을지 예상해봅니다.
|
|
|
안녕하세요, 에디터 배니입니다.
DeepSeek가 다시 돌아왔습니다. 지난해 3월 DeepSeek 쇼크라는 말이 등장할 정도로 AI 업계를 흔들었던 DeepSeek가 지난 24일 DeepSeek V4를 공개했습니다. 이번 DeepSeek V4는 DeepSeek V3 공개 이후 약 1년 4개월 만에 등장한 새로운 세대의 모델입니다.
DeepSeek V4는 DeepSeek-V4-Pro와 DeepSeek-V4-Flash 두 가지 모델로 출시됐습니다. DeepSeek-V4-Pro는 총 1.6T 파라미터, 49B 활성 파라미터를 사용하는 최고 성능 모델이고, DeepSeek-V4-Flash는 총 284B 파라미터, 13B 활성 파라미터를 사용하는 더 빠르고 경제적인 모델입니다.
이번에 공개된 DeepSeek V4는 명확하게 에이전트를 겨냥하고 있습니다. DeepSeek는 공식적으로 DeepSeek V4가 Claude Code, OpenClaw, OpenCode 같은 주요 AI 에이전트와 통합된다고 설명합니다. 또한 DeepSeek 내부의 에이전틱 코딩에도 이미 사용하고 있다고 밝히기도 했고요. |
|
|
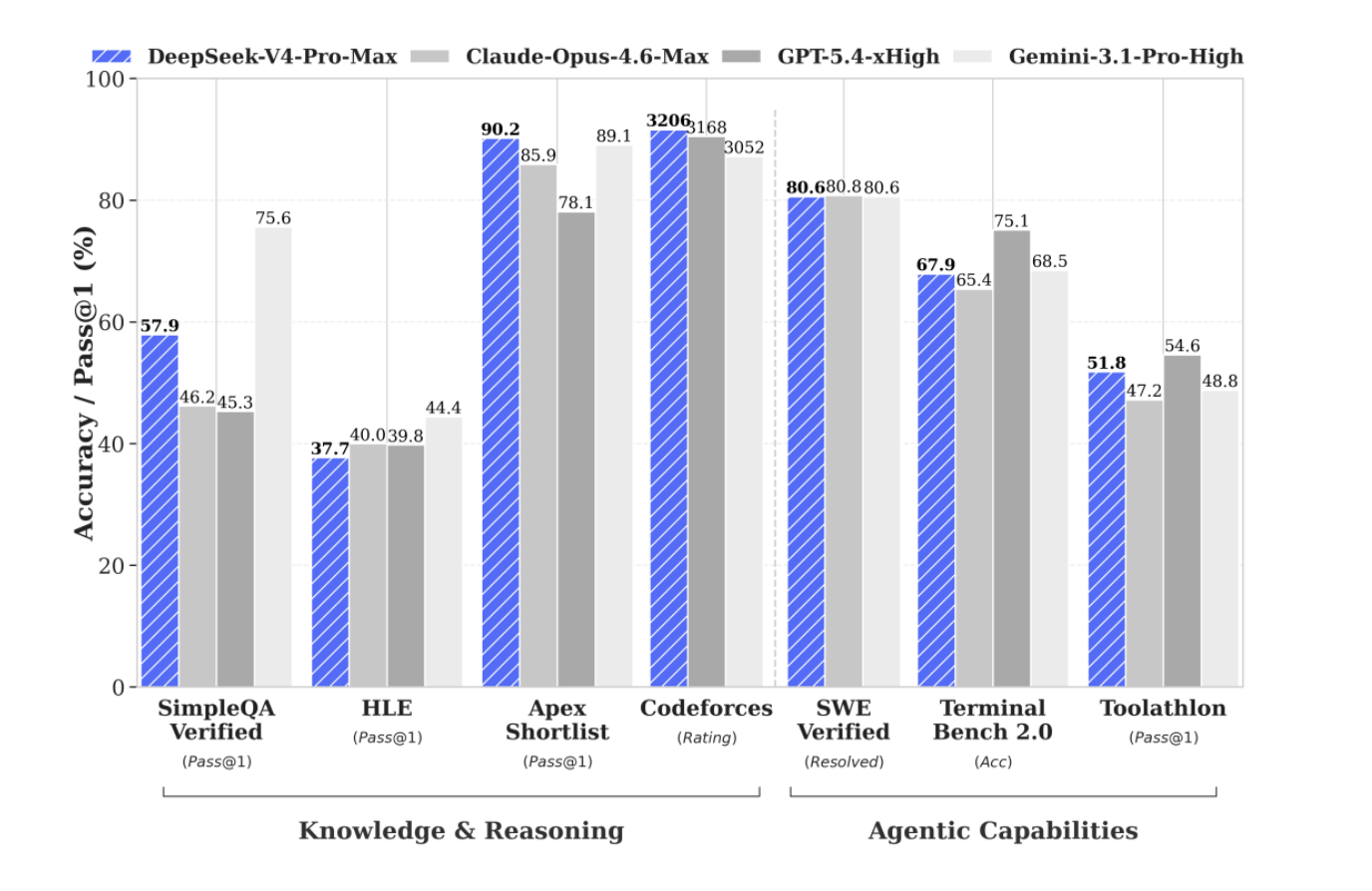
DeepSeek V4는 Knowledge & Reasoning뿐 아니라 Agentic Capabilities에서도 경쟁 모델과 비견되는 성능을 보인다.
이번 모델의 가장 큰 특징은 바로 100만 토큰까지 지원되는 Context Length에 있습니다. 지난 뉴스레터에서 Context Length의 중요성에 대해 언급했는데요. AI 에이전트가 오래 일하려면, 단순히 똑똑한 모델 하나만으로는 부족합니다. 사용자의 요청, 이전 대화, 파일 내용, 코드 실행 결과, 검색 결과, 실패한 시도, 수정 이력까지 모두 기억해야 하기 때문입니다. 하지만 이번에 공개된 DeepSeek는 그동안 다른 모델들이 보여왔던 긴 맥락에서의 불안정성을 개선한 것으로 보이는데요. 이 문제를 어떻게 해소했는지, 이번 뉴스레터에서는 DeepSeek V4에 반영된 기술을 살펴보도록 하겠습니다. |
|
|
Context Length는 모델이 한 번에 참고할 수 있는 정보의 양을 의미합니다. 초기 언어 모델은 한 번에 볼 수 있는 텍스트가 매우 짧았습니다. 긴 보고서를 넣으면 중간에 잘렸고, 긴 코드를 분석해달라고 하면 앞부분을 잊어버렸습니다. 그래서 많은 연구와 제품들이 더 긴 Context Length를 지원하는 방향으로 발전해왔습니다.
하지만 Context Length가 길다고 해서 무조건 좋은 것은 아닙니다. 긴 맥락을 ‘입력할 수 있는 것’과 긴 맥락을 ‘효율적으로 사용할 수 있는 것’은 다릅니다. 100만 토큰을 넣을 수 있다고 해도, 그때마다 계산량과 메모리 사용량이 과도하게 늘어난다면 실제 서비스로 배포하기 어렵습니다. 마치 1,000페이지짜리 책을 책상 위에 올려둘 수는 있지만, 매번 답변할 때마다 1,000페이지 전체를 다시 뒤져야 한다면 업무 속도는 느려질 수밖에 없는 것과 같은 원리입니다.
언어 모델에서 이 문제는 주로 Attention과 KV Cache에서 발생합니다. Attention은 모델이 현재 토큰을 생성할 때, 이전 토큰과 연관성을 계산합니다. 문제는 맥락이 길어질수록 참고해야 할 대상도 많아진다는 점입니다. 문장이 길어지고, 파일이 늘어나고, 도구 호출 결과가 누적될수록 모델은 더 많은 정보를 훑어봐야 합니다.
여기에 KV Cache 문제가 더해집니다. KV Cache는 이전 토큰들의 Key와 Value 정보를 저장해 다음 토큰을 더 빠르게 생성하도록 돕는 메모리입니다. 짧은 대화에서는 큰 문제가 아니지만, 100만 토큰 수준으로 가면 이 캐시 자체가 엄청난 메모리를 차지합니다. 에이전트가 웹을 검색하고, 코드를 실행하고, 파일을 읽고, 결과를 다시 분석하는 과정을 반복하면 Context Length와 KV Cache는 계속 커집니다.
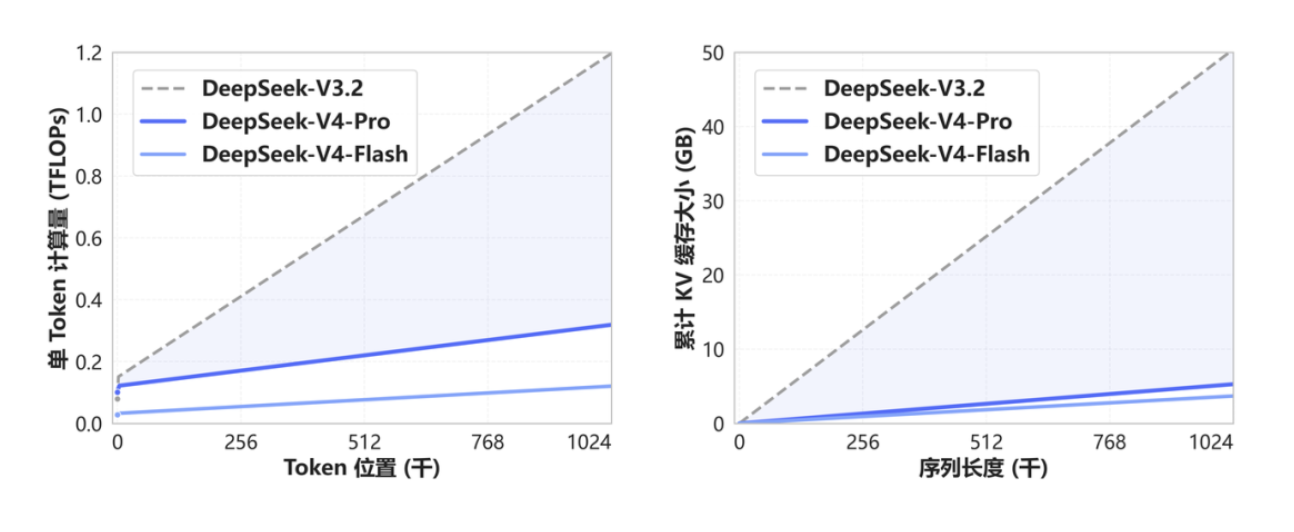
<DeepSeek V4 Technical Report>는 이 지점을 핵심 병목으로 봅니다. DeepSeek-V4-Pro는 100만 토큰 컨텍스트 환경에서 DeepSeek-V3.2 대비 단일 토큰 추론 FLOPs를 27% 수준으로 낮추고, KV Cache 크기를 10% 수준으로 줄였습니다. DeepSeek-V4-Flash는 같은 조건에서 FLOPs를 10%, KV Cache를 7% 수준까지 낮춘다고 설명합니다. |
|
|
DeepSeek V4는 Context Length가 증가해도 FLOPs와 KV Cache 증가폭을 크게 억제한다.
|
|
|
🤔 FLOPs (Floating Point Operations)
모델이 답변을 만들기 위해 수행하는 총 계산량을 의미합니다. 언어 모델은 내부적으로 행렬 곱셈과 같은 부동소수점 연산을 반복하는데, FLOPs는 이 연산 횟수를 수치로 표현한 것입니다. FLOPs가 많아질수록 추론 속도는 느려지고, GPU 사용량과 비용도 함께 증가합니다. |
|
|
Residual Connection 대신 Hyper-Connections |
|
|
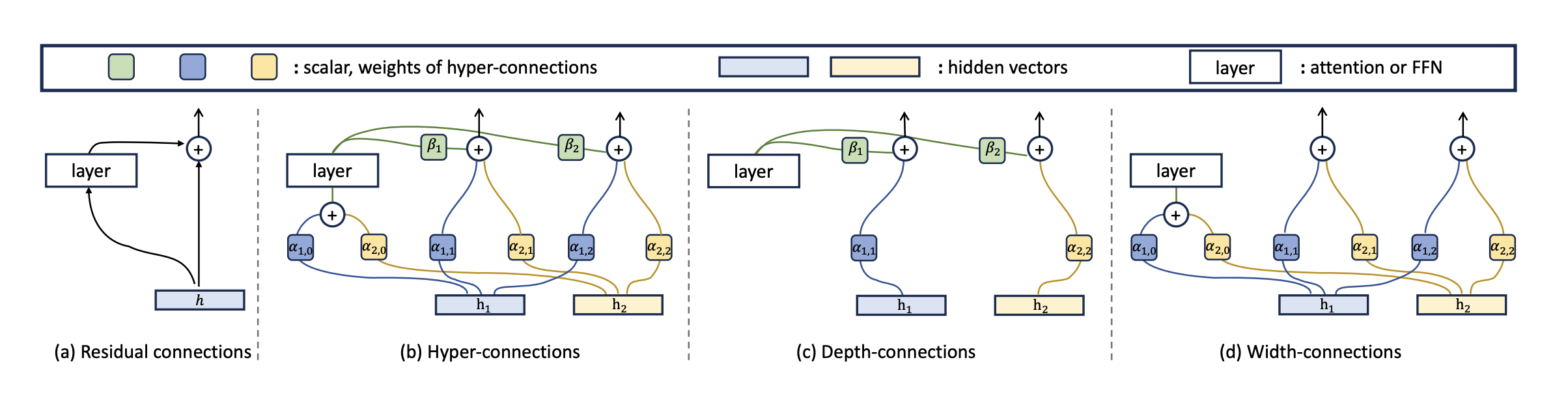
DeepSeek V4의 첫 번째 핵심 기술은 mHC, Manifold-Constrained Hyper-Connections입니다. Manifold, Hyper-Connections 같은 용어가 한 번에 등장해서 이름만 보면 꽤 복잡해보이는데요. 하지만 핵심만 보면 그렇게 복잡하지는 않습니다. mHC는 아주 단순하게 말하면, 모델 안에서 정보가 층을 지나며 안정적으로 전달되도록 연결 구조를 개선한 기술입니다.
언어 모델은 여러 층으로 구성됩니다. 입력된 정보는 첫 번째 층을 지나고, 두 번째 층을 지나고, 수십 개의 층을 통과하며 점점 더 추상적인 표현으로 바뀝니다. 이때 중요한 것은 정보를 깊은 층까지 안정적으로 전달하는 것입니다. 너무 많이 변형되면 원래 정보가 사라지고, 너무 약하게 전달되면 깊은 모델을 학습하기 어렵습니다.
기존 Transformer 계열 모델들은 안정적인 정보 연결을 위해 Residual Connection을 사용합니다. Residual Connection은 각 층의 출력에 입력을 단순히 더해주는 구조입니다. ‘이번 층에서 새롭게 계산한 정보’와 ‘이전까지 갖고 있던 정보’를 함께 다음 층으로 넘겨주는 방식입니다. 덕분에 깊은 모델에서도 정보가 완전히 사라지지 않고 전달될 수 있습니다.
그런데 모델이 더 커지고 복잡해지면 단순한 Residual Connection만으로는 부족할 수 있습니다. 더 풍부한 정보 교환을 위해 Hyper-Connections 같은 구조를 사용할 수 있지만, 연결을 무작정 복잡하게 만들면 학습 안정성이 흔들릴 수 있습니다. 정보가 더 많이 흐르는 대신, 그 흐름을 통제하기 어려워지는 것이죠.
올해 1월 공개된 mHC 논문에서는 기존 Hyper-Connections의 잔차 연결 공간을 특정 Manifold 위로 투영해 정보를 손실하지 않고 다음 층으로 전달할 수 있는 Identity Mapping 성질을 회복하고, 학습 안정성과 확장성을 높이는 방법을 제안합니다. 여기서 Hyper-Connections는 기존 Residual Connection을 더 넓고 복잡하게 확장한 연결 구조로, 여러 경로에서 정보를 섞을 수 있게 만들어 모델의 표현력을 높입니다. 하지만 연결이 많아질수록 정보가 흐르는 경로도 복잡해지고, 신호가 일정하게 유지되지 못하면 학습이 불안정해질 수 있습니다. 즉, Hyper-Connections는 더 많은 정보를 전달할 수 있는 구조이지만, 그만큼 정보 흐름을 안정적으로 제어하는 장치가 필요합니다. |
|
|
Residual Connection은 이전 층 출력을 그대로 더해 전달하며, Identity Mapping에 가까운 안정적인 정보 전달 경로를 제공한다. 반면, Hyper-Connections는 여러 경로의 정보를 β 가중치를 통해 결합해 표현력을 높인다.
|
|
|
mHC는 이 문제를 해결하기 위해 Residual Connection 공간을 특정 제약 공간, 즉 Manifold 위로 제한합니다. 쉽게 말하면, 정보가 더 풍부하게 흐르도록 연결은 확장하되, 그 흐름이 모델을 불안정하게 만들지 않도록 수학적 규칙을 걸어두는 방식입니다. 구체적으로는 Sinkhorn-Knopp 알고리즘을 활용해 Birkhoff Polytope Manifold 위로 투영하는 방식을 제안하는데요. Birkhoff Polytope는 쉽게 말해, 정보가 섞이더라도 전체 흐름이 과도하게 커지거나 사라지지 않도록 제한하는 안정적인 행렬 공간에 가깝습니다. 결과적으로 mHC는 Hyper-Connections의 표현력은 살리면서도, Residual Connection의 핵심 장점인 Identity Mapping 성질을 회복해 더 안정적인 대규모 학습을 가능하게 합니다. |
|
|
🤔 Sinkhorn-Knopp, Birkhoff Polytope
Sinkhorn-Knopp 알고리즘은 행렬을 반복적으로 정규화해, 각 행과 열의 합이 1이 되도록 만드는 방법입니다. 이 과정을 거치면 행렬은 Birkhoff Polytope, 즉 모든 값이 확률처럼 분배된 공간에 속하게 됩니다.
이 공간에서는 정보가 여러 경로로 섞이더라도 전체 크기가 과도하게 커지거나 사라지지 않습니다. mHC는 이 성질을 활용해 Hyper-Connections의 정보 흐름을 안정적인 범위 안으로 제한합니다. |
|
|
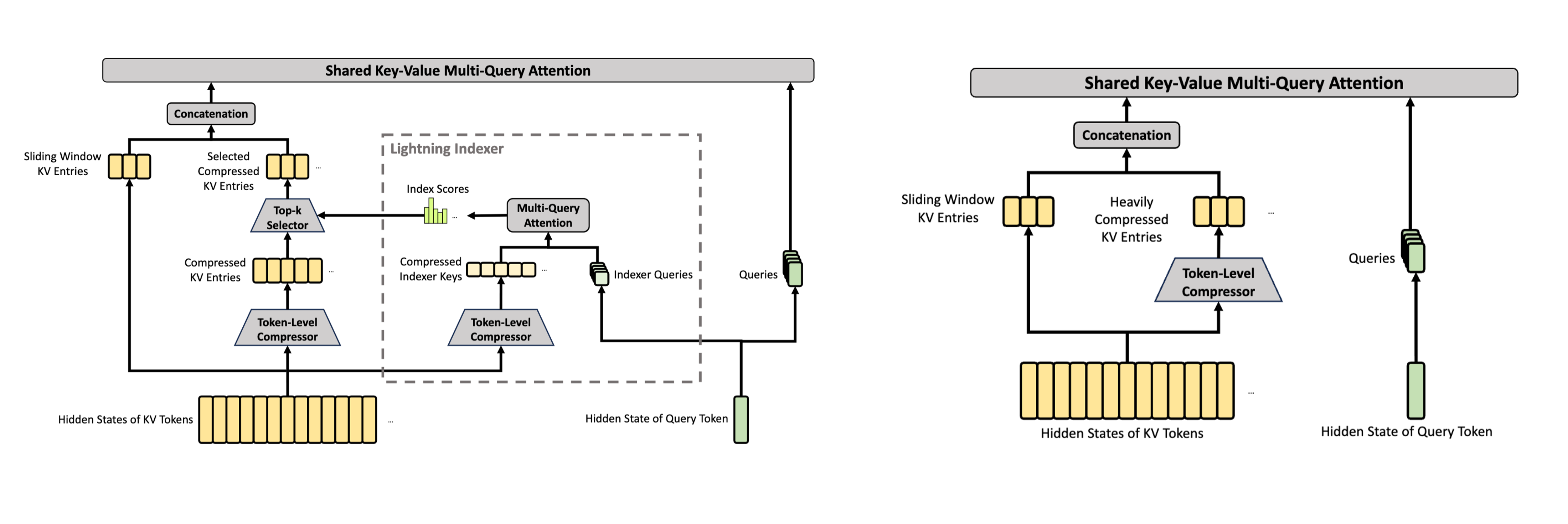
DeepSeek V4의 두 번째 핵심은 CSA(Compressed Sparse Attention)와 HCA(Heavily Compressed Attention)의 하이브리드 아키텍처입니다. CSA는 중요한 부분을 선택적으로 자세히 보는 구조에 가깝고, HCA는 매우 강하게 압축된 전체 흐름을 넓게 훑는 구조에 가깝습니다. 앞서 mHC가 모델 내부에서 정보가 안정적으로 흐르도록 연결 구조를 개선한 기술이었다면, CSA와 HCA는 긴 Context Length를 더 효율적으로 처리하기 위한 Attention 구조인 것이죠. |
|
|
CSA는 압축된 KV Entry 중 중요한 블록만 선택해 참고하고, HCA는 강하게 압축된 전체 흐름을 Dense Attention으로 유지한다.
|
|
|
긴 Context Length에서 가장 큰 문제는 모든 토큰을 똑같은 밀도로 참고하기 어렵다는 점입니다. 만약 100만 토큰을 모두 같은 방식으로 훑으려 한다면, 계산량과 메모리 사용량이 급격히 커집니다.
기존 Transformer의 Attention은 현재 토큰이 이전 토큰들을 참고하면서 다음 출력을 만드는 구조입니다. 이 과정에서 이전 토큰들의 Key와 Value를 저장해두는 공간이 KV Cache이고, 각 토큰 또는 압축된 토큰 블록에 해당하는 Key-Value 단위를 KV Entry라고 부릅니다. (KV Cache에 대한 자세한 내용은 이전 뉴스레터를 참고해주세요.) KV Cache는 추론을 빠르게 만드는 데 꼭 필요하지만, Context Length가 길어질수록 KV Entry도 함께 늘어나기 때문에 메모리 병목이 됩니다.
먼저 CSA은 긴 컨텍스트를 그대로 모두 보는 대신, KV Cache를 시퀀스 방향으로 압축한 뒤 중요한 블록만 선택적으로 참고합니다. Sparse Attention이라는 이름처럼 모든 토큰을 촘촘하게 연결하지 않고, 현재 Query와 관련성이 높은 압축 블록을 골라 Attention을 수행합니다. Hugging Face의 DeepSeek V4 해설에 따르면 CSA는 KV Entry를 시퀀스 차원에서 4배 압축하고, Lightning Indexer가 Query마다 중요한 압축 블록을 선택합니다. CSA가 4배 압축을 적용하면, 100만 개 토큰의 문맥은 압축된 KV Entry 시퀀스 기준으로 약 25만 개 단위로 표현될 수 있습니다.
하지만 Sparse Attention만 사용하면 최근 문맥처럼 세부 정보가 중요한 부분을 놓칠 수 있습니다. 예를 들어 긴 보고서 전체 흐름은 요약해서 봐도 되지만, 바로 앞 문단의 표현이나 최근 대화의 지시사항은 정확하게 기억해야 합니다. 그래서 CSA는 Sliding Window를 함께 사용합니다. Sliding Window는 최근 토큰 주변의 짧은 구간을 더 직접적으로 참고하는 구조입니다. 쉽게 말하면, 오래된 문맥은 압축해서 보고, 방금 나온 문맥은 더 자세히 보는 방식입니다.
반면 HCA은 더 과감한 압축을 사용합니다. HCA는 KV Entry를 128배 수준으로 강하게 압축하고, 그렇게 압축된 시퀀스 전체에 Dense Attention을 수행합니다. 여기서 Dense Attention은 압축된 단위 전체를 빠짐없이 참고하는 방식입니다. 원문 전체를 그대로 촘촘히 보는 것은 비용이 많이 들지만, 이미 강하게 압축된 요약 흐름이라면 전체를 훑는 것이 가능해집니다. 그래서 HCA는 긴 문맥의 세부 내용을 모두 기억하기보다는, 전체 구조와 장거리 의존성을 유지하는 역할에 가깝습니다. |
|
|
지금까지 DeepSeek V4의 기술적인 의의에 대해서 설명드렸는데요. 이번 모델은 AI 패권 구도에서도 큰 의의를 갖습니다. 바로 이번 모델이 Huawei Ascend AI 칩에 맞춰 조정된 모델로 공개됐다는 것인데요. DeepSeek 쇼크가 미국의 GPU 수출 통제 속에서도 저사양 GPU로 학습되어 촉발됐다는 점에서 가벼이 보기는 어렵습니다. 중국 AI 생태계가 자체 하드웨어와 모델을 결합하려는 움직임을 보여주기 때문입니다. 이와 관련하여 논란이 이어지고 있기는 하지만, DeepSeek가 독자적인 기술로 긴 Context Length와 에이전트 성능의 문제를 해결하면서, 산업적으로는 중국 AI 생태계의 독자적인 인프라 구축하려는 시도로 보입니다.
그럼 DeepSeek가 기존 미국 기업의 상용 모델을 뛰어 넘는 에이전트가 될까요? Context Length만 길어진다고 완벽한 에이전트가 등장하지는 않습니다. 에이전트에게는 여전히 좋은 도구, 안정적인 실행 환경, 명확한 권한, 작업 로그, 평가 시스템, 하네스 구조가 필요합니다. 현실적으로는 지난해만큼의 파격적인 영향력을 가지고 오지 못한 것으로 보입니다. 사용자 사이에서는 성능이 그다지 뛰어나지도 않으면서, 가격 경쟁력도 떨어졌다는 점에서 비판의 목소리를 내기도 합니다.
하지만 새로운 연구의 방향성을 제안한 것은 고무적입니다. 모델이 긴 컨텍스트를 효율적으로 처리할 수 있다면, 에이전트는 더 적은 맥락 손실로 더 긴 작업을 수행할 수 있겠죠. 점차 모델 자체의 성능에서, AI를 에이전트로 활용할 수 있게 더 오래 일할 수 있는 방향으로 모델 구조가 바뀌고 있는 것처럼 보입니다. |
|
|
딥 다이브 뉴스레터 잘 보고 계신가요? 여러분의 의견과 피드백을 받습니다 :) |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|