하네스 엔지니어링 개념과 원리를 살펴봅니다. #140 위클리 딥 다이브 | 2026년 4월 22일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 하네스 엔지니어링의 개념과 Context Length 제약을 요약했습니다.
- Anthropic이 공개한 하네스 엔지니어링의 기술적 원리를 정리했습니다.
- 하네스 시스템이 가져올 미래를 예상해봅니다.
|
|
|
안녕하세요, 에디터 배니입니다.
지난 17일, Claude Design이 공개됐습니다. Claude Code에게 디자인 기획 아이디어만 짤막하게 남겨주면, Claude가 사용자에게 세부사항을 질문하며 디자인을 해주는 것입니다. 웹 사이트 개발에 아주 유용한 도구로 소개되면서 속속들이 후기가 등장하고 있습니다. 이와 유사한 서비스는 많이 있었지만 지금까지 공개된 어떤 서비스보다도 퀄리티가 높고 사용자와 상호작용하며 수정해나갈 수 있다는 점에서 호평을 받고 있습니다. |
|
|
Anthropic이 공개한 Claude Design
이번 개발의 핵심은 ‘AI가 디자인을 잘한다!’가 아니라고 생각합니다. AI 모델은 이전에도 디자인을 잘할 수 있는 능력은 보유하고 있었습니다. 이번에 공개된 모델이 ‘디자인을 위한 새로운 모델’은 아니라는 것이죠. 즉, 언어 모델 자체의 성능을 개선한 것이 아니라, 모델을 활용하는 방법을 개선한 것입니다. 이를 하네스 엔지니어링(Harness Engineering)이라고 합니다. 조금 더 구체적으로 말하자면, AI 에이전트가 안정적이고 의도대로 동작하도록 전체 실행 환경·제약·피드백 시스템을 설계하는 기술을 의미합니다.
이게 ‘기술(Engineering)’로 불릴 만큼 특별한 설계가 필요한 것일까요? 도대체 하네스 엔지니어링이 왜 필요할까요? 단순한 유행일지, 아니면 앞으로 미래를 바꿔 나갈 기술일지, 이번주 뉴스레터에서는 하네스 엔지니어링에 대해 알아봅니다. |
|
|
하네스 엔지니어링을 소개하기 전에, 그 이전에 어떤 흐름으로 발전해왔는지 간단히 짚어볼 필요가 있습니다. 언어 모델의 지능 수준을 의심 받지 않기 시작하면서 점점 AI에게 더 높은 자유도를 주고자 했습니다. 인간이 하기 어려운 일들이나 반복되는 일들을 자동화하고자 하는 노력이 있었죠. 이러한 맥락에서 AI 에이전트들이 발전하고 있었습니다. 이를 뒷받침하는 기술 중 하나는 Context Length의 길이를 늘리는 것입니다.
아마 최근에 ChatGPT와 같은 대화형 서비스를 사용하신 분들이라면 Context Length의 제약을 크게 느끼지 못했을 수도 있습니다. 하지만 초기 ChatGPT 모델들은 한 번에 이해할 수 있는 텍스트 양 자체가 적었습니다. 긴 글을 번역해달라고 하면 번역이 중간에 끊기기도 하고, 중간에 ‘계속 생성하기’를 눌러줘야 했기 때문에 매우 불편했습니다. 그래서 많은 연구들이 Context Length를 늘리면서도 성능을 유지할 수 있도록 모델을 훈련시켰습니다. 과거에는 고작 4천 토큰 수준의 맥락만 한 번에 이해할 수 있었지만, 이제는 40만 토큰 수준을 이해할 수 있습니다. 거의 1천 페이지의 책을 한 번에 이해하고 답변을 출력할 수 있는 수준이죠.
이 양이 많아 보이지만 실제로 그렇지는 않습니다. 모델에는 우리가 직접 텍스트 프롬프트로 요청하는 것 외에도 많은 정보가 입력됩니다. 대화나 지시 사항에 따르기 위한 모델을 Instruct 모델이라고 하는데요. Instruct 모델에는 보통 아주 긴 양의 지시사항(Instruction)이 템플릿처럼 포함되어 있습니다. Context Length를 넘어서게 되면 새로운 세션을 시작해야 합니다. ChatGPT에서 ‘새 채팅’을 누르고 만드는 것이 하나의 세션이라고 보면 됩니다. 지금까지 대화했던 내용을 모두 잊고 새로운 대화를 시작하는 것과 같죠. |
|
|
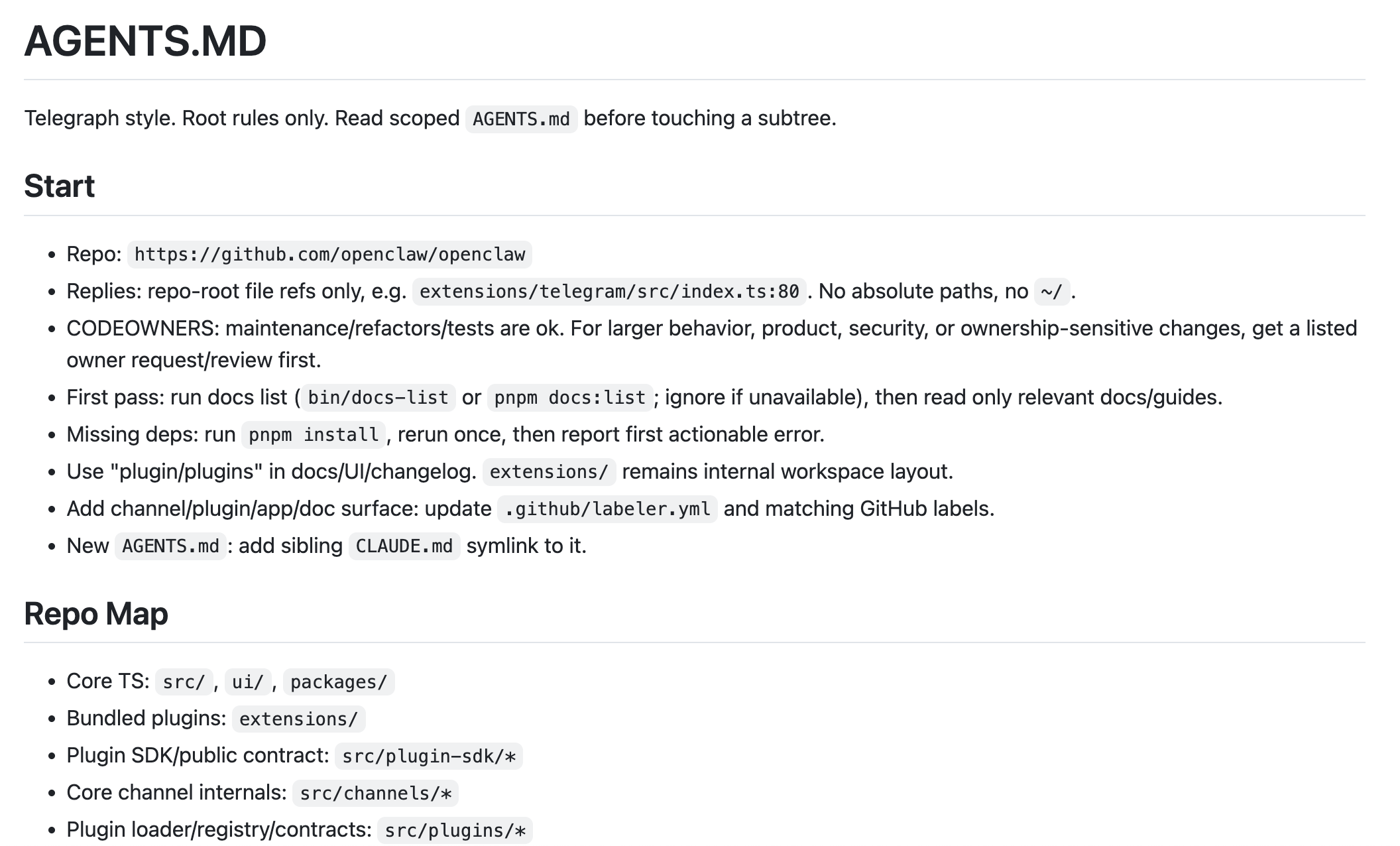
OpenClaw의 Agents.md로 이와 같은 행동 강령이 모두 프롬프트로 입력된다.
|
|
|
그러나 AI 에이전트는 인간의 프롬프트에만 의존할 수 없습니다. AI가 ‘알아서’ 움직이기 위해서는 사용자의 요청을 한 번에 듣고 알아서 행동 요령을 생성해내야 합니다. 생성한 행동 요령이 계속 같은 세션에 누적되면 더 이상 한 번에 많은 양의 맥락(Context)을 처리하기 어려운 수준에 이릅니다. 그 순간 다시 새로운 세션에서, 기존의 작업을 까먹은 채로 작업을 이어나가야 합니다. Context Length를 아무리 길게 하더라도 사용자의 개입을 최소화해야 하는 AI 에이전트를 운용하기 위해서는 다른 구조가 필요했습니다. 똑똑한 AI가 이제 프롬프트도 만들 수 있고, 스스로 피드백도 할 수 있지만 모든 것을 한 번에 기억할 수 없으니 LLM이 똑똑하게 동작할 수 있도록 시스템을 개선하기로 한 것입니다.
좋은 답변을 위해서 프롬프트를 어떻게 입력해야 하는지(Prompt Engineering), 맥락을 어떻게 구성하는지(Context Engineering) 방법을 고안하는 것도 중요합니다. 실제로 답변의 퀄리티도 많이 달라지죠. 하네스 엔지니어링은 그보다 한 차원 위의 개념입니다. |
|
|
퇴근해야 하니까, 이건 다음 근무자에게 넘길게요 |
|
|
이제 Anthropic의 사례 연구를 살펴봅시다. 가장 단순한 해결 방법은 일단은 컨텍스트를 모델 바깥으로 꺼내두는 것입니다. 세션 안에 모든 맥락을 계속 쌓아두는 대신, 중요한 상태를 파일이나 로그, 외부 저장소 같은 형태로 남겨두고 필요할 때 다시 불러오는 방식입니다. Anthropic도 장기 작업을 위한 기본적인 방법으로 Compaction을 언급합니다. 이전 대화를 요약해 압축해두고, 메모리 툴이나 파일을 통해 세션 바깥에 상태를 남겨 다음 작업이 이어질 수 있도록 만드는 것이죠. 오래된 도구 호출 결과를 덜어내거나 일부 컨텍스트를 잘라내는 방식도 함께 사용됩니다.
그러나 압축은 어디까지나 요약입니다. 무엇을 남기고 무엇을 버릴지 이미 한 번 판단해야 하고, 그 판단은 되돌릴 수 없는 경우가 많습니다. 나중에 꼭 필요해질 단서가 압축 과정에서 사라질 수도 있고, 요약된 문장만으로는 다음 세션의 에이전트가 실제 작업 상태를 정확히 이해하지 못할 수도 있습니다. Anthropic도 Compaction만으로는 충분하지 않다고 지적합니다. 같은 세션을 이어가는 동안에는 연속성이 유지되지만, 장시간 작업에서 필요한 것은 단순히 “대화를 줄이는 것”이 아니라 작업 상태를 안정적으로 넘겨주는 구조이기 때문입니다.
여기서 독특한 현상이 발생합니다. 모델이 맥락 한계에 가까워졌다고 느낄 때, 일을 끝내지 않았는데도 스스로 마무리하려고 하는 것입니다. Anthropic은 일부 모델이 컨텍스트 한계에 다다르면 작업을 조기에 정리하거나 ‘이 정도면 됐다’고 결론 내리는 현상을 이렇게 설명했습니다. 이를 Context Anxiety라고 합니다. Compaction이 누적되면서 어쩔 수 없이 계속 긴 컨텍스트는 유지됩니다. 근본적인 한계를 극복할 수 없기 때문에 Anthropic은 컨텍스트가 초기화되더라도 좋은 답변 퀄리티를 유지하는 구조를 고려하기 시작했습니다. |
|
|
Anthropic은 이 문제를 The Long-running Agent Problem이라고 부릅니다. 에이전트는 실제로는 연속적으로 일하는 것처럼 보이지만, 내부적으로는 여러 개의 불연속적인 세션을 거치며 일합니다. 그리고 새 세션이 시작될 때마다 이전 세션을 완전히 기억하지 못합니다. Anthropic은 이를 ‘교대 근무를 하는 엔지니어 팀’에 비유하죠 이전 근무자가 무엇을 했는지 완전히 기억하지 못한 채 다음 근무자가 투입되는 셈이죠. 복잡한 프로젝트일수록 한 번의 Context Window 안에서 끝낼 수 없기 때문에, 결국 문제의 본질은 모델의 지능이 아니라 세션과 세션 사이를 어떻게 연결할 것인가로 옮겨갑니다.
이때 꽤 인간적인(?) 실수가 나타납니다. 첫 번째는 에이전트가 한 번(One-shot)에 너무 많은 일을 하려는 경우입니다. 그러다 구현 도중 컨텍스트가 소진되고, 다음 세션은 반쯤 만들어진 기능과 불완전한 상태만 보고 시작하게 됩니다. 문서화도 충분하지 않으니, 다음 에이전트는 방금 무엇이 만들어졌는지 추측부터 해야 합니다. 두 번째는 어느 정도 기능이 쌓인 뒤 새로 시작한 에이전트가 지금까지의 작업물을 보고 충분하다고 판단하고 일을 안 해버리는 경우입니다. 과거의 기록이 제대로 남아 있지 않다보니 어디까지 새롭게 작업을 해야 하는지 분명하지 않은 것이죠. 장기 작업에서는 단지 많이 기억하는 능력보다도, 지금 어디까지 왔고 다음에 무엇을 해야 하는지 정확히 남기는 능력이 더 중요해집니다. |
|
|
이에 Anthropic은 에이전트를 장기 프로젝트를 함께 하는 인간 조직처럼 구성했습니다. 그 구조가 바로 Initializer Agent와 Coding Agent입니다. 첫 번째 세션에서는 Initializer Agent가 들어가 작업 환경 자체를 구성합니다. 예를 들어 init.sh 같은 초기화 스크립트를 만들고, 에이전트가 지금까지 무엇을 했는지 기록하는 진행 파일을 남기고, 어떤 파일들이 추가되었는지 알 수 있도록 초기 Git 커밋까지 구성합니다. 다음 에이전트가 이해할 수 있는 기록을 남기는 역할을 하는 것이죠. |
|
|
각 기능은 테스트 형태로 정의되며, 초기에는 모두 passes: false로 설정되어 이후 coding agent가 구현을 진행하며 상태만 업데이트하도록 설계된다.
|
|
|
그다음은 Coding agent가 이어받습니다. 그런데 여기서 중요한 점은 이 에이전트가 ‘열심히 많이 하기(One-shot)’가 아니라 한 번에 한 기능씩, 점진적으로(One-feature-at-a-time) 일하도록 설계되었다는 것입니다. 에이전트에게 철저한 업무 책임을 나눈 것이죠. Anthropic은 실제로 이 접근이 매우 중요했다고 설명합니다. 기능 하나를 구현하고, End-to-end 테스트로 확인하고, Git에 설명적인 커밋 메시지를 남기고, 진행 파일에 무엇을 했는지 기록한 뒤 세션을 마무리하는 식입니다. 이렇게 하면 다음 세션은 추측으로 시작하지 않습니다. Git 히스토리와 진행 로그를 읽고 바로 이어서 일할 수 있습니다. 개발자로서 완벽한 인수인계 자료를 넘겨 받은 것입니다.
모델 자체는 이미 코드를 짤 수 있고, UI도 만들 수 있고, 테스트도 어느 정도 수행할 수 있습니다. 문제는 그 능력들이 오랜 시간 동안 일관되게 누적되지 않는다는 데 있었습니다. 그래서 하네스는 모델에게 더 많은 자유를 주는 동시에, 그 자유가 무질서로 번지지 않도록 작업 단위를 쪼개고, 상태를 외부화하고, 다음 세션이 읽을 수 있는 흔적을 남겨두도록 만듭니다. |
|
|
그래서 Claude Design은 어떻게 만들었냐면요, |
|
|
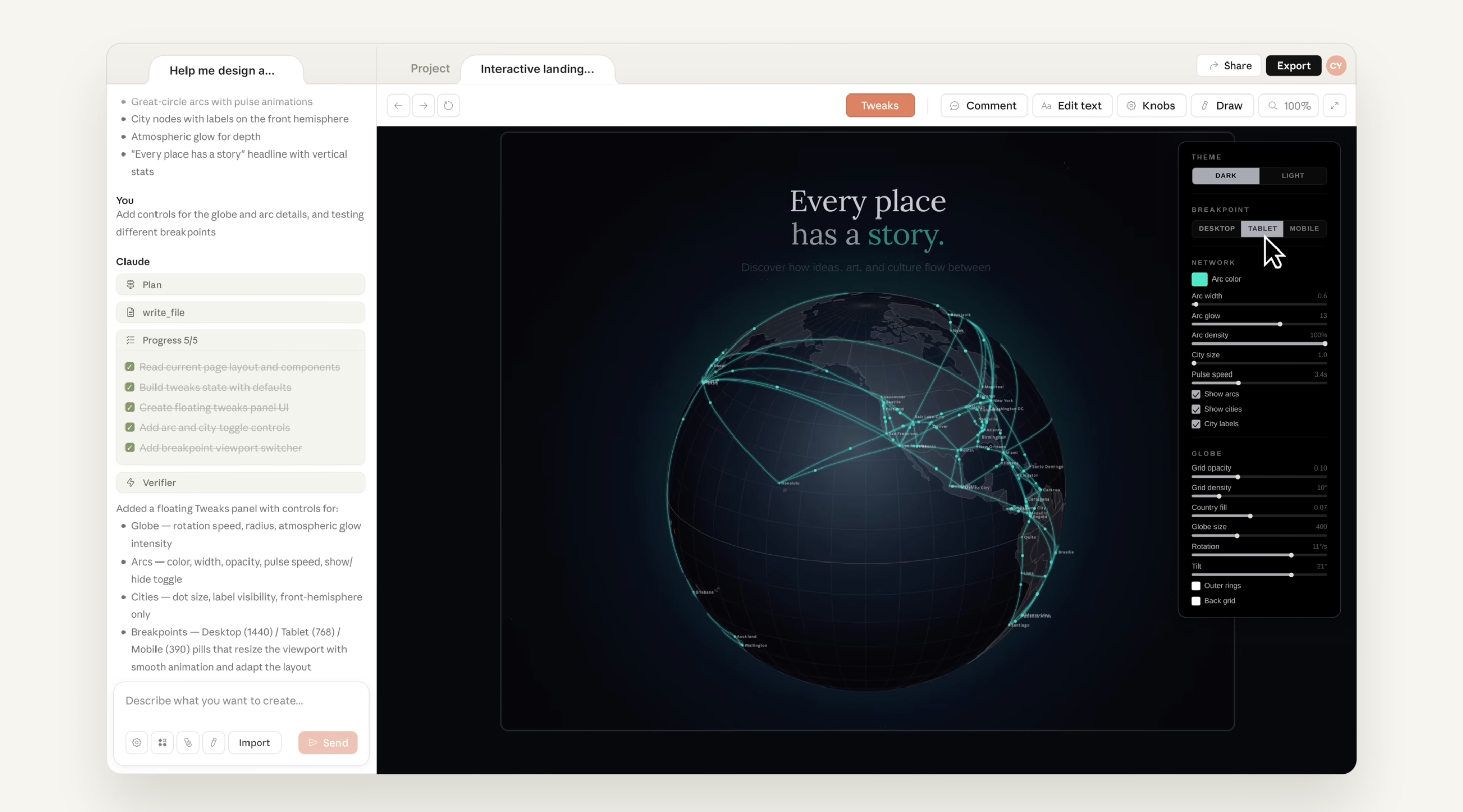
이와 같은 철학으로 탄생한 결과가 Claude Design입니다. Anthropic은 하네스 엔지니어링 방식을 적용하여 디자인 시스템을 만들고자 했는데요. 그 개발 과정에 대한 기록은 여기에 상세히 나와있습니다. 장시간 에이전트가 서비스를 개발하는 실험에서, 이전 Long-running Harness에서 얻은 교훈, 즉 작업 단위로 쪼개고, 세션 간 상태를 구조화된 산출물로 넘겨주는 것을 그대로 가져왔다고 설명합니다. 그리고 그 결과로 Planner, Generator, Evaluator의 3개 에이전트 구조를 사용해, 수 시간에 걸친 풀스택 앱 개발 성능을 끌어올렸습니다.
Planner는 사용자의 짧은 요청을 실제 제품 수준의 명세로 확장하고, Generator는 이를 구현하며, Evaluator는 결과물을 실제로 실행하고 검증하는 역할을 맡습니다. 핵심은 이 세 역할이 하나로 합쳐져 있지 않다는 점입니다. 동일한 에이전트가 생성과 평가를 동시에 수행할 경우 발생하는 자기 합리화 문제를 구조적으로 제거한 것이죠. 실제로 Anthropic은 모델이 자신의 결과물을 과하게 긍정적으로 평가하는 경향이 있어, 평가를 별도의 에이전트로 분리하는 것이 필수적이었다고 설명합니다. |
|
|
(좌) 단일 에이전트(Solo Harness)가 생성한 초기 결과물(상단)은 기본 UI만 갖춘 채 기능 연결이 불완전한 반면, (우) 하네스 기반 접근(Full Harness, 하단)은 실제 사용 가능한 프로젝트 생성 흐름과 완성도 높은 인터페이스를 구현한 모습.
Planner는 1~4문장 수준의 짧은 사용자 요청을 더 야심찬 제품 명세로 확장하되, 세부 구현까지 미리 못박기보다는 제품 맥락과 높은 수준의 기술 설계에 집중하도록 설계됐습니다. 이후 Generator는 이 명세를 한 번에 구현하지 않고 스프린트 단위로 하나씩 구현하며, Evaluator는 Playwright MCP를 활용해 실제 사용자처럼 앱을 클릭하고, UI 기능과 API, 데이터베이스 상태까지 점검하면서 각 스프린트를 평가합니다.
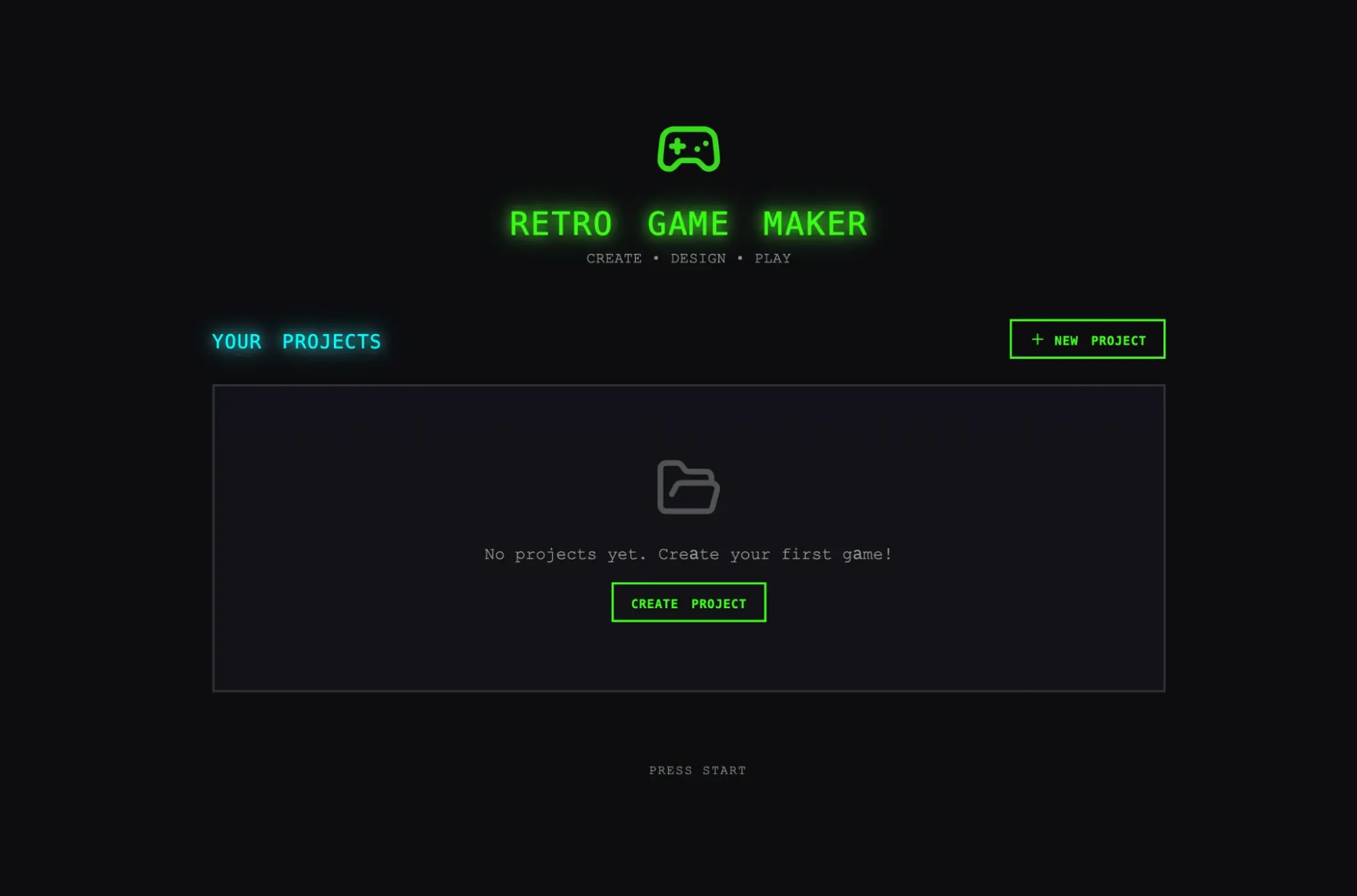
그 결과, Anthropic은 같은 한 줄 프롬프트로 레트로 게임 제작 앱을 만들게 했을 때, 단일 에이전트 방식은 약 20분, 9달러 수준으로 끝났지만, 전체 하네스는 약 6시간, 200달러가 들었다고 설명합니다. 비용만 보면 훨씬 비효율적으로 보이지만, 결과물의 차이가 컸다고 평가합니다.
단일 에이전트 결과물은 겉보기에는 그럴듯했지만 실제로는 UI 흐름이 어색하고, 게임 런타임과 엔티티 정의 사이의 연결이 깨져 있어 제대로 작동하지 않는 반면, 하네스 기반 결과물은 같은 한 줄 프롬프트에서 시작했음에도 Planner가 이를 16개 기능, 10개 스프린트의 명세로 확장했습니다. 그 결과 기본 편집기와 플레이 모드뿐 아니라 스프라이트 애니메이션, 행동 템플릿, 사운드, AI 보조 기능, 공유 가능한 게임 내보내기까지 포함하는 어플리케이션으로 발전했다고 설명합니다.
|
|
|
솔직히 말하자면 ‘하네스 엔지니어링’과 같은 용어를 들었을 때는 반감이 들었습니다. 과거 ‘프롬프트 엔지니어링’과 같이 ‘Take a deep breath’ 한 문장 넣었다고 성능이 개선된다니, 그리고 이런 것을 찾는 것이 연구라니 받아들이기 쉽지 않았습니다. 수치화되지 않고 재현 불가능한 패턴을 좋아하지 않았던 탓입니다. 확실하게 증명 가능한 것들을 연구하고 싶었던 것 같습니다.
그러나 현실에서는 계속 ‘하네스 시스템’을 구축하고자 했습니다. 똑똑한 AI를 잘만 구현해두면 반복문만으로도 멋진 결과물을 얻을 수 있을 것 같았죠. 그때 제 아이디어도 회사에서 업무를 나눠하듯이, 에이전트별로 특화된 작업을 수행하며, 서로의 작업물을 넘겨주며 협업하는 방식을 고려했었습니다. 아마 많은 분들이 이와 같이 에이전트를 구성하기 위해 노력했을 것입니다. 그러나 말처럼 쉽지 않았습니다. 기술적인 문제도 있었겠지만, 사실 구조적인 문제라는 것도 알고 있었습니다. LLM을 잘 운용할 수 있는 구조를 찾은 것은 말 그대로, 통제할 수 없는 야생마를 경주마로 탈바꿈한 것과 같은 발견처럼 보입니다. 실제 Physical AI를 구현하는 데도 많은 아이디어를 제공해줄 수 있고요. 이런 연구가 누적된다면 체계적인 하네스 시스템이 등장하는 것은 시간 문제일 것 같습니다. 그 말인즉, AI Agent가 현실화되는 것도 머지 않았다는 말이겠죠? |
|
|
딥 다이브 뉴스레터 잘 보고 계신가요? 여러분의 의견과 피드백을 받습니다 :) |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|