AI도 상상할 수 있을까? 현실을 겪지 않고도 미래를 예측하는 세계 모델, 그 원리를 살펴봅니다. #99 위클리 딥 다이브 | 2025년 7월 9일
에디터 느리 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 세계 모델(World Model)의 개념을 설명했습니다.
- 세계 모델이 어떻게 작동하며, 왜 필요한지 정리했습니다.
- 최신 연구 사례인 DIAMOND와 DreamerV3를 통해 세계 모델의 미래 흐름을 짚어봤습니다.
|
|
|
World Model, 상상으로 학습하는 AI |
|
|
안녕하세요! 에디터 느리입니다 :D
여러분은 '이미지 트레이닝'에 대해 들어보셨나요? |
|
|
이는 운동 선수들이 실제로 몸을 움직이지 않고 머릿속으로 경기 상황을 반복 시뮬레이션하는 훈련을 말합니다. 예를 들어 농구 선수가 경기 중 특정 상황이 벌어졌을 때 자신이 어떻게 반응해야 할지를 미리 떠올리면서 마음속으로 연습하는 거죠. 이렇게 반복적으로 상상 훈련을 하다 보면, 실제 경기에서 훨씬 더 빠르고 정확하게 반응할 수 있습니다.
놀랍게도, AI 역시 비슷한 방식의 ‘상상 훈련’이 가능합니다. 이를 가능하게 해주는 것이 바로 세계 모델(World Model)입니다. 세계 모델이란 AI가 학습을 통해 외부 환경을 내부에 구현한 정신적 모형을 말합니다. 쉽게 말해, AI가 현실 세계를 자기만의 머릿속에 그려놓고, 그 안에서 스스로 시뮬레이션하면서 학습하는 것이죠. 이 모델은 현재의 상태(State)와 에이전트의 행동(Action)을 입력으로 받아, 그 결과로 다음 상태를 예측하는 방식으로 작동합니다. 마치 인간이 “내가 이렇게 하면 다음엔 이런 결과가 나올 거야” 하고 상상하는 것처럼요.
전통적인 강화학습 에이전트는 대부분 모델 프리(Model-free) 방식으로 학습합니다. 이는 환경 자체를 따로 모델링하지 않고, 매 순간 관측(Observation)을 기반으로 보상과 행동 간의 관계를 직접 경험을 통해 학습하는 방식입니다. 반면, 세계 모델을 활용하는 모델 기반(Model-based) 방식은 환경을 내면화한 모델을 이용해 실제 환경과의 상호작용 없이도 수천 번, 수만 번의 '상상 시뮬레이션'을 실행할 수 있습니다. 이로 인해 에이전트는 매 순간 눈앞의 상황에 단순히 반응(Greedy)하는 대신, 내부 모델을 통해 앞으로 일어날 상황을 예측하고, 장기적으로 더 나은 선택을 내릴 수 있습니다.
기존의 모델 프리 학습은 매번 실제 환경과 상호작용하여 데이터를 수집해야 했습니다. 그에 따라 학습에는 매우 많은 시간이 걸리고 학습에 필요한 데이터의 양도 많습니다. 특히, 복잡한 환경이나 장기적인 계획이 필요한 과제에서는 이런 방식의 한계가 두드러집니다.
반면, 세계 모델은 실제 환경에서 경험을 수집하지 않아도 내부에서 수많은 시뮬레이션을 통해 학습할 수 있습니다. 또한, 내면의 모델을 활용해 미리 예측하고 계획하는 능력을 갖추기 때문에 단기적인 보상이 아닌 장기적인 목표 달성에 유리한 행동 전략을 학습할 수 있습니다.
|
|
|
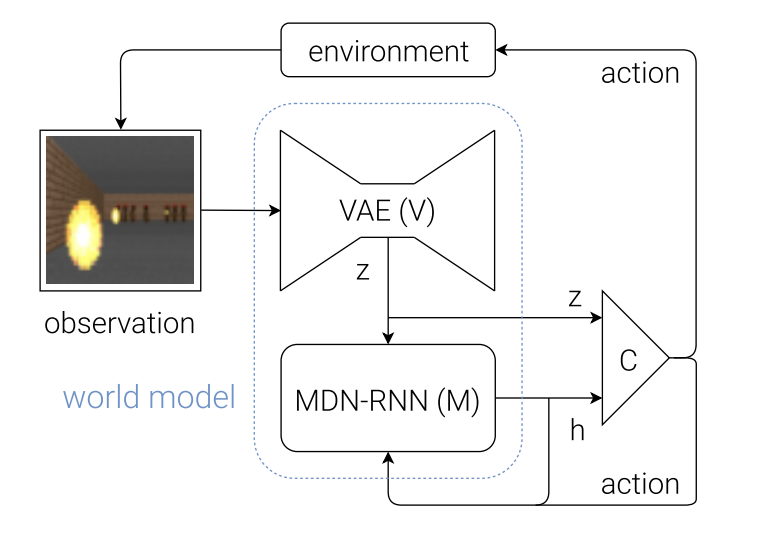
세계 모델은 기본적으로 인간 인지 체계를 모방하여 크게 3가지로 나누어집니다.
- Vision(시각): 지금 무엇을 보고 있나?
- Memory(기억): 지금까지 어떤 흐름이 있었나?
- Controller(결정): 다음엔 어떻게 행동해야 하나?
|
|
|
AI는 환경으로부터 고차원의 이미지 관측(Observation)을 입력받습니다. 이 이미지들은 픽셀 단위의 수많은 정보로 구성되어 있는데요. 그렇다고 해서 AI가 학습을 위해 꼭 모든 픽셀을 이해할 필요는 없습니다. 예를 들어, 실제로 공, 선수, 코트에 대한 정보만 알면 되는 농구 경기에서 경기장 광고판이나 유니폼의 주름 등의 배경 정보는 불필요합니다.
Vision Model은 이러한 고차원 이미지 관측을 "의미 있는 저차원 잠재 표현(Latent Representation)"으로 압축합니다. 이 과정을 통해 계산 효율이 향상되고, 학습에 꼭 필요한 핵심 정보만을 유지할 수 있게 되죠. 여기서 "불필요한 정보"란, 미래 상태나 보상 예측에 기여하지 않는 시각적 요소를 의미합니다.
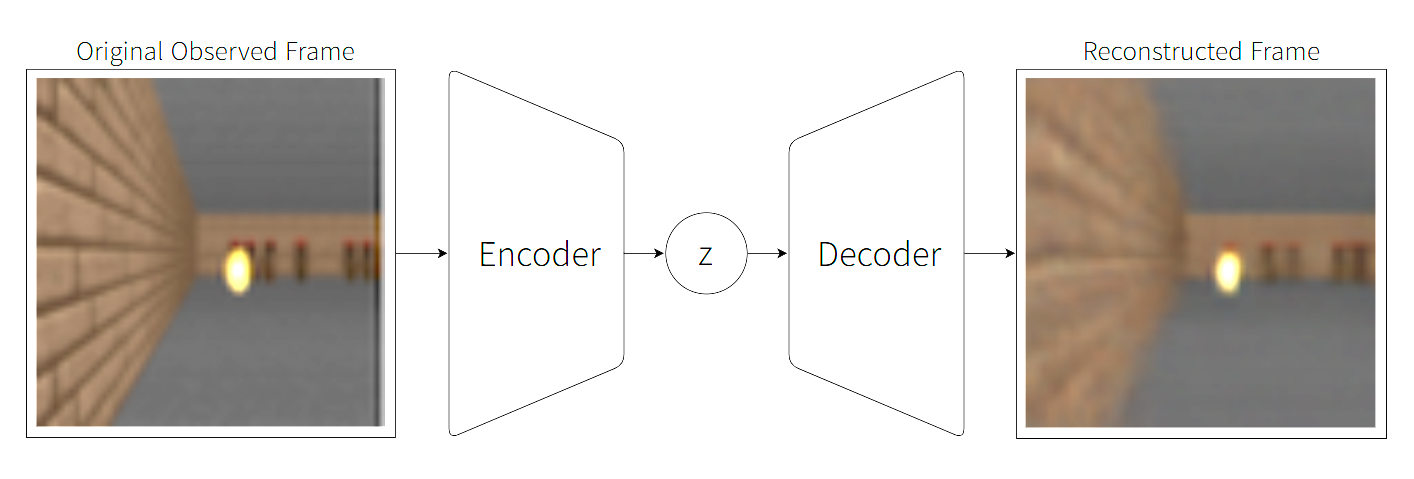
위의 그림은 이러한 과정을 보여주는 예입니다. 왼쪽의 원본 이미지(Observation Frame)는 VAE(Variational Autoencoder)의 인코더(Encoder)를 통해 하나의 잠재 벡터 z로 압축되고, 디코더(Decoder)에 의해 복원된 이미지(Reconstructed Frame)가 오른쪽에 나타납니다. 이 잠재 벡터 z는 현재 시점의 관측 정보를 요약한 벡터로, 이후 Memory Model이나 Controller가 처리하게 될 입력으로 사용됩니다. 이때 중요한 점은 생성된 z가 미래 상태를 예측하는 데 필요한 정보는 보존하되, 배경처럼 불필요한 세부 정보는 제거되도록 학습된다는 점입니다.
Memory Model
이제 Vision Model로부터 얻은 잠재 표현과 에이전트의 행동을 바탕으로 그에 따라 환경이 어떻게 변화할지를 예측하는 단계가 필요합니다. 이 과정은 세계 모델에서 매우 핵심적인 역할을 하는데요. 바로 시간에 따라 변화하는 환경의 규칙을 기억하고 예측하는 기능입니다. 이러한 역할을 수행하는 것이 바로 Memory Model입니다.
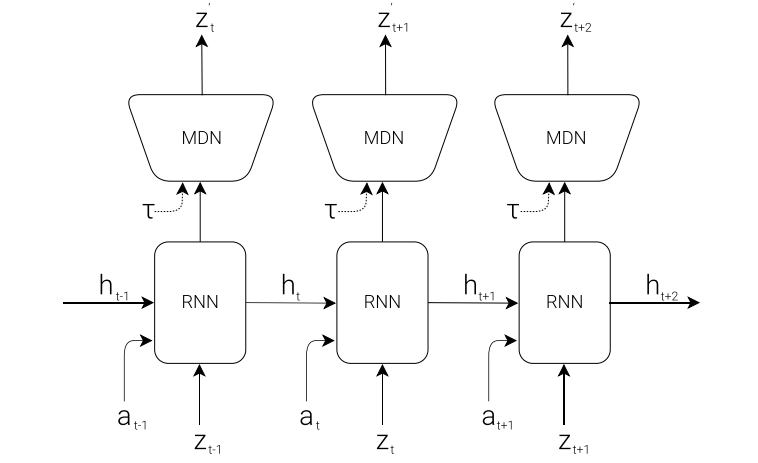
World Models 논문에서는 이 Memory Model로 MDN-RNN(Mixture Density Network + Recurrent Neural Network) 구조를 사용합니다. 이 모델은 과거의 잠재 상태와 행동 정보를 순차적으로(Sequentially) 통합하고, 이를 바탕으로 미래의 잠재 상태가 어떻게 변화할지를 확률적으로 예측합니다.
|
|
|
RNN이 과거의 상태를 기억하여 현재 정보를 처리한다면, MDN(Mixture Density Network)은 그 정보를 바탕으로 다음 잠재 상태의 확률 분포를 출력합니다. 이 구조는 다음 상태를 하나의 값으로 예측하는 것이 아니라 여러 개의 가우시안 분포의 혼합을 통해 확률적으로 모델링합니다. 이를 통해 모델은 환경의 불확실성까지 반영할 수 있게 됩니다.
2020년에 발표된 RL 에이전트인 Dreamer는 이 개념을 확장합니다. Dreamer는 세상을 잠재 공간(Latent Space)에서 모델링하며, 다음 상태를 확률적으로 예측하는 구조를 따릅니다. 특히 단순히 확률 분포만 사용하는 것이 아니라 RNN의 순차적인 정보 처리 능력까지 함께 활용하는데, 이를 RSSM(Recurrent State-Space Model)이라고 부릅니다. Dreamer의 RSSM은 시간적으로 누적된 정보를 담는 결정적 상태(Deterministic State)와 한 번의 관측으로는 파악할 수 없는 환경의 불확실성을 담는 확률적 상태(Stochastic State)로 나뉘는데요. 이 두 상태는 함께 다음 잠재 상태를 예측하고 필요하다면 다음 시점의 이미지를 복원하는 데에도 사용될 수 있습니다. 마치 인간이 과거 경험을 바탕으로 '이 상황에서 이런 행동을 하면 이렇게 될 거야.'라고 미래를 상상하는 사고 과정과 유사합니다.
Controller
마지막 구성 요소인 Controller는 예측된 잠재 상태를 바탕으로 어떤 행동을 취할지 결정하는 모듈입니다. 흥미롭게도 이상적인 세계 모델 체계에서는 이 Controller를 가능한 한 단순하게 설계하는 것이 바람직합니다. 왜냐하면 Memory Model이 이미 환경의 복잡한 규칙과 시간적 패턴을 충분히 학습했기 때문입니다. 따라서 Controller는 복잡한 사고를 담당하기보다는, Memory Model이 제공하는 정보(예측된 상태)를 바탕으로 어떻게 행동하면 보상을 극대화할 수 있을지를 판단합니다. 이러한 구조는 "상상력은 세계 모델이 담당하고 판단은 컨트롤러가 맡는다."는 명확한 역할 분담에 기반한 설계라고 볼 수 있습니다. |
|
|
위에서 말했듯 기존의 세계 모델은 보통 다음과 같은 구조를 따릅니다.
“이미지 관측 → VAE → 잠재 표현(Latent Representation) → Dynamics Model → 잠재 상태(Latent State, z) 예측 → 디코더로 이미지 복원”
이 방식은 계산 효율이 높고 구조도 단순하지만 VAE 등으로 고해상도 시각 정보를 압축하는 과정에서 세부 정보가 손실되는 문제가 존재합니다. 특히 예측된 다음 상태가 저차원의 잠재 상태 형태이기 때문에, 이를 디코딩할 때 이미지의 품질이 떨어지는 경우가 많았습니다. 특히 자율주행, 로봇 제어처럼 정밀한 시각적 예측이 요구될 경우 성능 저하로 이어졌습니다.
이러한 한계를 극복하기 위해 등장한 것이 확산 모델(Diffusion Model) 기반의 세계 모델입니다. 확산 모델은 간단히 말해 깨끗한 입력 이미지에 점진적으로 노이즈를 추가한 뒤, 이 노이즈를 거꾸로 지워가며 다시 원본을 복원하는 과정을 학습하는 모델입니다. 이러한 노이징-디노이징 과정을 통해 모델은 세밀한 픽셀 단위의 정보를 유지한 채 이미지를 생성할 수 있습니다. 기존 방식처럼 잠재 공간에서 간접적으로 예측하는 것이 아니라, 직접 픽셀 공간에서 이미지를 예측한다는 점이 큰 차이입니다. |
|
|
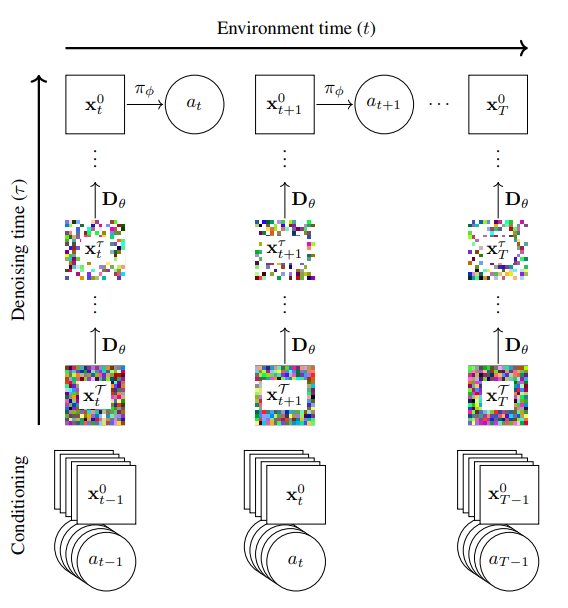
출처: Diffusion for World Modeling: Visual Details Matter in Atari (Alonso et al. 2024)
2024년 NeurIPS에서 발표된 DIAMOND는 확산 모델을 세계 모델에 적용한 사례입니다. DIAMOND는 과거 에이전트의 행동과 프레임을 조건으로 입력받고 노이즈에서부터 다음 프레임 이미지를 한 장 한 장 디노이징하며 생성합니다. 마치 사람이 머릿속에서 장면을 상상하듯 AI가 꿈을 꾸듯 환경을 시뮬레이션하는 것이죠.
해당 이미지에서 수평축(Environment time)은 실제 환경에서의 흐름을 말하며 수직축(Denoising time)은 확산 모델 내부에서의 역확산 과정입니다. 위로 갈수록 점점 노이즈가 제거되면서 깨끗한 관측값으로 복원되는 것이죠. Condition의 경우 이전까지의 관측값과 행동 등을 바탕으로 지금 시점에서 ‘어떤 미래 상태’를 상상할지를 조건으로 설정합니다. t 시점에서의 상태를 노이즈가 가득한 값으로 랜덤하게 초기화한 후, 확산 모델을 여러 번 호출해 노이즈를 점점 줄여갑니다. 이 과정은 마치 머릿속으로 미래를 상상하면서 점점 선명하게 그려내는 과정이라고 생각하시면 됩니다. 이를 통해 만들어진 x_t 값은 모델이 상상한 t 시점의 미래 모습이며 x_t를 본 후 정책은 다음 행동을 선택합니다. 그럼 해당 행동은 다시 상상을 위한 조건으로 쓰이며 반복적으로 시뮬레이션을 돌리게 되죠.
이러한 방식은 더 직관적이고 정밀한 미래 예측을 가능하게 만들며, 특히 로봇 제어, 영상 기반 시뮬레이션 등 시각 정보가 핵심인 분야에서 강력한 성능을 발휘할 수 있습니다.
|
|
|
World Model은 인간의 상상력과 같을까? |
|
|
세계 모델은 에이전트가 환경을 이해하고 예측하는 능력의 핵심 축으로 자리잡고 있습니다. 초기에는 단순한 게임 환경에서 시작되었지만 이제는 고도화된 생성 모델의 통합, 멀티모달 학습, 복잡한 다중 에이전트 환경까지 그 영역을 넓혀가고 있죠.
2025년 세계적인 과학 저널인 Nature에 게재된 DreamerV3은 150여 가지 다양한 작업에서 사전 지식 없이도 최고 수준의 성능을 내며, 심지어 인간 지식 없이 픽셀 관측만으로 마인크래프트에서 다이아몬드를 얻는 난제까지 해결해냈습니다.
세계 모델은 AI에게 눈과 기억을 부여할 뿐만 아니라 현실을 겪지 않고도 미래를 예측하고 상상 속에서 학습할 수 있는 능력을 쥐어줬습니다. 이제 AI는 자신만의 세계에서 수없이 상상하고 시뮬레이션하며 훈련합니다. 그리고 그 상상 끝에 현실 세계에서도 놀라운 성과를 만들어냅니다. 우리는 이 능력을 인간과 같은 ‘상상력’이라고 부를 수 있을까요? 그렇다면 이제, 인간과 AI를 가르는 경계는 어디에 남아 있을까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|