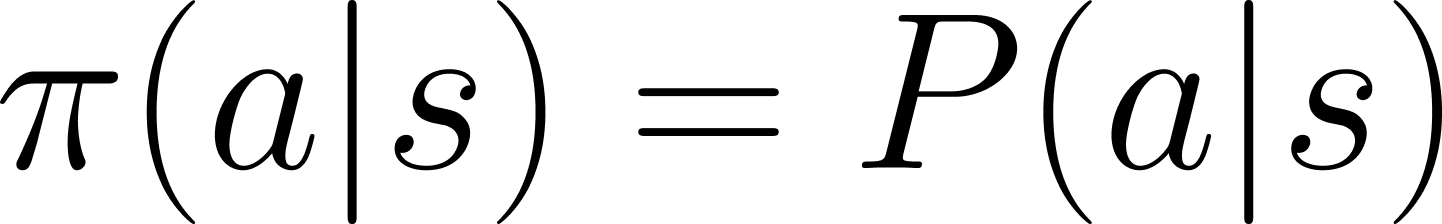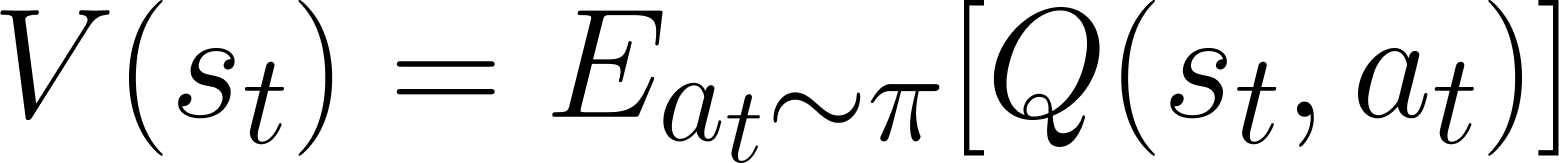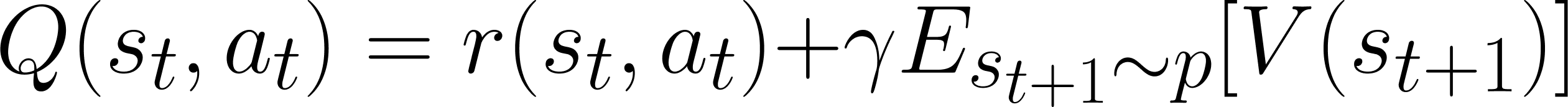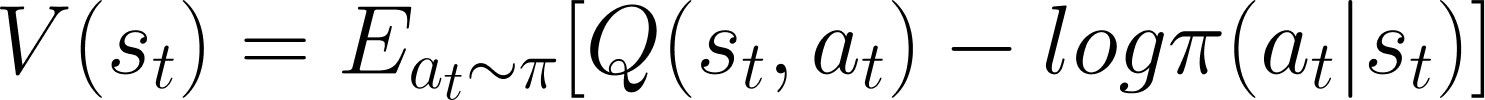로봇이 실제 환경과 상호작용할 때 마주하는 어려움을 이해하고, 이를 해결하기 위한 강화학습의 네가지 방법들을 #98 위클리 딥 다이브 | 2025년 7월 2일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 현실 세계에서의 강화학습 적용 문제를 다뤘습니다.
- On-policy와 Off-policy 알고리즘의 차이점과 Off-policy의 장점을 정리했습니다.
- Soft Actor-Critic(SAC) 알고리즘을 소개했습니다.
|
|
|
현실 세계에 강화학습을 적용하기 위한 네가지 방법 |
|
|
안녕하세요, 에디터 잭잭입니다.
강화학습은 2016년 이세돌과 알파고의 대결처럼, 인간을 능가하는 성능을 보여주며 큰 주목을 받았습니다. 그렇다면 온라인 시뮬레이션에서 좋은 성능을 달성한 에이전트가 현실 세계에서도 똑같이 잘 동작할 수 있을까요? |
|
|
오늘은 로봇이 실제 환경과 상호작용할 때 마주하는 어려움을 이해하고, 이를 해결하기 위한 강화학습의 네가지 방법들을 알아보려고 해요. 또한 강화학습 논문을 처음 읽으면 헷갈릴 수 있는 개념들에 대해서 이해하기 쉽게 풀어봤습니다. |
|
|
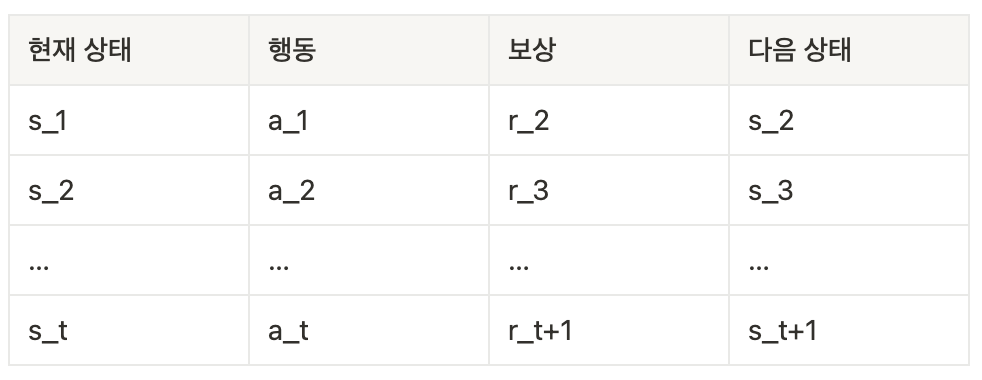
현실 세계와 온라인 시뮬레이션의 가장 큰 차이는, 로봇이 취할 수 있는 행동 공간(Action Space)에 있습니다. 게임 환경에서는 모델이 취할 수 있는 행동이 ‘상하좌우’처럼 이산적인(Discrete) 움직임으로 제한됩니다. 따라서 상태별로 가능한 행동과 그에 따른 보상은 명확하게 정의된 표로 정리할 수 있죠. |
|
|
하지만 현실 세계에서는 상황이 달라요. 특정 상태에서 로봇이 취할 수 있는 행동은 연속적(Continuous)이기 때문에, 그에 따른 보상이나 다음 상태(Next state)를 모두 표에 적을 수 없습니다. 연속적인 행동 공간이란, 로봇의 행동이 실수(Real number) 범위 안에 있다는 것을 의미합니다. 예를 들어 앞으로 한 발자국 이동할 때 다리를 몇 도 회전시킬지, 다리를 얼마만큼 들어 올릴지 등을 정확한 실수 값으로 제어해야 해요. |
|
|
본격적인 내용으로 넘어가기 전에 강화학습에서 매우 중요한 개념인 정책(Policy)과 가치(Value)에 대해 간단히 짚고 넘어갈게요.
먼저, 정책 π는 상태 s가 주어졌을 때 행동 a를 선택할 확률을 나타냅니다. |
|
|
다음으로, 가치(Value)는 어떤 상태나 행동이 얼마나 좋은지를 누적 기대 보상을 통해 정량적으로 평가하는 함수입니다. 가치함수는 상태 가치함수(V)와 상태-행동 가치함수(Q)의 두 종류가 있어요.
그 중 상태 가치함수인 V(s_t)는 특정 상태 s_t가 얼마나 좋은지를 평가합니다. |
|
|
그리고 상태-행동 가치함수 Q(s_t, a_t)는 특정 상태 s_t에서 행동 a_t를 취했을 때 기대되는 누적 보상을 평가합니다. r_t는 보상을, γ는 다음 상태의 가치에 대한 할인율을 의미해요(0≤γ≤1). |
|
|
일반적으로는 상태 가치함수(V)보다 상태-행동 가치함수(Q)를 더 많이 사용합니다. |
|
|
강화학습 알고리즘은 데이터로부터 정책을 어떻게 학습하느냐에 따라 크게 두 가지 방식으로 나눌 수 있습니다. 현실 세계에서의 문제를 해결하기 위해 최근에는 Off-policy 강화학습이 유행하고 있는데, 그 이유가 뭘까요? |
|
|
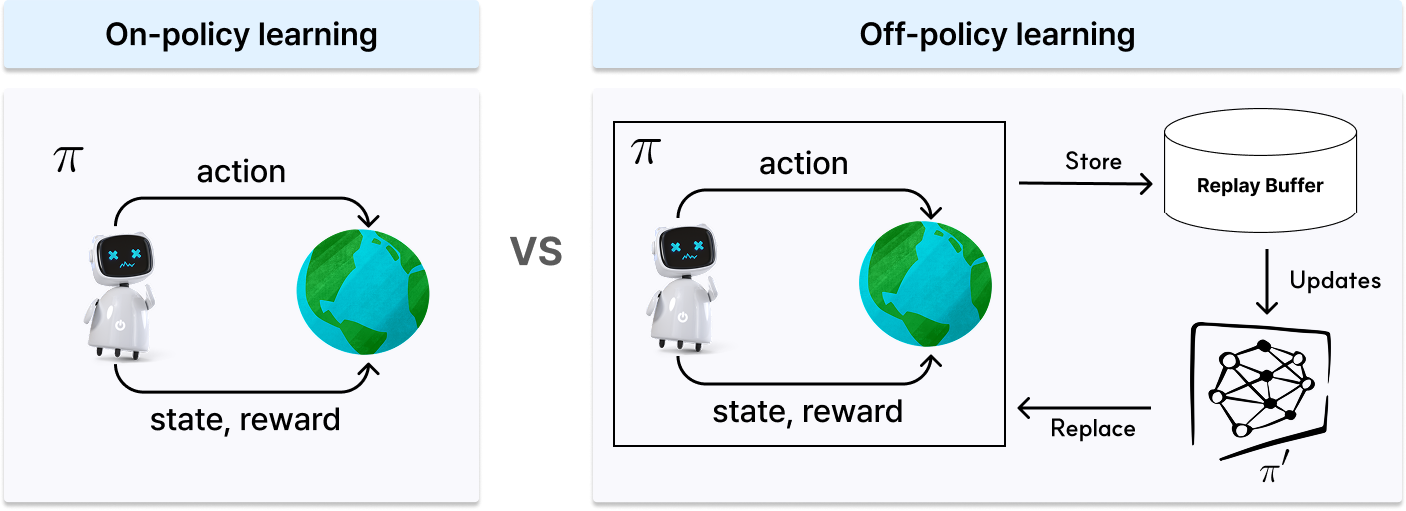
출처: ⓒ deep daiv.
이유를 알아보기에 앞서, 먼저 On-policy 강화학습에 대해 알아보겠습니다. 그림의 왼쪽과 같이 에이전트는 현재 학습 중인 정책(π)을 바탕으로 직접 환경과 상호작용하며 데이터를 수집하고, 그 데이터로부터 실시간으로 학습해요. 따라서 On-policy는 최신 데이터에 기반한 학습이 가능하다는 장점이 있습니다. 하지만 수집한 데이터를 재사용할 수 없기 때문에 학습 효율이 낮고, 많은 양의 데이터를 반복적으로 수집해야 하는 부담이 커요.
반면 Off-policy 강화학습은 과거에 수집된 데이터를 계속 활용할 수 있습니다. 이를 위해 보통 리플레이 버퍼(Replay Buffer)를 사용하여, 에이전트가 환경과 상호작용하며 얻은 상태(State), 행동(Action), 보상(Reward) 등의 데이터를 저장해 두고, 학습 시 이 데이터를 반복적으로 샘플링하여 사용해요. 이 방식은 이전의 데이터를 저장해 두었다가 다시 사용할 수 있기 때문에 샘플 효율성이 높습니다.
따라서 현실 세계에서는 실시간 학습이 끝나면 처음부터 데이터를 다시 수집해야 하는 On-policy 알고리즘 보다, 과거의 데이터를 저장해 두고 이로부터 학습할 수 있는 Off-policy 알고리즘이 더 널리 사용되고 있어요.
|
|
|
강화학습 알고리즘은 크게 Model-based와 Model-free로 나눌 수 있어요. 연속적인 행동 공간을 다루는 문제는 그 중에서도 Model-free 강화학습에서 활발히 연구되고 있습니다. |
|
|
출처: ⓒ deep daiv.
Model-free란, 어떤 행동을 취했을 때 환경이 어떻게 반응할지를 알지 못한 상태에서 학습하는 것을 말해요. 특정 상태에서 어떤 행동을 취했을 때, 이에 대한 보상과 미래의 상태를 알 수 없다는 뜻입니다. 참고로, 반대말인 Model-based는 환경 변화에 대한 정보를 모두 알 수 있다는 뜻이에요.
Model-free 강화학습은 어떤 함수를 학습의 중심에 두느냐에 따라 세가지로 나눌 수 있는데요. 오늘 다루고자 하는 SAC는 그중에서도 Actor-critic 계열에 속합니다.
Actor-critic에 대해 간단히 설명하자면, 두 개의 주요 구성요소인 Actor와 Critic으로 나뉘어 동작해요. Actor는 정책(Policy)을 담당하고, Critic은 가치(Value)를 평가하는 역할입니다. Actor가 선택한 행동이 얼마나 좋은지 피드백을 주기 위해, Critic은 상태-행동 쌍에 대한 가치함수인 Q(s, a)를 근사하는 방법이에요. |
|
|
방법 3. 딥 뉴럴 네트워크를 통한 함수 근사(Approximation) |
|
|
현실 세계는 행동 공간이 연속적이고(Continuous), 환경에 대한 정보도 알 수 없습니다(Model-free). 이로 인해 현실세계에서는 강화학습의 목표인 ‘최적 정책을 구하는 것’은 온라인 시뮬레이션(Model-based)에서 수행하는 것보다 훨씬 어려울 수밖에 없는데요.
특히 행동 공간이 연속적일 경우, 모델은 무한한 수의 행동 중에서 선택을 해야 하므로 정책이나 가치 함수를 수치적으로 직접 계산하는 것이 매우 어렵습니다. 예를 들어, 상태가 2개이고 행동이 2개뿐이라면 상태-행동 쌍은 총 4가지에 불과하므로, 모든 경우에 대해 보상을 직접 계산하고 표로 정리할 수 있습니다. 상태가 100개이고, 각 상태마다 취할 수 있는 행동이 100개 라면, 이 경우 상태-행동 쌍은 100×100=10,000개에 달하지만 역시 표에 정리할 수 있겠죠.
그러나 만약 행동이 실수 범위의 연속 값이라면, 가능한 행동의 수는 무한대가 되어 각 상태-행동 쌍(State-action pair)에 대해 기대 보상을 정의하는 함수인 Q(s, a)를 표 형태로 저장하거나 정확히 계산하는 것은 불가능해집니다. |
|
|
이처럼 고차원 연속 공간에서는 전통적인 방식으로는 학습이 어려워지기 때문에 딥 뉴럴 네트워크(Deep Neural Network)를 이용해 이러한 함수들을 근사(Approximate) 해야 해요. 2015년 Google DeepMind는 Deterministic Policy Gradient(DPG) 알고리즘에 이론에 딥 뉴럴 네트워크를 결합한 DDPG 연구를 통해 딥러닝 기반의 연속 제어(Continuous Control) 강화학습 알고리즘의 가능성을 보여주었습니다.
그러나 DDPG는 하이퍼파라미터 설정이 매우 민감하여 학습이 어렵다는 한계가 있었습니다. |
|
|
방법 4. 다양한 행동을 탐색하다: Soft Actor-Critic |
|
|
위 문제를 해결하기 위해 SAC는 목적 함수에 엔트로피(무작위성) 항을 추가합니다. 이는 에이전트가 단순히 높은 보상을 주는 행동만 반복하지 않고, 다양한 행동을 시도할 수 있도록 유도하기 위함이에요.
따라서 SAC는 가치 함수인 V(s)를 최대화하기 위해 엔트로피 항인 -log π(a|s) 를 최대화하는 방향으로 정책을 업데이트합니다. |
|
|
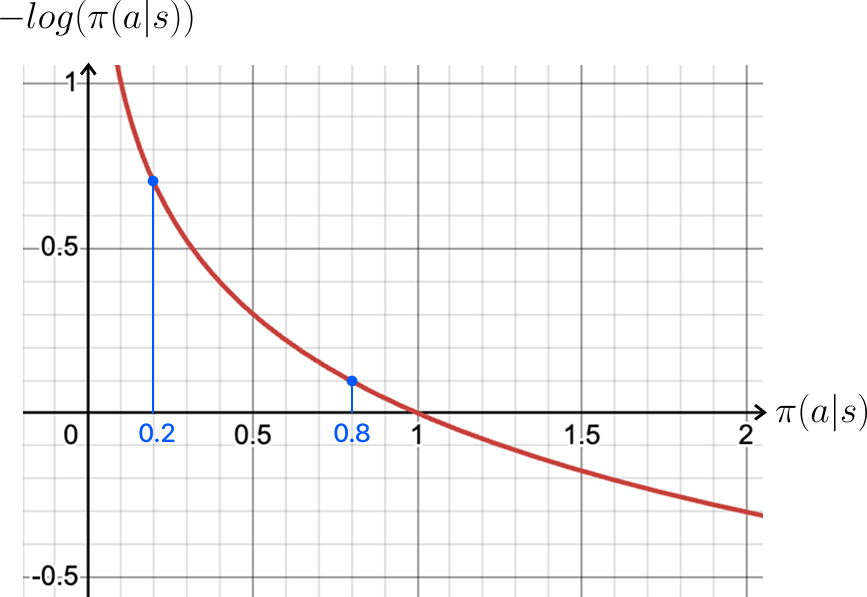
출처: ⓒ deep daiv.
이해하기 쉽게 그래프를 통해 알아보려고 해요. π(a|s)는 상태 s에서 특정 행동 a를 선택할 확률 분포를 의미하므로, 그 값은 0보다 크고 1 이하의 범위를 가집니다 (0<π(a|s) ≤1). 여기에 -log 함수를 적용하면, 확률이 클수록 값은 작아지고 확률이 작을수록 값은 커지겠죠?
따라서 선택 확률이 낮은 행동일수록 더 큰 값을 가지게 되므로, 에이전트는 선택 확률이 낮은 행동을 선택함으로써 다양한 행동을 수행하도록 유도됩니다. 이러한 방식은 새로운 행동을 탐색하게 하고, 탐색(Explore)과 활용(Exploit) 사이의 균형을 유지하는 데 중요한 역할을 해요.
이처럼 SAC는 다양한 상황에 유연하게 대응할 수 있는 정책을 만들어 내기 때문에, 현실 세계와 같이 복잡하고 불확실한 환경에서 특히 효과적인 방법이라고 할 수 있습니다. |
|
|
아래는 프랑스의 고등학교 졸업 논술 시험인 바칼로레아(Baccalauréat)에서 나온 문제입니다. 스스로 해답을 내리지 못한 이 질문에 대한 여러분들의 의견이 궁금합니다. "우리의 미래는 기술에 달려 있는가?"
제가 수강중인 수업(TMI: 동양사의 이해)의 교수님께서는 역사란 과거를 분석하는 것에서 그치는 것이 아니라, 현재와 미래에 올바른 결정을 하기 위해 역사가 존재한다고 말씀하셨어요. 그러나 저는 우리의 미래를 위해 인공지능 기술이 어디로 나아가야 할지에 대한 해답을 역사로부터 찾아내지는 못했고, 대신 세 가지 궁금증이 생겼습니다.
첫째, 역사를 살펴 보면 인간 문명은 도구와 함께 발전한 양상을 보입니다. 그러나 도구를 중심으로 해석하면 도구가 인간을 발전시킨 것으로, 철학을 중심으로 해석하면 철학이 인간을 발전시킨 것으로 보이겠죠.
둘째, 인공지능과 같이 인간을 초월하는 도구는 과거에 존재하지 않았습니다. 인공지능을 과연 ‘도구’라고 정의할 수 있을지 궁금합니다.
셋째, 인간이 미래에 궁극적으로 추구하는 행복이란 무엇일까요?
오늘도 읽어주셔서 감사합니다. ☺️
|
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|