LLM은 같은 질문에 대해 항상 같은 답변을 내놓을까요? LLM의 재현성에 대해 다시 생각해 봅니다. #97 위클리 딥 다이브 | 2025년 6월 25일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 재현성(Reproducibility)의 개념을 정리합니다.
- LLM의 추론 결과가 일정하지 않은 이유를 설명합니다.
- 결과의 재현성을 확보하기 위한 방법인 LayerCast를 소개합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
이제 인공지능에게 사소한 일을 대신 하도록 맡기는 건 일상이 되었습니다. 때로는 꽤 중요도가 높은 일을 할 때도 인공지능에게 도움을 받는 것이 그리 낯설지는 않습니다. 그러다 보면 AI의 성능이 놀라울 정도로 발전했다는 생각이 들기도 하고, 결국 언젠가는 전문가의 의사결정을 대신할 수도 있지 않을까 하는 생각도 듭니다.
하지만 많은 사람들이 여전히 블랙박스에 가까운 LLM의 결정은 신뢰하기 어렵다고 이야기합니다. 그런데 LLM이 대체할 수 없는 것이 전문가의 설명하기 어려운 노하우라면 그것마저도 블랙박스가 아닌가라는 생각이 듭니다. 게다가 인간은 상황에 따라 원래는 맞힐 수 있는 문제를 틀리기도 합니다. 반면 LLM은 일단 한번 틀린 문제는 다음에도 틀릴 것이고, 한번 맞힌 문제는 계속해서 똑같이 맞힐 겁니다. 이런 관점에서 보면 오히려 예측하기 쉬운 쪽은 LLM이 아닐까요?
그런데 최근 발표된 연구에서는 항상 일관된 답변을 내놓을 거라 기대했던 LLM도 사실은 예상치 못한 응답을 할 수도 있다고 말합니다. Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning (Yuan et al., 2025)라는 연구에서는 기존의 예상과는 달리 LLM은 재현성(Reproducibility)이 충분히 확보되지 않았으며, 심지어 추론 모델의 예측 정확도는 최대 9%까지 변동될 수 있다고 밝혔습니다. 그러면 왜 이런 일이 발생하는지 살펴보겠습니다.
|
|
|
먼저 재현성(Reproducibility)이 어떤 개념인지 살펴보겠습니다. 재현성은 실험 결과를 동일한 조건에서 반복했을 때, 원래의 결과가 다시 나타나는 성질을 말합니다. 신뢰할 수 있는 평가 결과는 보통 재현성을 보장합니다. LLM 평가도 마찬가지입니다. 생성형 AI인 LLM은 샘플링이라는 방식을 사용하기 때문에, 원래는 같은 입력에 대해서도 다양한 답변을 생성할 수 있습니다. 하지만 객관적인 평가를 위해서 평가 과정에서는 다양성을 통제하고, 결정론적(Deterministic) 방식인 그리디 디코딩(Greedy Decoding)을 사용합니다.
확률 분포를 바탕으로 출력을 생성하는 샘플링과 다르게, 그리디 디코딩은 매번 가장 높은 확률을 갖는 답변만을 생성하기 때문에 이론적으로는 재현성이 보장된다고 알려져 있습니다. 하지만 이어서 소개할 연구에서는 우리가 평소에 간과하던 부분이 이 이론을 무너뜨리고 결과의 재현성을 해친다고 말합니다. |
|
|
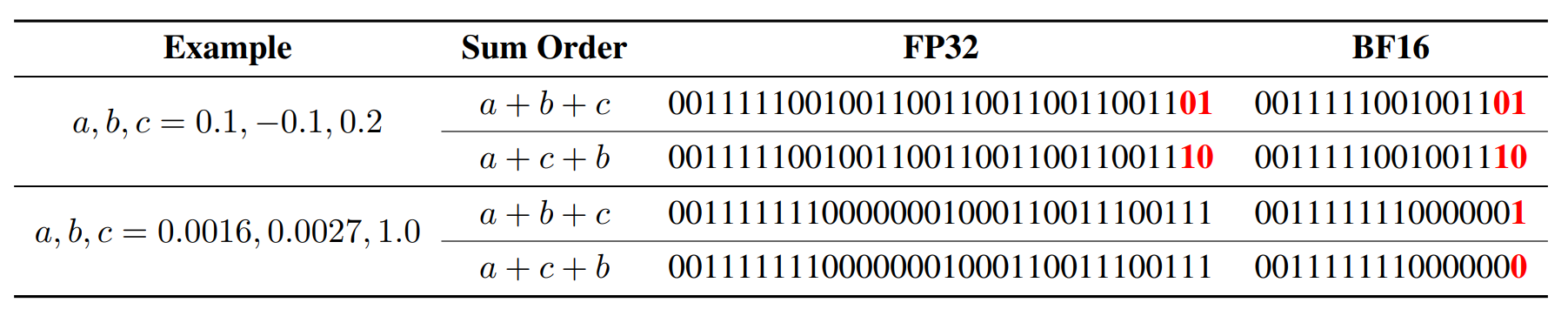
그 이유는 바로 수치 정밀도(Numerical Precision) 때문입니다. 컴퓨터는 부동소수점(Floating Point)이라는 방법을 사용해서 숫자를 표현하는데, 이 방식의 한계 때문에 수치 계산 결과가 우리의 직관과는 다르게 나타날 수 있습니다. 대표적인 예시가 (a+b)+c와 a+(b+c)의 결과가 달라지는, 즉 결합 법칙이 성립하지 않는 현상입니다. 아래 표를 보면 연산 순서에 따라 누적된 반올림 오차에 의한 결과의 차이를 확인할 수 있습니다. |
|
|
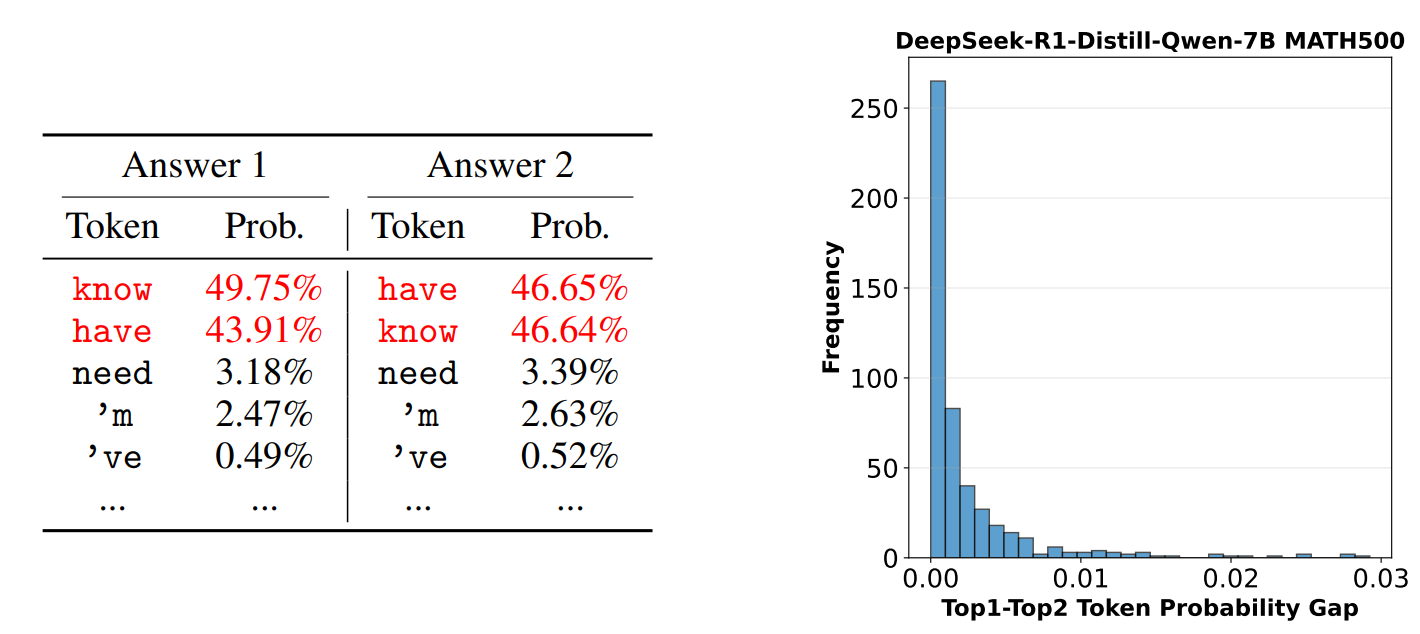
그런데 연산 과정에서 아주 작은 숫자가 달라진다고 한들, 그 결과가 유의미하게 달라질지 의문이 들 수 있습니다. 하지만 아래 실험 결과를 보면 생각이 조금 달라질 겁니다. LLM이 다음 토큰을 예측할 때 가장 높은 확률을 갖는 두 토큰(top-2)을 분석해 보면, 둘 사이의 확률 차이가 매우 작은 경우가 높은 빈도로 발생합니다. 앞서 단 두 번의 연산에서도 작은 차이가 발생했는데, 수십억 개의 파라미터가 상호작용하며 이뤄지는 무수한 연산 이후에는 그 결과가 충분히 달라질 수 있지 않을까요? |
|
|
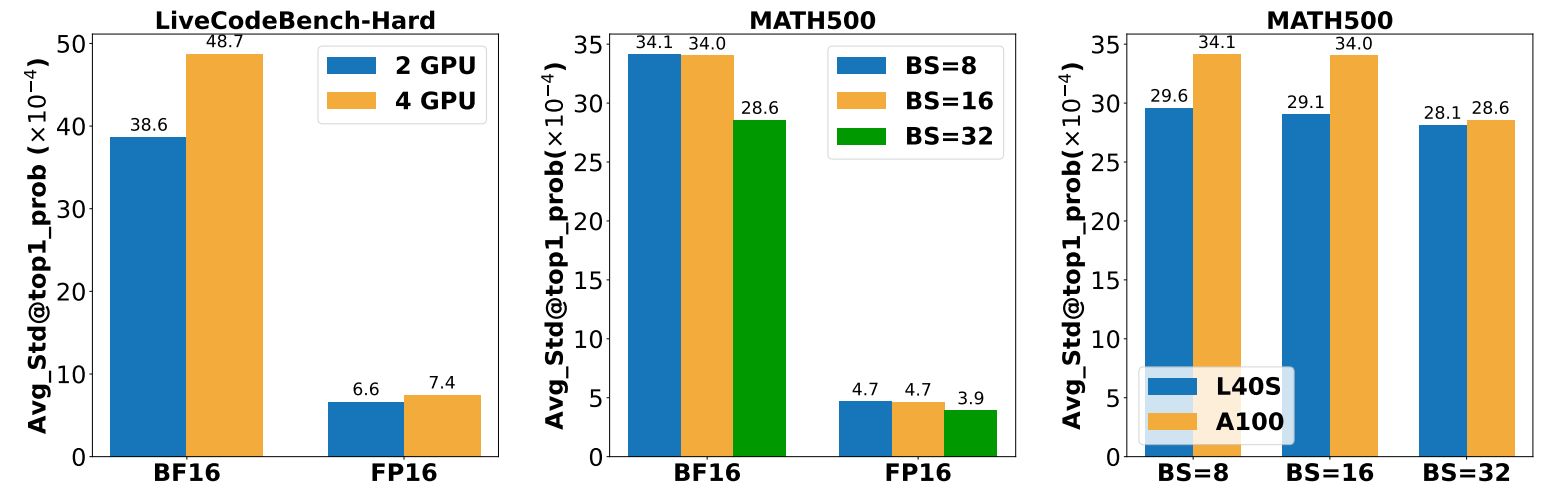
이를 알아보기 위해 연구진은 다양한 요인이 실험 결과에 미치는 영향을 정밀하게 분석했습니다. GPU의 종류, GPU의 개수와 배치 사이즈(Batch Size)를 각각 다르게 설정하고, 각 데이터 타입별로 벤치마크 평가를 여러 차례 반복 수행했습니다. 그리고 동일한 조건에서 진행한 실험들의 표준 편차를 계산했습니다. 놀랍게도 DeepSeek-R1-Distill-Qwen-7B 모델에서 BF16 데이터 타입을 사용했을 때, 동일한 벤치마크에 대한 예측 정확도가 실험마다 최대 9.15%의 차이를 보였습니다. |
|
|
이어서 연구진은 각각의 요인이 독립적으로 결과의 재현성에 미치는 영향을 분석했습니다. 아래 실험 결과를 보면 더 많은 GPU를 사용할수록, 더 작은 배치 사이즈를 사용할수록 결과의 분산이 더 큰 것을 확인할 수 있습니다. 특이한 점은 작은 배치를 사용할수록 분산이 크다는 것인데, 연구진은 작은 배치를 사용할 경우 순차적인 처리 단계(Sequential processing steps)가 증가하여 오류를 누적시킬 수 있다고 해석했습니다. |
|
|
앞서 살펴본 여러 실험들에서 공통적으로 나타나는 현상은 BF16 데이터 타입을 사용할 때 결과의 변동폭이 가장 크다는 점입니다. BF16은 FP32에 비해 적은 메모리를 사용하지만, FP32와 같은 표현력을 갖는다는 장점이 있어 최신 LLM 실험에 널리 사용되는 데이터 타입입니다. 그런데 재현성 확보에 있어서는 가장 불리하다는 점은 매우 치명적인데요.
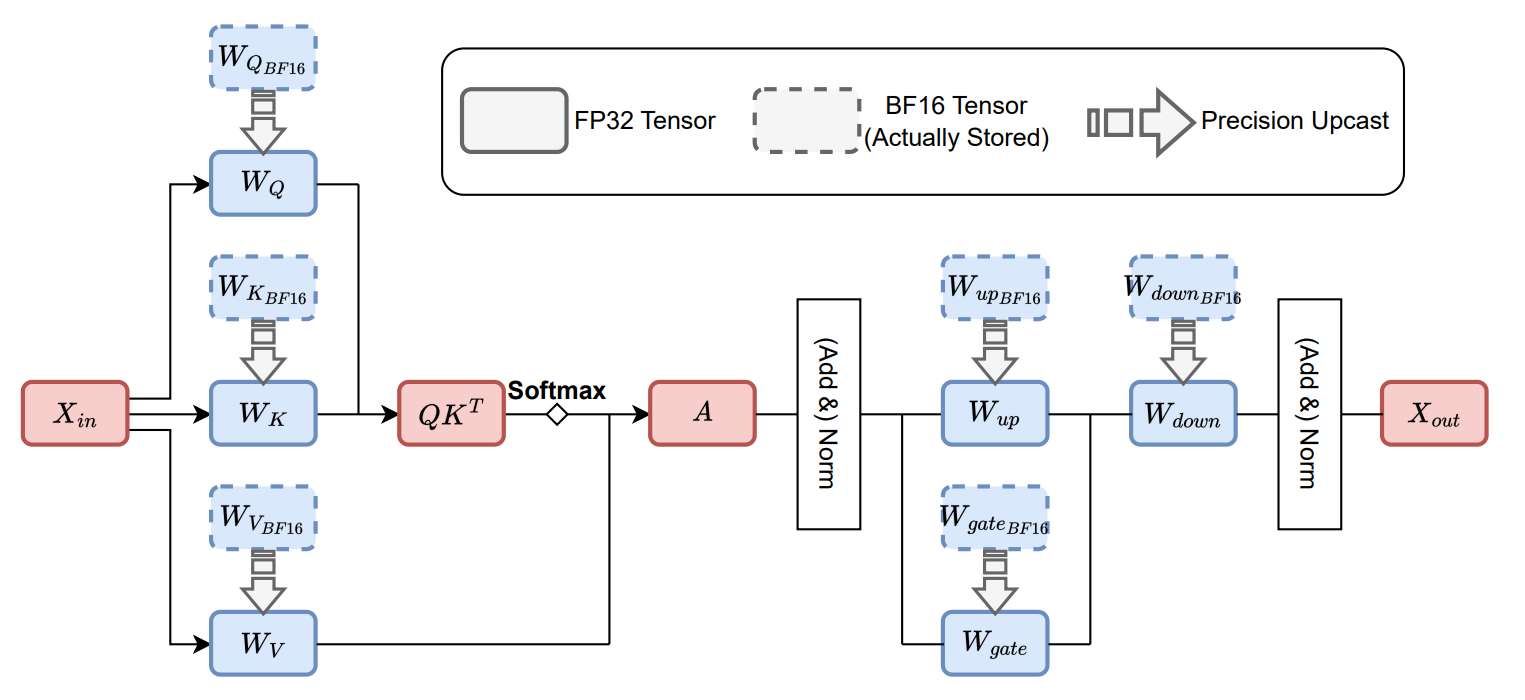
이런 문제를 해결하기 위해 연구진은 LayerCast라는 방법론을 제안합니다. LayerCast는 다음과 같은 과정을 통해 LLM의 추론 과정에서 결과의 재현성과 메모리 효율성 사이의 균형을 조절합니다. 먼저 (1) 모델 파라미터 전체를 FP32 데이터 타입으로 불러오고, (2) 추론 전에는 BF16으로 변환하여 메모리에 저장합니다. 그리고 (3) 특정 가중치 행렬에 대한 행렬곱(Matrix Multiplication)이 수행되는 시점에만 다시 FP32로 해당 행렬의 데이터 타입을 변환합니다. |
|
|
연구진은 LayerCast를 사용하면 거의 완벽하게 재현성을 확보할 수 있다고 합니다. 그렇다면 완벽한 재현성이란 불가능한 것일까요? 현실적으론, 그렇습니다. 실제 추론 과정에서는 행렬 연산을 최적화하기 위해 다양한 기술이 활용되고 있습니다. 그리고 이런 기술은 결정론적인 결과를 보장하지 않습니다. 강제로 결정론적 알고리즘을 사용하도록 할 수는 있지만, 그렇게 하면 연산 속도가 심각하게 저하됩니다.
실제로 연구진에게 직접 메일을 보내 받은 답변에서는, 결정론적 알고리즘을 사용하더라도 결합 법칙이 성립하지 않는(Non-associative) 부동 소수점의 특징 때문에 재현성을 완벽하게 확보하기는 어렵다고 하였습니다. |
|
|
"torch.use_deterministic_algorithms This flag sits one layer above our focus: Key LLM kernels (FlashAttention, Triton fused ops) still lack deterministic implementations, and even with deterministic kernels, FP16/BF16 arithmetic is non-associative. So in short, the flag helps but cannot guarantee bit-exact reproducibility." -Jiayi Yuan |
|
|
안타깝게도 우리가 얻은 결론은 결국 LLM의 추론 결과를 완벽하게 재현할 수는 없다는 것입니다. 그렇다면 이 발견이 LLM의 신뢰성에 치명적인 타격을 주는 것일까요?
물론 LayerCast와 같은 방법을 통해 LLM의 추론 결과의 일관성을 보장하고자 하는 노력은 분명히 중요합니다. AI 기술에 대한 거부감의 근원에는 해석의 어려움이 존재하는데, 여기에 재현이 불가능하다는 성질은 LLM의 신뢰도를 한층 저하시키기 때문입니다.
하지만 불확실성이 과연 LLM만의 문제인지를 생각해 본다면 이건 그리 단순한 문제는 아닙니다. 재현성이 확보되지 않았다는 것, 성능에 변동이 있다는 게 반드시 부정적으로 해석되어야만 하는 건 아닐지도 모릅니다. 논문에서 수행한 실험의 결과는, LLM이 때로는 우리가 기대했던 것보다 더 뛰어난 성능을 보일 수도 있음을 의미하기도 합니다.
인정하기 어렵지만 AI는 이미 많은 영역에서 대부분의 인간보다 뛰어난 능력을 보여주고 있습니다. 그리고 그 영향력이 전파되는 속도조차 우리의 예상을 아득히 뛰어넘고 있습니다. 우리는 이제 매일 아침 새로운 놀라움과 두려움을 동시에 마주할 준비를 해야 하는 시대에 살고 있습니다. 결국 재현성 확보는 선택의 문제로 남게 됩니다. 우리가 원하는 건, 예측할 수 없는 천재인가요? 아니면 신뢰할 수 있는 동반자인가요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|