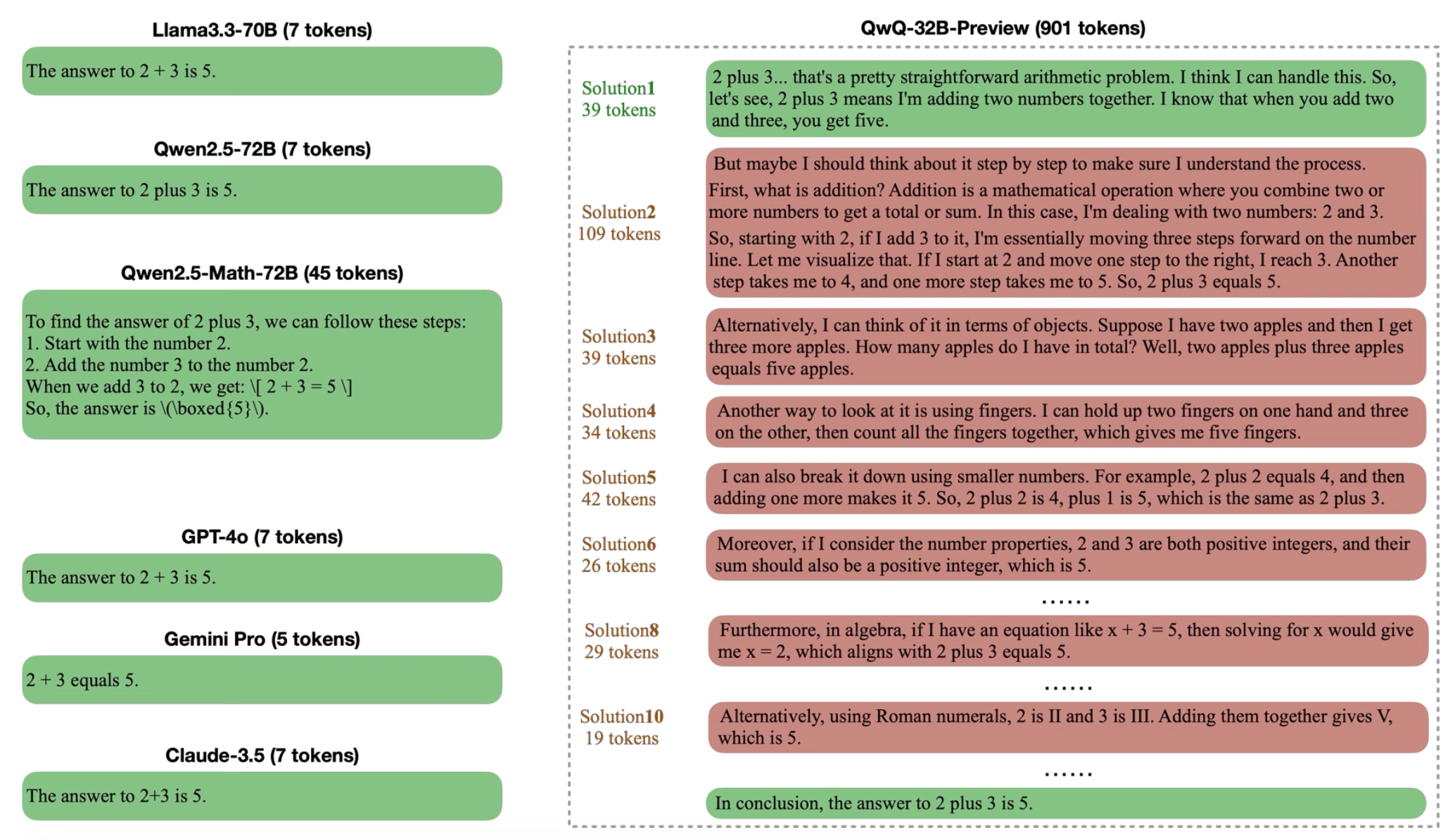
그 예시로 ‘2+3=?’ 이라는 간단한 수학 문제에 대한 답안을 살펴보겠습니다. 왼쪽의 모델들은 대부분 10토큰 이내로 정답을 찾아낸 반면, 오른쪽의 QwQ-32B-Preview 모델은 한 답변에 13개의 답안을 출력하며 총 901개의 토큰을 사용하했습니다. 이처럼 Overthinking이 일어나면 생성하는 토큰과 답안의 수가 불필요하게 많아진다는 문제점이 있어요.
출력의 기여도란, Extended CoT가 출력하는 각 응답이 정답을 찾는데 얼마나 기여하는지를 의미합니다.
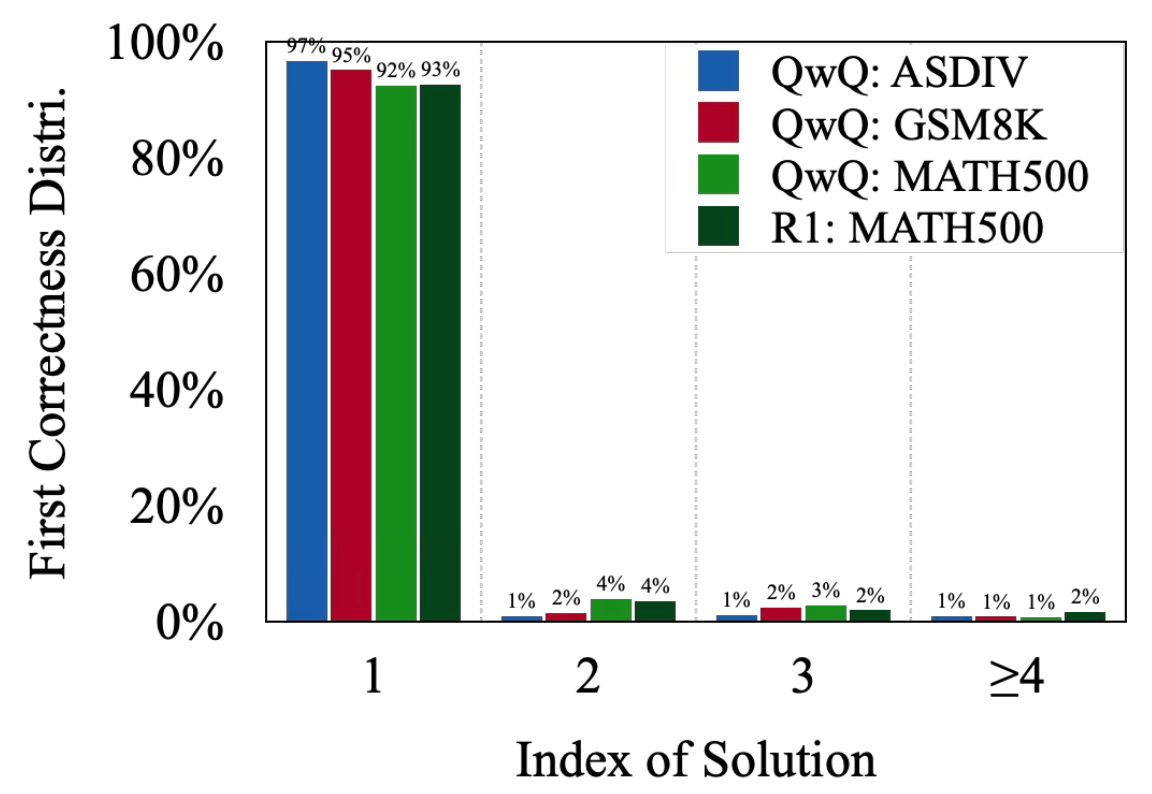
기여도를 파악하기 위한 지표로, 첫 번째 정확성 분포(First correctness distribution)가 있습니다. 이는 모델이 응답에서 올바른 답을 생성하는 모든 경우에 대해, 첫 번째 올바른 답이 나오는 분포를 의미하는데요. 앞선 그림에 나타난 QwQ-32B-Preview 모델의 출력 결과에서, 해결책 1(Solution #1)은 이미 올바른 답안을 제시합니다. 따라서 이후에 출력되는 해결책들은 더이상 정확도를 향상시키는데 기여하지 않는것이죠.
위 도표는 테스트 세트와 모델에 걸친 첫 번째 정확성 분포(First correctness distribution)를 보여줍니다. 첫 번째 해결책이 올바른 답을 제시하는 경우는 92%에 해당하는 것을 확인할 수 있는데요. 이는 Extended CoT가 정확도에 크게 기여하지 않을 수 있다는 점을 시사합니다.
또한 연구자들은 출력한 전체 토큰을 분모로, 정답을 출력하는데 필요한 토큰을 분자로 설정하고, 이렇게 계산한 결과를 출력의 효율성을 평가하기 위한 지표로 제시하였습니다.
출력의 다양성 평가
다음으로 Extended CoT가 출력하는 답변들이 정말 다양한지에 대해 평가합니다.
쉬운 수학 문제를 푸는 방법은 그 해결책이 바로 떠오를 수 있지만, 그럼에도 불구하고 다양한 관점에서 접근하는 것은 이해를 깊게 하고 유연성을 키우는데 도움이 될 수 있어요.
그러면 QwQ-32B-Preview 모델은 ‘2+3=?’ 의 답을 다양하게 생성했는지 다시 한번 확인해 볼까요?
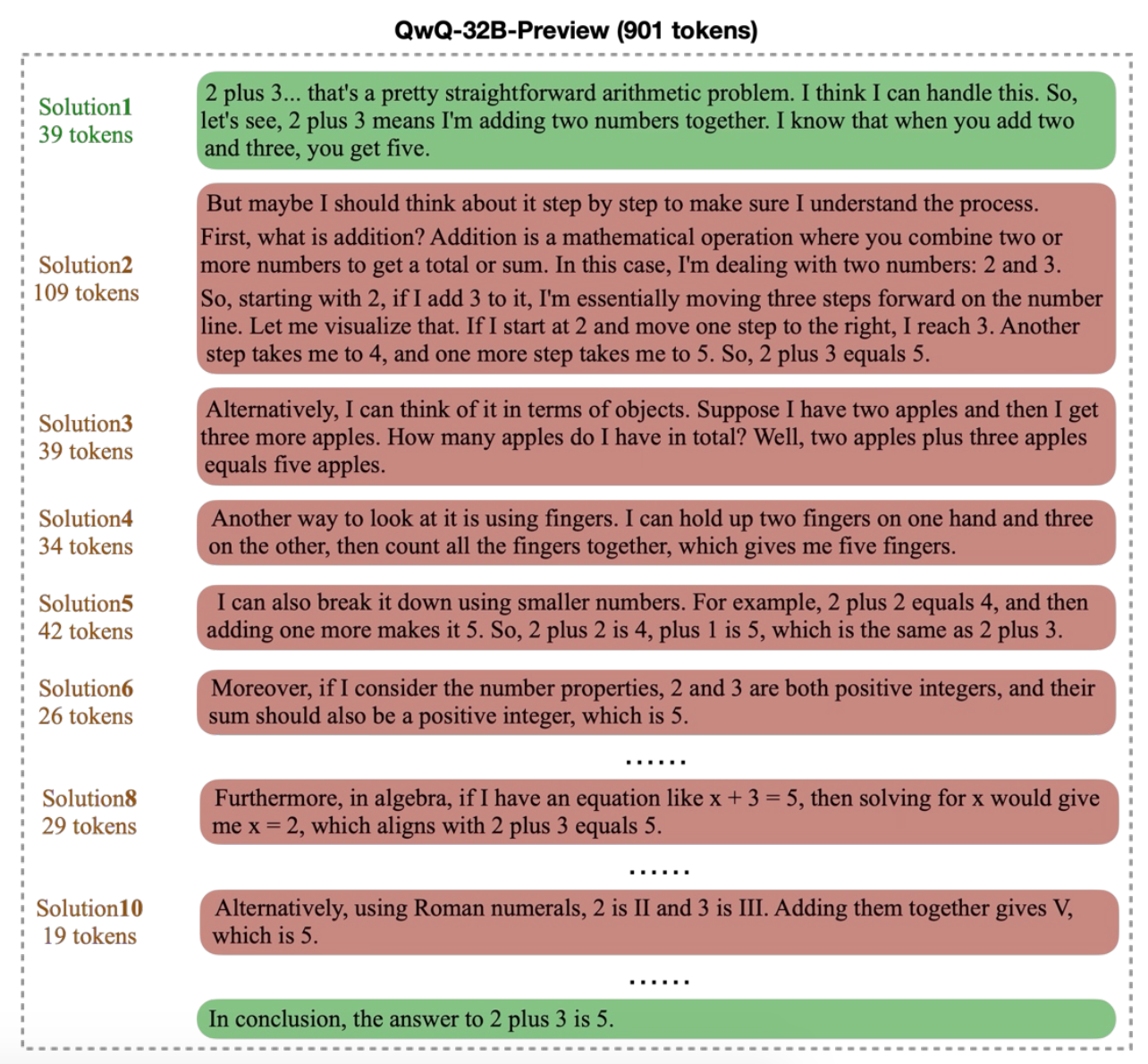
위 그림에서 해결책 1은 2 더하기 3이 5라는 기본 사실을 명시하였고, 해결책 2는 덧셈을 더 작은 단계로 나누어 표현하였으며, 해결책 3은 물체를 세는 방법을 사용하였습니다. 이 세가지 해결책은 서로 다른 관점으로 문제를 해결했다고 볼 수 있어요. 그러나 해결책 4는 해결책 3을 반복하고, 해결책 5는 해결책 2와 유사한 관점에서 접근했습니다.
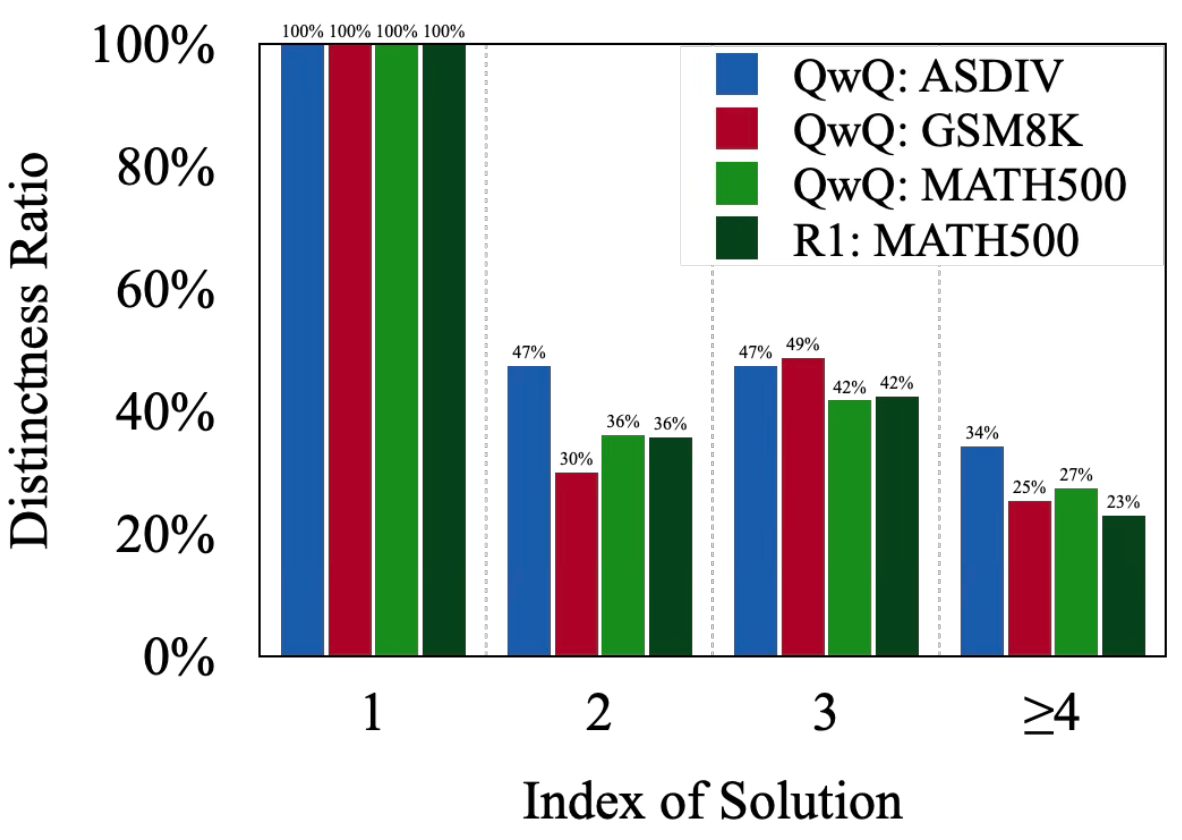
위 도표는 각 해결책에 대한 고유성 비율(Distinctness ratio)을 나타냅니다. X축의 인덱스(Index)는 출력한 해결책의 번호(Solution #N에서의 N)를 의미하고 Y축의 고유성 비율은 인덱스에 해당하는 해결책까지의 답안이 고유한 답안인지를 나타내는 비율이에요.
해결책 1의 비율이 항상 100%인 이유는, 이전에 제시된 해결책이 없어 고유한 해결책으로 평가되기 때문입니다. 그러나 인덱스가 증가할 수록 고유성 비율은 감소하는 경향을 보이는데요, 이를 통해 후속 해결책들이 이전 해결책을 반복하는 경우가 많음을 정량적으로 파악할 수 있습니다.
저도 최근에 ‘Efficient CoT’를 알게 되었는데요, CoT의 추론 능력을 유지하면서, 출력되는 토큰의 양을 줄여 시간과 비용을 효율적으로 개선하기 위한 연구 분야입니다. 이와 관련하여 새로운 방법론은 제안한 논문을 하나 추천드리고 뉴스레터를 마무리하려고 합니다.