파라미터 효율적인 파인 튜닝이 무엇인지 알아봅니다. # 72 위클리 딥 다이브 | 2025년 1월 1일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 파라미터 효율적인 파인 튜닝(PEFT) 개념을 정리합니다.
- 대표적인 PEFT 방법론인 LoRA를 소개합니다.
- LoRA의 다양한 응용 중 하나인 GaLore를 살펴봅니다.
|
|
|
안녕하세요, 에디터 민재입니다.
2024년 한 해가 가고 새해가 밝았습니다. 모두 새해 복 많이 받으세요!
흥미로운 기술에 그쳤을 뿐인 인공지능은 이제 반박할 수 없을 정도로 큰 흐름을 만들고 있습니다. 인공지능 모델은 분야를 막론하고 놀라운 성능을 보여주며, 매일 우리를 놀라게 하지만 한 가지 큰 문제를 갖고 있습니다. 바로 규모입니다. AI 모델이 갖는 파라미터의 수가 과도하게 많아지면서, 이제 이 분야는 더 이상 연구실의 것이 아니게 되었습니다. 모델 학습에 필요한 자원이 천문학적으로 늘어나며, 거대 기업에서만 이 비용을 감당할 수 있게 되었죠. 그래서 이제는 어떻게 하면 모델을 효율적으로 훈련할 수 있을지 고민하는 시기입니다.
이런 문제를 해결하기 위한 연구 분야를 파라미터 효율적인 파인 튜닝(Parameter Efficient Fine Tuning, PEFT)이라고 합니다. 모델이 갖는 전체 파라미터를 학습하는 대신, 그중 일부만 효율적으로 학습하여 성능은 보장하되, 학습 비용을 크게 절감하려는 목적이죠. 의도는 좋지만, 이게 어떻게 가능할까요?
그 이유를 알아보기 위해 먼저 AI 모델의 학습 과정을 살펴보면, 이 과정은 두 가지 단계로 이뤄집니다. 첫 번째는 사전 학습(Pre-training)인데, 이 단계에서는 방대한 양의 데이터를 학습하며 분야를 한정하지 않고 전반적인 지식을 모두 익힙니다. 그다음 파인 튜닝(Fine Tuning) 단계에서는 특정한 분야의 지식을 집중적으로 학습합니다. LLM을 예로 들면, 사전 학습 단계에서 언어를 통해 세상의 지식을 이해하는 방법을 익히고, 파인 튜닝 단계에서 수학 문제 풀이, 코딩과 같이 특정한 작업에 대한 전문성을 높이는 것이죠.
여기서 눈치채셨을 수도 있는데, PEFT의 목적은 바로 파인 튜닝 단계에서의 학습 비용을 절감하는 것입니다. 이미 사전 학습 단게에서 이미 필요한 대부분의 지식을 습득했을 것일 것이기 때문에, 파인 튜닝에서는 더 적은 비용만으로도 특정 작업을 수행하도록 할 수 있다는 아이디어입니다.
|
|
|
그렇다면 어떻게 모델 전체가 아닌 일부만을 효율적으로 훈련할 수 있을까요? 방법은 매우 간단합니다. 딥러닝 모델이 갖는 파라미터 중 일부만을 선택해서 파라미터를 업데이트하면 됩니다. 이전 뉴스레터에서 다루었듯이, 이런 방법에는 초기 레이어 일부를 학습하는 Prefix Tuning, 기존 모델이 갖는 가중치 사이에 특정한 어댑터(Adapter)를 추가하고, 이 어댑터만 학습하는 방법 등이 있습니다. 그중에서도 현재 PEFT에서 가장 널리 쓰이는 방법은 Low Rank Adaptation (LoRA)입니다.
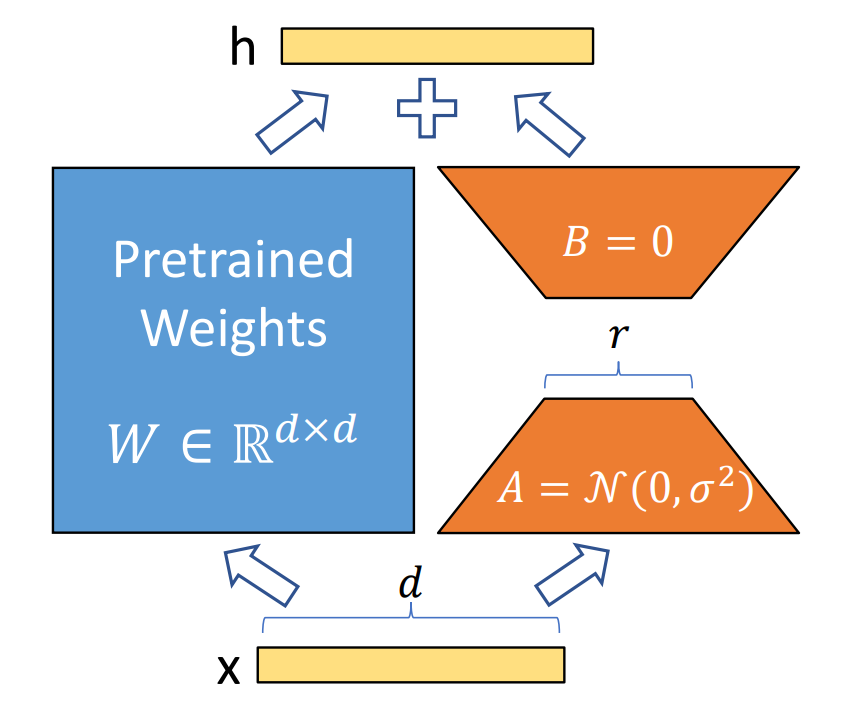
LoRA는 아래와 같이 사전 학습된 가중치 W에 낮은 랭크를 갖는 두 개의 행렬 A와 B를 붙이는 방법입니다. 기존의 파인 튜닝은 W와 같은 차원을 갖는 또 다른 행렬 ΔW를 학습하기 때문에 학습 비용이 매우 큽니다. 반면 LoRA는 ΔW를 낮은 랭크를 갖는 두 개의 행렬로 분해하기 때문에 학습 비용이 크게 줄어드는 것이죠. 그리고 학습이 완료된 후에는 다시 A와 B를 곱해서 W와 같은 차원의 행렬로 만들어 더해주기 때문에 추론 지연(Inference Latency)도 발생하지 않는다는 장점이 있습니다. |
|
|
LoRA의 또 다른 장점은 모델 학습에 필요한 자원을 줄이는 것뿐만 아니라, 학습된 모델을 저장하고 배포하는 데도 용이하다는 것입니다. 왜냐하면, LoRA는 모델이 갖는 기존의 가중치는 전혀 학습하지 않고, 별도로 추가한 LoRA 모듈만을 훈련하고 저장하면 되기 때문입니다. 175B의 크기를 갖는 GPT-3을 기준으로, 기존의 파인 튜닝 방식으로는 모델 가중치를 저장하기 위해서 350GB의 메모리가 필요하지만, LoRA를 적용하면 학습된 파라미터를 저장하는 데 필요한 용량이 35MB밖에 되지 않습니다.
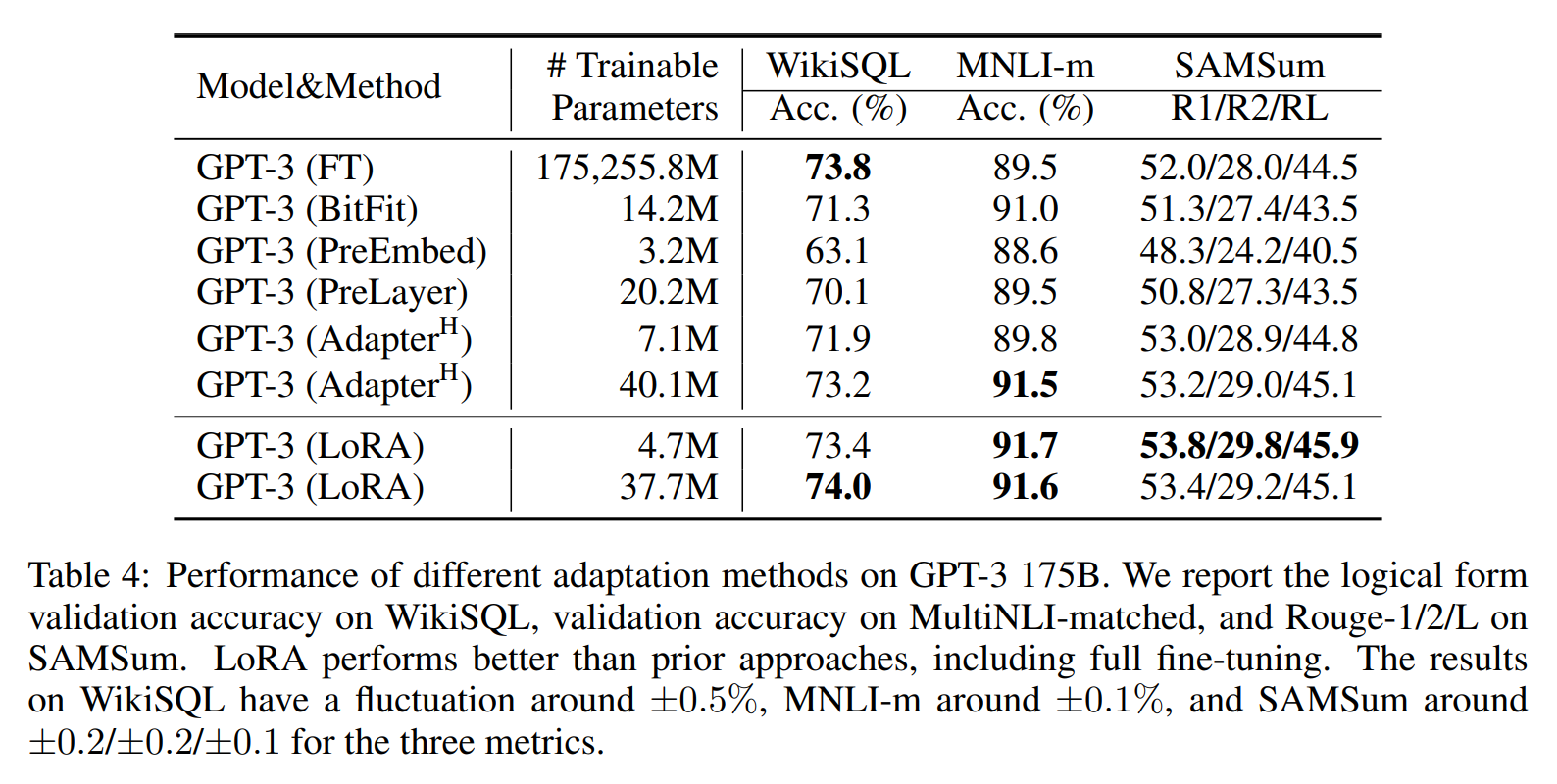
가장 놀라운 점은 학습에 필요한 자원을 크게 줄였음에도 불구하고, 성능도 거의 저하되지 않는다는 점입니다. 논문에서는 다양한 모델에 대한 실험이 수행되었는데, 파인 튜닝(FT) 베이스라인에 비해 LoRA를 적용한 모델의 성능이 거의 떨어지지 않는 것을 볼 수 있습니다. |
|
|
이처럼 LoRA는 개념이 매우 간단하며, 어떤 딥러닝 모델에도 적용될 수 있다는 장점이 있어 2021년 LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021) 논문에서 처음 제안된 후 현재까지도 널리 사용되고 있습니다. 그럼에도 불구하고 LoRA는 이론적인 근거가 충분하지 않다는 단점이 있습니다. 실험적으로 적은 파라미터만을 훈련해도 모델이 특정한 태스크를 수행할 수 있다는 점만 입증했을 뿐, 그 이유는 명확하게 밝히지 않는데요.
이런 점은 단점이 될 수도 있지만, 더 많은 연구를 가능하게 하기도 합니다. 그래서 LoRA가 처음 제안된 이후 이 방법을 응용한 수많은 연구가 수행되었습니다. 이론적인 근거를 덧붙여 LoRA의 한계를 보완하기도 하고, 학습에 필요한 파라미터를 더욱 극단적으로 줄이는 방법도 연구되었죠. |
|
|
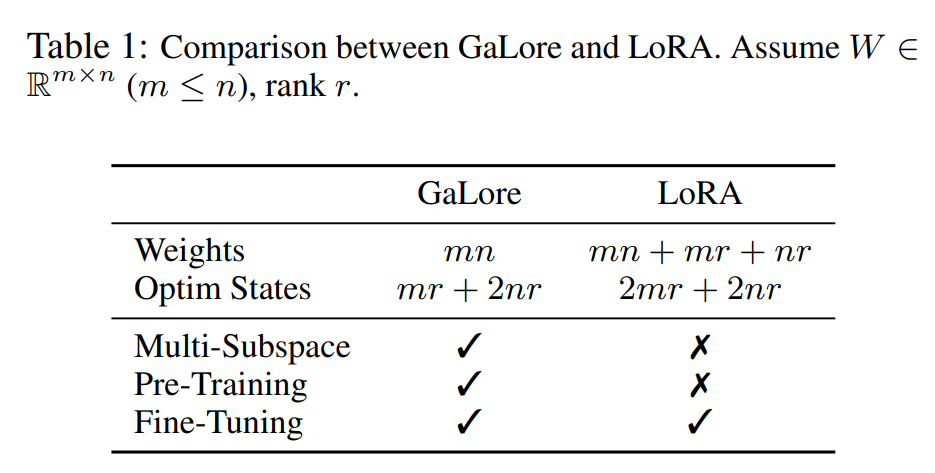
그중 한 가지 눈에 띄는 연구는 올해 3월에 발표된 논문 GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection (Zhao et al., 2024)입니다. GaLore는 LoRA와 다르게 모델의 가중치뿐만 아니라 학습 과정에서 계산되는 그라디언트를 낮은 랭크로 근사한다는 아이디어를 사용합니다.
딥러닝 모델의 학습은 역전파(Backpropagation) 알고리즘을 통해 이뤄지는데, 이 과정에서 각 파라미터에 대한 그라디언트가 계산됩니다. 따라서 학습 과정에서는 모델의 파라미터의 개수만큼의 그라디언트를 저장해야 하고, 이는 모델의 규모와 마찬가지로 학습 비용에 큰 부담을 주는 요인입니다. GaLore는 LoRA가 파라미터가 사용하는 메모리를 효율화한 것 같이, 그라디언트가 사용하는 메모리를 효율화합니다.
|
|
|
|
GaLore는 파인 튜닝뿐만 아니라 사전 학습 단계에서도 사용이 가능하다는 점이 매우 특별한데요, 기존의 PEFT 방법론은 모두 이미 학습된 모델을 추가 학습하는 데만 사용할 수 있었지만, GaLore는 적은 자원을 활용해서 아예 처음부터 모델을 학습할 수 있기 때문입니다. 이처럼 효율적으로 모델을 학습하려는 연구가 계속해서 이뤄지는 덕분에 거대 기업이 아니더라도 LLM을 연구할 수 있게 되었습니다. |
|
|
적은 자원으로 인공지능 모델을 훈련하는 방법에 대한 연구가 활발히 이뤄지는 덕분에 공개된 LLM을 다양한 도메인에 응용할 수 있게 되었습니다. 이런 기술에 힘입어 인공지능 연구가 가속화될 수 있었고, 비로소 우리 생활 곳곳에 파고들 수 있었습니다. PEFT는 아이러니하게도 인공지능 연구 중 가장 이론적인 분야일지 몰라도, 그 영향은 우리와 가장 가까이 맞닿아 있습니다.
모두를 이롭게 해야 할 기술이 거대 기업의 독점적인 소유물이 되어버리지 않도록, 이런 연구는 계속되어야 합니다. 오픈소스가 중요한 만큼, 오픈소스를 활용할 수 있도록 도와주는 기술도 중요한 것이죠. 그리고 오늘 살펴본 연구들이 바로 그런 역할을 한다고 생각합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|