움직이는 부품의 위치와 자세를 시간에 따라 최적화하는 방법인 4D-DPM에 대해서 알아봅시다. # 60 위클리 딥 다이브 | 2024년 10월 9일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 로봇이 움직임을 어떻게 재현하는지 알아봅니다.
- 영상을 보고 제로 샷으로 동작할 수 있는 모델인 RSRD를 살펴봅시다.
- RSRD의 핵심인 4D-DPM에 대해 이해해 봅시다.
|
|
|
🧐 사람의 행동을 보고, 따라할 수 있다고요? |
|
|
안녕하세요, 에디터 잭잭 입니다.
얼마 전 가사도우미 로봇이 판매된다는 뉴스를 보게 되었는데요! 만약 제게도 로봇이 생긴다면, 어떻게 일을 가르칠지 고민을 한 적이 있습니다. 예를 들어, 가위나 선글라스 같은 물체의 조작 방법을 로봇에게 가르친다고 생각해 볼까요? 가장 익숙한 방법은 물체를 집어 들어 로봇에게 보여주고, 직접 손으로 사용하는 방법을 시연하는 것이겠죠. 마치 어린아이들이 어른들을 보고 배우는 것처럼요! |
|
|
누군가의 행동을 따라 하려면, 일단 먼저 관찰 해야해요. 어른이 아이에게 가위의 사용법을 알려준다고 가정해봅시다. 어른의 손은 크고, 아이의 손은 작기 때문에 어른이 손으로 물체를 조작하는 방법과 완전히 동일하게 아이가 따라 하기는 어려워요. 이 때 중요한 것은 손의 움직임이 아니라, 물체에 초점을 두고 행동에 따른 물체의 변화를 관찰하는 것입니다. 만약 물체의 움직임을 인식하고 이해할 수 있다면, 인식된 움직임을 재현하도록 물체를 조작하는 계획을 세울 수 있어요!
이처럼 사람이 물체를 보고 배우는 방법과 유사하게 행동하는 모델을 소개하려고 해요. "로봇이 보고, 로봇이 행동한다" 라는 뜻 처럼, Robot See Robot Do (Kerr, Justin, et al., 2024)를 사용한 로봇은 사람이 물체를 조작하는 영상을 보고 별다른 학습 없이 물체를 조작할 수 있습니다. 즉, 제로 샷으로 수행이 가능하다는 것이 특징이에요. 로봇을 학습시킬 때 사람의 영상을 활용하는 기존 연구들은 추가적으로 로봇을 조작하기 위한 데이터 혹은 좋은 설명이 달린 데이터 셋을 필요로 했었는데요. RSRD는 학습 없이 어떻게 제로 샷으로 이 과정을 수행할 수 있었을까요? |
|
|
객체 중심적으로 촬영한 영상으로부터 물체와 손의 움직임을 감지하는 것을 나타내는 그림
출처: Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction (Kerr, Justin, et al., 2024)
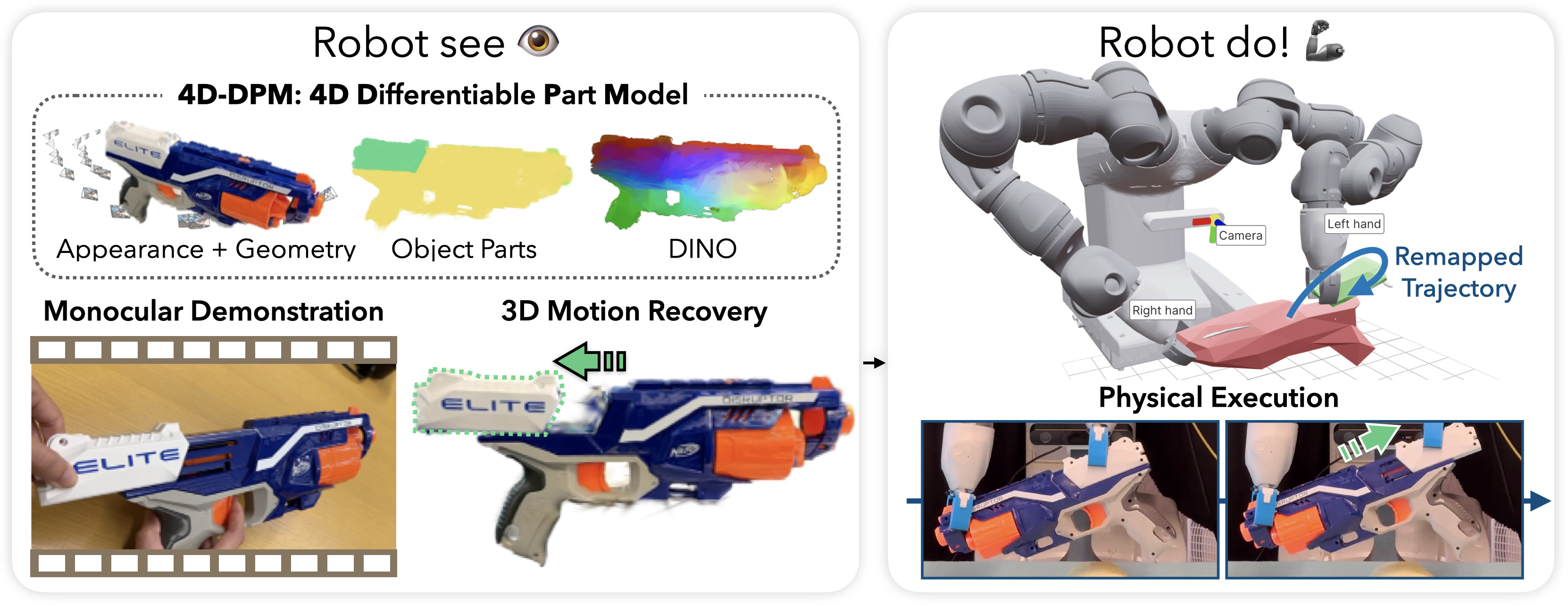
RSRD의 연구진은 객체 중심적으로 접근하였습니다. 여러 각도에서의 물체 사진과 객체 중심적으로 촬영한 사람의 시범 영상만을 필요로 해요. "Robot See Robot Do"라는 모델 이름과 같이, 'See' 단계에서 로봇은 물체의 모델을 렌더링하고, 움직일 수 있는 그룹(ex. 안경다리와 몸통)으로 나누어 움직임 궤적을 3D로 복원해요. 'Do' 단계에서 로봇은 알 수 없는 포즈로 있는 물체를 제공받게 되는데요. 로봇은 앞선 단계에서 얻은 물체의 움직임 궤적을 실제 물체의 포즈로 맞추고, 사람의 시범 영상에서 관찰된 것과 동일하게 움직이기 위해 양 손의 궤적을 계획하는 것이죠. |
|
|
RSRD의 작동 단계
출처: Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction (Kerr, Justin, et al., 2024)
물체의 3D 움직임 궤적을 복원하는 것은 시간과 공간에 걸쳐 물체의 각 부품별로 포즈(위치와 방향)를 추적해야 하기 때문에 쉽지 않은 과정이에요. 이에, 연구진은 움직이는 부품의 위치와 자세를 시간에 따라 최적화하는 방법인 4D-DPM을 제안했습니다.
4D-DPM은 ‘시범 영상’과 ‘여러 각도에서 물체를 촬영한 사진’ 을 입력으로 받습니다. 여러 각도에서 촬영된 물체의 사진들은 Gaussian Splatting (3DGS)을 통해 3D 모델로 변환돼요. 동시에, 같은 사진들을 사용해 GARField를 학습하여, 3D 가우시안을 여러 개의 세부 그룹으로 군집화하고, 물체를 3D 부품으로 분해합니다.
그 다음, 분해된 물체의 부품을 4차원(3D 공간 + 시간)에서 모델링 하여, 각 시간 단계에서 렌더링 된 RGB 이미지, 깊이 맵, 그리고 DINO 특징 맵을 생성합니다. 이 렌더링 된 정보들은 입력 비디오에서 추출된 정보와 비교하여 부품의 움직임을 최적화하는 데 사용됩니다.
이렇게 렌더링 된 3D 물체 부품의 움직임 궤적을 알아내기 위해 '합성에 의한 분석(analysis-by-synthesis)' 접근 방식을 사용하는데요! 즉, 시간에 따라 물체 부품의 모델을 합성하여 물체의 움직임을 이해하고, 4D 부품의 포즈를 시간에 따른 궤적으로 표현하는 것입니다.
이후 로봇은 양 손을 움직이기 위한 배치(deployment) 단계에 접어들게 되는데요. RSRD는 물체의 각 부분을 이동시킬 수 있도록 후보가 되는 손동작을 생성한 다음, 그 중 물체를 움직이기 위한 경로 전체에서 서로 충돌하지 않는 양손의 움직임을 찾아냅니다. 어느 부품을 잡을지 결정하기 위해, 영상에서 손과 물체 부품의 접촉을 인식하고, 해당 부품 쪽으로 로봇의 그립을 부드럽게 바꿉니다.
실제로 해당 모델을 사용한 로봇으로 실험을 해 보았더니, 로봇은 초기 자세 등록에서 94%, 궤적 계획에서 87%, 초기 그립과 움직임 실행은 각각 83%와 85%의 성공률을 달성했다고 합니다. 학습이나 파인 튜닝, 데이터 수집과 주석 작업 없이 달성되었다는 점을 고려했을 때, 좋은 결과를 보여준 것 같아요.
로봇이 어떻게 동작하는지 보고 싶다면, 아래 링크에서 영상을 확인해 보세요! |
|
|
로봇에는 강화학습(reinforcement learning)만 사용된다고 생각했는데, 새로운 방법, 그것도 제로 샷으로 수행하는 방법이어서 흥미롭게 읽은 연구입니다. 더욱 놀라웠던 점은 이 모델이 시뮬레이션이 아닌 실제 세계에서 작동한다는 점인 것 같아요. 특히나 가정에서는 기존의 도구가 다른 도구로 교체되거나 새로운 전자제품이 들어오는 일이 자주 일어나겠죠. 모든 사용법을 데이터 셋을 바탕으로 학습시킬 수는 없기 때문에, 단 한 번의 시연을 통해 사용법을 빨리 익힐 수 있다면! 그것도 가사 로봇의 아주 강력한 능력 중 하나가 될 것 같습니다. 여러분은 가사 로봇의 어떤 능력이 가장 킥이 될 것 같다고 생각하시나요? ㅎㅎ |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|