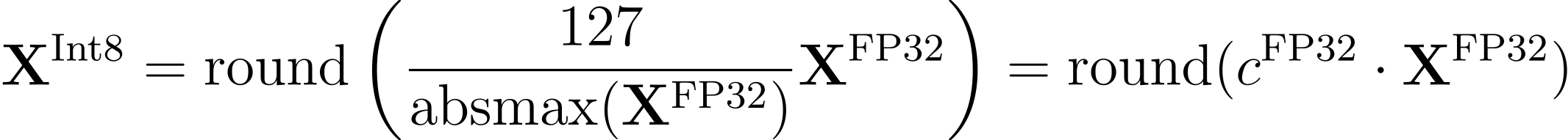인공지능 모델 경량화 기법 중 하나인 양자화(Quantization)에 대해서 알아봅니다. # 59 위클리 딥 다이브 | 2024년 10월 2일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 인공지능 모델의 경량화 방법에는 어떤 것들이 있는지 살펴봅니다.
- 경량화 기법 중 양자화에 대해서 자세히 알아봅니다.
- 양자화의 효과와 연구 의의를 정리합니다.
|
|
|
✏️ 양자화로 성능과 비용, 두 마리 토끼 잡기 |
|
|
안녕하세요, 에디터 민재입니다.
일반적으로 인공지능 모델은 규모가 크면 클수록 더 뛰어난 성능을 보입니다. 인공지능 모델에도 규모의 법칙(Scaling Law)이 존재한다는 것이죠. 그러면 인공지능 모델을 무작정 크게 만들면 모든 문제가 해결될 텐데, 왜 그렇게 하지 않는 걸까요? 어느 시점부터는 규모의 법칙이 성립하지 않기 때문일까요? 물론 그럴 수도 있지만, 더 중요한 이유가 있습니다. 스파이더맨을 통해 널리 알려진 세상의 진리, ‘큰 힘에는 큰 책임이 따른다.’는 인공지능의 시대에도 통용되는 말인데요. 거대한 인공지능을 통해 문제를 푸는 데는 그만한 대가가 요구되기 때문입니다.
그러면 인공지능을 사용하는 데는 어떤 대가를 지불해야 할까요? 마냥 유용한 도구인 줄 알았던 인공지능에 의해 무언가 희생되고 있다니 무섭다는 생각이 들죠. 그런데 그 대가가 곧 우리에게 직접적인 영향을 미칠지도 모릅니다. 2021년 4월 발표된 한 연구에서는 175B 규모의 GPT-3를 훈련하는 데 550톤이 넘는 이산화탄소가 배출된다고 했습니다. 이는 한 사람이 뉴욕과 샌프란시스코를 550회 왕복 비행하는 데 필요한 것과 같은 양입니다. 환경 문제 외에도 인공지능 연구는 다양한 우려를 낳고 있습니다.
자연스럽게 지속 가능한 인공지능 연구의 필요성이 대두되었고, 그런 상황에서 새롭게 부상한 분야가 바로 인공지능 경량화입니다. 그중에서도 특히 최근 많은 연구가 이루어지고 있는 분야는 양자화입니다. 인공지능 연구 트렌드를 잘 몰라도 왠지 익숙한 이름이죠. 아마 양자역학이 떠올랐을지도 모르겠는데요, 실제로 양자역학의 양자와 인공지능 양자화의 양자는 비슷한 개념을 바탕으로 합니다. 벌써 어렵다는 생각이 들 수도 있지만, 차근차근 그 개념을 알아보겠습니다. |
|
|
본격적으로 양자화를 알아보기 전, 경량화가 무엇인지 가볍게 살펴보겠습니다. 인공지능 경량화란 규모가 큰 딥러닝 모델의 성능을 유지하면서도 그 크기와 연산 자원을 줄이는 기술입니다. 주요 기법으로는 양자화(Quantization), 가중치 가지치기(Pruning), 지식 증류(Knowledge Distillation) 등이 있습니다. 여기서 중요한 건 기존 모델의 성능을 유지한다는 점입니다. 그런데 규모의 법칙을 따르는 인공지능 모델이 어떻게 그 크기를 줄여도 성능을 유지할 수 있을까요? |
|
|
💡 가지치기와 지식 증류
가지치기는 딥러닝 모델에서 중요하지 않은 가중치(파라미터)를 제거하며 모델 크기를 줄이는 방법입니다. 학습 중 값이 거의 변하지 않거나, 추론 시 영향이 적은 파라미터를 선택적으로 제거합니다.
지식 증류는 규모가 큰 교사(Teacher) 모델이 그보다 작은 학생(Student) 모델에게 지식을 전달하는 방법입니다. 교사 모델이 예측에 사용하는 확률 분포를 학생 모델이 학습하도록 해서, 크기가 작은 모델도 큰 모델과 유사한 성능을 낼 수 있게 합니다.
|
|
|
정답은 내재적 차원(Intrinsic Dimensionality)이라는 개념에 있습니다. 내재적 차원은 데이터나 모델이 실제로 의미 있게 사용하고 있는 차원을 말하는데요, 조금 더 쉽게 다시 이해해 보죠. 2018년 발표된 논문에서 제안한 로터리 티켓 가설(Lottery Ticket Hypothesis)은 딥러닝 모델이 필요 이상으로 많은 매개변수를 사용하고 있다고 주장합니다. 그래서 실제로는 훨씬 더 적은 매개변수를 갖는 작은 모델로도 거대한 모델과 비슷한 성능을 낼 수 있다는 것입니다. 이는 인공지능 경량화가 가능한 이유를 설명하는 중요한 논리입니다. |
|
|
그러면 양자화는 어떤 방법으로 인공지능 경량화를 수행할까요? 인공지능 분야에서 양자화는 더 많은 정보로 표현되는 데이터를 더 적은 정보로 표현하는 이산화(Discretize) 과정을 의미합니다. 과학에서도 연속적인 값을 이산적인 값으로 표현하는 과정을 양자화라고 하는데, 양자역학과 양자화 사이에 어떤 관련이 있는지 드디어 알았네요.
인공지능 양자화의 대표적인 예시는 32개의 비트로 표현되는 모델 파라미터를 8개의 비트로 표현하는 8-bit Int 양자화가 있습니다. 인공지능 모델의 각 파라미터는 어떤 정보를 담고 있는데, 여기서는 파라미터가 이 정보를 32개의 이진수 공간에 저장하고 있는 것이죠. 8-bit Int 양자화는 같은 정보를 8개의 비트만을 사용해서 표현하는 것을 목표로 합니다. 사실 양자화는 직접적으로 인공지능 모델의 파라미터 개수 자체를 줄이진 않습니다. 경량화의 목표가 필요 이상으로 많은 파라미터의 개수를 줄이는 것인데, 그 대신 양자화의 목표는 필요 이상으로 큰 저장 공간을 절약하는 것입니다.
문제는 어떻게 32개의 비트가 표현하는 정보를 최대한 유지하면서 8개의 비트만으로 표현할 수 있는가입니다. 일단 기존에 데이터를 저장하는 공간이 필요 이상으로 컸다면, 압축된 공간은 효율적으로 활용돼야겠죠. 그렇게 하기 위해서는 원본 데이터가 양자화된 데이터가 표현하는 공간을 전부 사용할 수 있게 해주어야 하는데, 이를 수식으로 표현하면 다음과 같습니다. |
|
|
FP32 데이터 타입을 Int8 데이터 타입으로 양자화하는 방법을 표현한 수식
출처: QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., 2023)
복잡한 수식은 한 번에 와닿지 않으니, 예시를 보면서 양자화가 어떻게 이뤄지는지 살펴보겠습니다. 원본 데이터가 [-3.1, 0.1]의 두 개의 실수형(Floating Point) 숫자로 이루어진 배열이라고 하겠습니다. 가장 먼저 원본 데이터를 구성하는 각 요소 중 절댓값이 가장 큰 값(Absolute Maximum, absmax)을 찾습니다. 여기서는 절댓값이 가장 큰 값이 -3.1이니까, absmax는 3.1이 되겠네요. 원본 데이터의 각 요소를 이 값으로 나눠주면 모든 값은 1 이하가 되어 [-1.0, 0.0323]이 됩니다.
이렇게 얻은 값들을 양자화된 데이터가 표현할 수 있는 범위의 가장 큰 값과 곱해줍니다. 8 비트는 256개의 숫자를 표현할 수 있고, 그 표현 범위는 -128 ~ 127이므로, 앞서 얻은 결과에 127을 곱해주면 되겠네요. 그리고 마지막으로 반올림을 해주면 양자화가 끝납니다. 실제로 계산해 보면, 먼저 127을 곱해서 [-127.0, 4.1021]을 얻고, 이 값을 반올림하면 최종적으로 [-127, 4]가 됩니다. 양자화를 오랜 기간 연구한 Tim Dettmers는 양자화는 일종의 매핑(Mapping)이라고 설명합니다. 양자화가 마치 원본 데이터와 양자화 데이터의 관계를 정의한 표를 보고 양자화된 결괏값을 찾는 것과 비슷하기 때문이죠. |
|
|
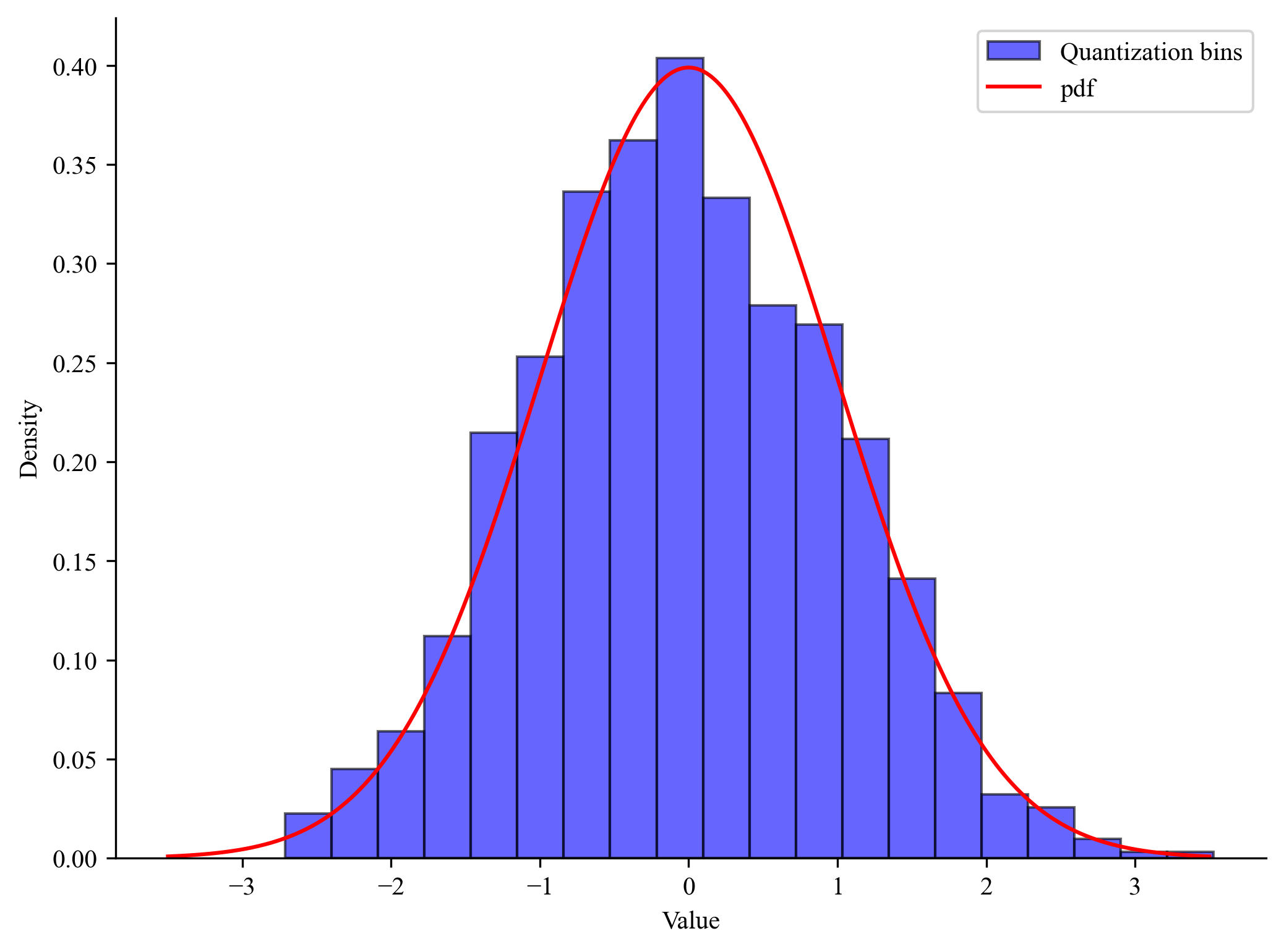
이렇게 쉽게 양자화가 가능하다면 정말 좋겠지만, 안타깝게도 양자화에는 치명적인 한계가 존재합니다. 원본 데이터에 존재하는 특잇값(Outlier) 때문에 양자화 성능이 크게 저하될 수 있다는 문제입니다. 앞서 양자화는 연속적인 값을 이산적인 값으로 표현하는 것이라고 했습니다. 이를 시각화하면 아래 그림과 같은데요, 여기서 각 막대가 표현하는 범위를 양자화 구간(Quantization Bin)이라고 합니다. |
|
|
출처 : © deep daiv.
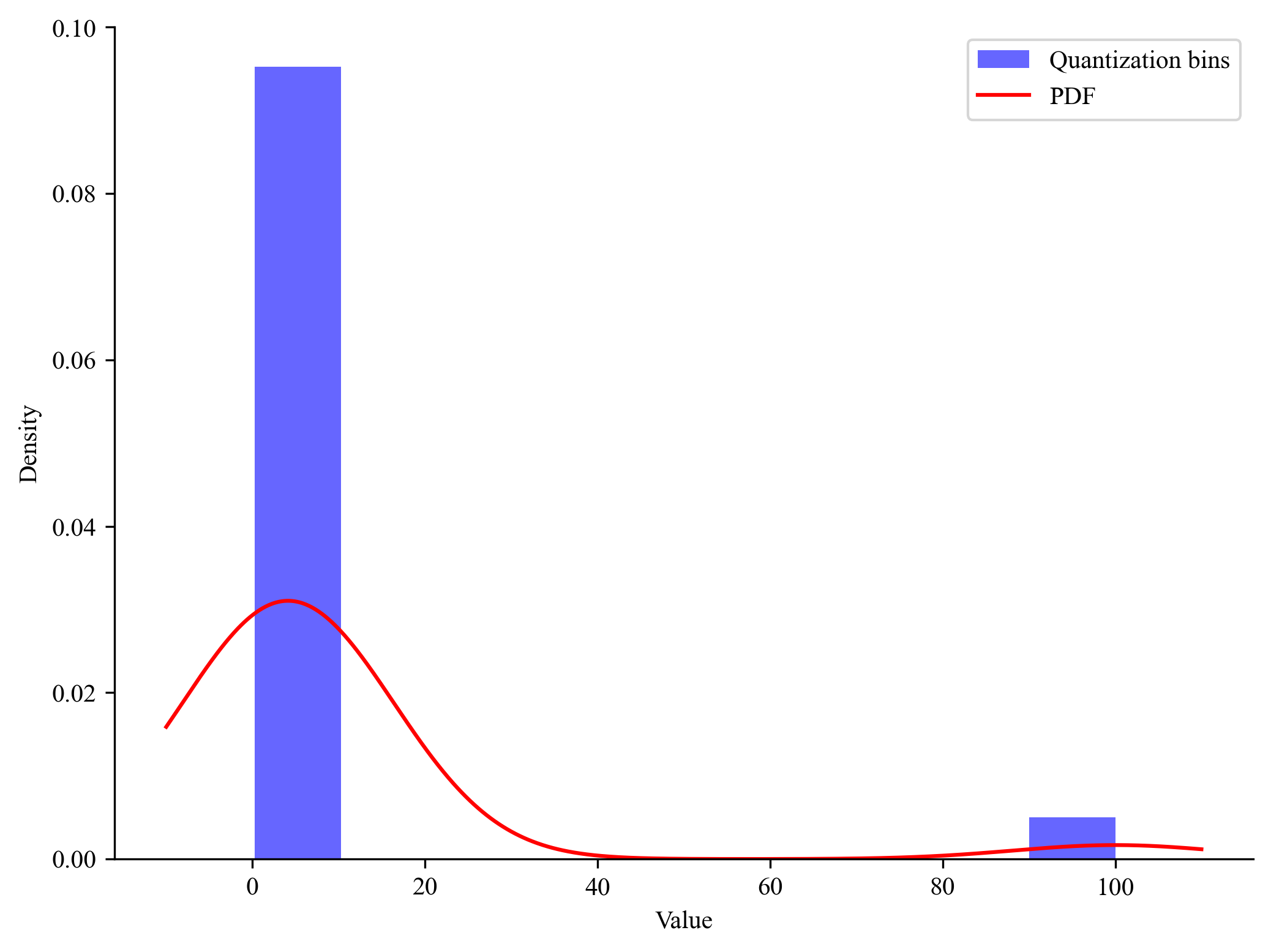
원본 데이터가 위 그림처럼 여러 구간에 넓게 퍼져 있으면 좋겠지만, 만약 아래 그림처럼 일부만 동떨어져 있다면 어떨까요? 이렇게 되면 특정 구간에 대부분의 값이 포함되는 문제가 발생하고, 더 큰 문제는 아무런 데이터도 포함하지 않는 구간이 생성되는 것입니다. 이는 양자화, 즉 매핑을 비효율적으로 만들게 됩니다. |
|
|
출처 : © deep daiv.
이런 문제를 해결하기 위해서 Tim Dettmers는 8-bit Optimizers via Block-wise Quantization이라는 논문에서 블록 단위 양자화(Block-wise Quantization)을 제안했습니다. 모든 데이터를 한꺼번에 양자화하는 대신, 여러 개의 조각으로 나눈 후 양자화를 수행하는 아이디어입니다. 이 방법을 사용하면 특잇값에 의해 발생하는 정보 손실을 줄일 수 있게 됩니다. |
|
|
이제 양자화가 어떻게 이루어지는지 이론적인 개념은 알겠습니다. 그러면 실제로 인공지능을 사용할 때 양자화는 어떤 이점을 가져다줄까요? 아마 인공지능 모델이 작업을 처리할 때는 CPU가 아닌 GPU를 사용한다는 사실을 알고 계실 겁니다. 개인용 컴퓨터에서 사용할 수 있는 가장 좋은 GPU는 24GB의 메모리 용량을 갖는데, 이는 7B 규모의 대규모 언어 모델(Large Language Model, LLM)을 불러오기에도 부족합니다.
그런데 블록 단위 양자화를 제안한 Tim Dettmers의 또 다른 연구, QLoRA: Efficient Finetuning of Quantized LLMs에서는 FP32 데이터 타입을 갖는 모델을 NF4 데이터 타입으로 양자화하면 무려 30B 규모의 LLM을 파인튜닝할 수 있다고 합니다. 즉, 원래 파라미터당 32 비트의 공간을 사용하던 모델이 파라미터당 4 비트의 공간만을 사용하도록 압축했더니, 7B 규모의 LLM을 불러오는 것조차 어려웠던 GPU에서 그보다 네 배나 큰 규모의 LLM을 훈련할 수 있게 되었다는 것입니다. 물론 이 논문에서 LLM 학습을 위해 다른 여러 기법을 함께 사용하긴 했지만, 그래도 양자화의 힘을 엿볼 수 있는 대목입니다. |
|
|
인공지능 모델 양자화, 나아가 경량화 연구의 발전 덕분에 더 많은 사람들이 저렴한 비용으로 고성능의 모델을 쉽게 사용할 수 있게 됐습니다. 이런 기술에 힘입어 인공지능 연구가 한층 가속화되었고, 비로소 인공지능이 우리 생활 곳곳에 파고들 수 있었습니다. 인공지능 경량화는 겉으로 보기에는 매우 이론적인 분야처럼 보이지만, 그 영향은 우리와 가장 가까이에 있습니다.
인공지능 경량화는 인공지능 연구 대중화에 기여한다는 점에서 매우 중요합니다. 인공지능 연구가 대중화되면, 훌륭한 사람들이 더 많이 이 분야에 뛰어들어 새로운 아이디어를 활발히 제안하고, 인공지능 연구가 더욱 빠르게 바람직한 방향으로 발전할 수 있습니다. 모두를 이롭게 해야 하는 인공지능이 누군가의 독점적 소유물이 되어버리면, 인공지능의 시대에 사는 우리도 곧 그들에게 종속될 수밖에 없습니다. 오픈소스는 기술의 민주화를 달성하는 데 핵심적인 역할을 합니다. 그에 못지않게 중요한 것이 오픈소스를 활용할 수 있도록 하는 도와주는 기술입니다. 오늘 살펴본 연구들이 바로 그런 역할을 하고 있지 않을까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|