차세대 인공지능 비서의 주요 과업인 VideoQA에 대해 알아봅시다. # 57 위클리 딥 다이브 | 2024년 9월 18일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 인공지능 비서의 주요 과업인 VideoQA에 대해소개합니다.
- 자아중심 비디오 데이터셋에서 우수한 성능을 보인 VideoLLaMB에 대해 살펴봅시다.
- 비디오의 장기 의존성 문제(Long-dependency)를 해결하는 방법에 대해 알아봅시다.
|
|
|
📹 Video Question-Answering |
|
|
안녕하세요, 에디터 잭잭입니다.
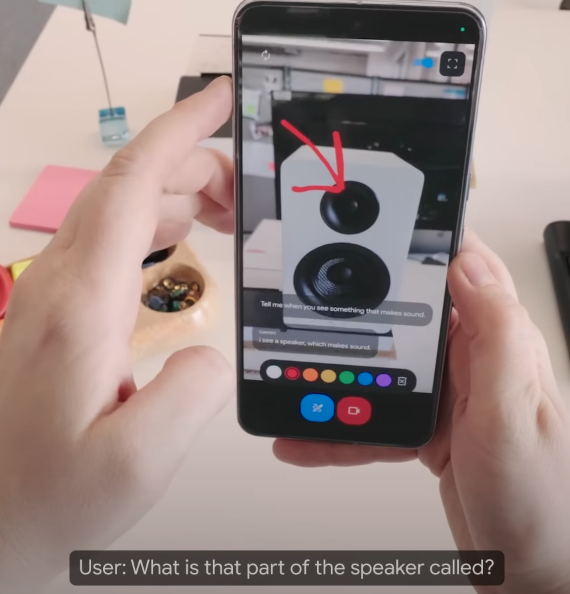
최근 몇 주 동안 LLM을 주제로 한 뉴스레터를 다뤘는데요, 오늘은 새롭게 MLLM(Multimodal Large Language Model)에 대해서 다뤄보려고 합니다. 그중에서도 차세대 인공지능 비서의 주요 과업으로 꼽히고 있는 VideoQA에 대해 얘기해보려고 해요. |
|
|
그렇다면 VideoLLaMB가 어떻게 구성되어 있는지 알아볼까요? |
|
|
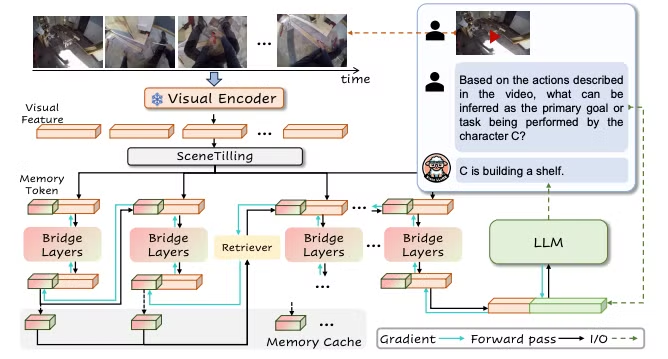
VideoLLaMB의 프레임워크
출처 : <VideoLLaMB: Long-context Video Understanding with Recurrent Memory Bridges> (Wang et al., 2024)
그림의 오른쪽과 같이 사용자가 비디오에 대한 질문을 하면, VideoLLaMB 프레임워크는 다섯 단계를 거쳐 답변을 생성합니다.
- 사전 학습된 Visual Encoder를 사용하여 비디오의 특징을 추출합니다.
- SceneTilling을 적용하여 비디오를 의미를 단위로 한 세그먼트로 분할합니다.
- 세그먼트에 대해 순환 메모리(Recurrent Memory)를 사용하여 비디오 정보를 메모리 토큰에 저장합니다
- 다음으로, 검색 메커니즘(Retrieval Mechanism)을 활용해 메모리 토큰을 업데이트하고 장기 의존성(Long-dependency) 문제를 해결합니다.
- 마지막으로, 현재 비디오 세그먼트에서 메모리 토큰으로 보강된 특징(Memory-token-augmented Features)을 대규모 언어 모델(LLM)에 투영하여 응답을 생성합니다.
이와 같이 비디오의 시각적 정보와 텍스트 언어 데이터를 결합하여 비디오의 의미를 이해하고 관련 작업을 수행하는데요. 비디오 프레임의 시각적 특징을 추출하는 비주얼 백본(Visual Backbone), 비디오 분할 및 샘플링, 비디오의 시각적 특징과 언어적 특징을 통합하여 의미를 연결하는 멀티모달 통합, 긴 비디오나 복잡한 문맥에서 중요한 정보를 장기적으로 저장하고 관리하는 메모리 모듈, 그리고 언어 모델이 VideoQA 작업의 대표적인 구성 요소입니다. |
|
|
🧐 Recurrent Memory Bridge Layer |
|
|
앞서 말했던 것처럼, 높은 연산 비용과 데이터셋 부족 문제를 해결하기 위해 연구 커뮤니티는 연산 효율이 높은 멀티모달 대규모 언어 모델(MLLM)의 개발에 점점 더 관심을 보이고 있어요. 전통적인 방법으로는 비디오의 길이를 줄이기 위해 샘플링과 같은 비디오 압축 전략을 사용하거나, 슬라이딩 윈도우 메커니즘을 사용하여 비디오를 짧은 클립으로 분할하는 방법 등이 있습니다. 그러나 이러한 방법들은 중요한 시각적 단서를 잃어버리기 쉬워, 모델이 본질적인 정보를 포착하는 능력을 저하시킬 수 있어요.
이를 해결하기 위해 VideoLLaMB에서는 SceneTilling을 사용하여 비디오를 독립적인 의미 단위인 세그먼트로 분할해 각 의미 단위 내에서 차원을 줄이고, 의미적인 특징을 희생하지 않도록 했습니다. 그리고 분할된 세그먼트에 기반하여 '순환 메모리 브리지 레이어(Recurrent Memory Bridge Layer)'라는 새로운 메커니즘 또한 제안했는데요. 이 레이어는 여러 층으로 구성된 Transformer 블록으로 구현되며, 브리지 레이어 내에서 순환 메모리 토큰을 통합하여 기억 능력을 향상시킵니다.
|
|
|
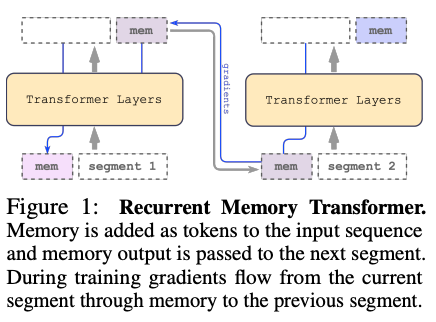
순환 메모리 트랜스포머 토큰의 구조
출처 : <Recurrent memory transformer> (Bulatov et.al, 2022)
순환 메모리 토큰(Recurrent Memory Transformer)이란, 이전 세그먼트의 정보를 저장하고, 이를 다음 세그먼트 처리에 반복적으로 활용하는 메커니즘을 의미합니다. 이를 통해 모델이 긴 비디오에서 일관된 정보를 유지하고, 장기적인 문맥을 이해할 수 있습니다.
순환 메모리 브리지 레이어는 비디오의 각 세그먼트를 처리할 때, 해당 세그먼트에서 중요한 정보를 메모리 토큰에 저장합니다. 비디오의 다음 세그먼트를 분석할 때, 이전에 저장된 메모리를 활용하여 새로운 세그먼트의 정보를 이해할 수 있어요. 그러면서, 새로운 정보를 반영해 메모리를 업데이트합니다. 이 계층은 각 비디오 세그먼트 사이에서 정보를 연결하고, 기억을 유지하면서 더 나은 예측이나 이해를 할 수 있게 돕는 다리 역할을 합니다. 특히 비디오의 앞부분에서 나온 정보가 뒤에서 중요한 경우, 이를 기억할 수 있도록 함으로써 시각적 정보의 손실을 최소화 하고 긴 비디오의 장기의존성 문제를 해결합니다. |
|
|
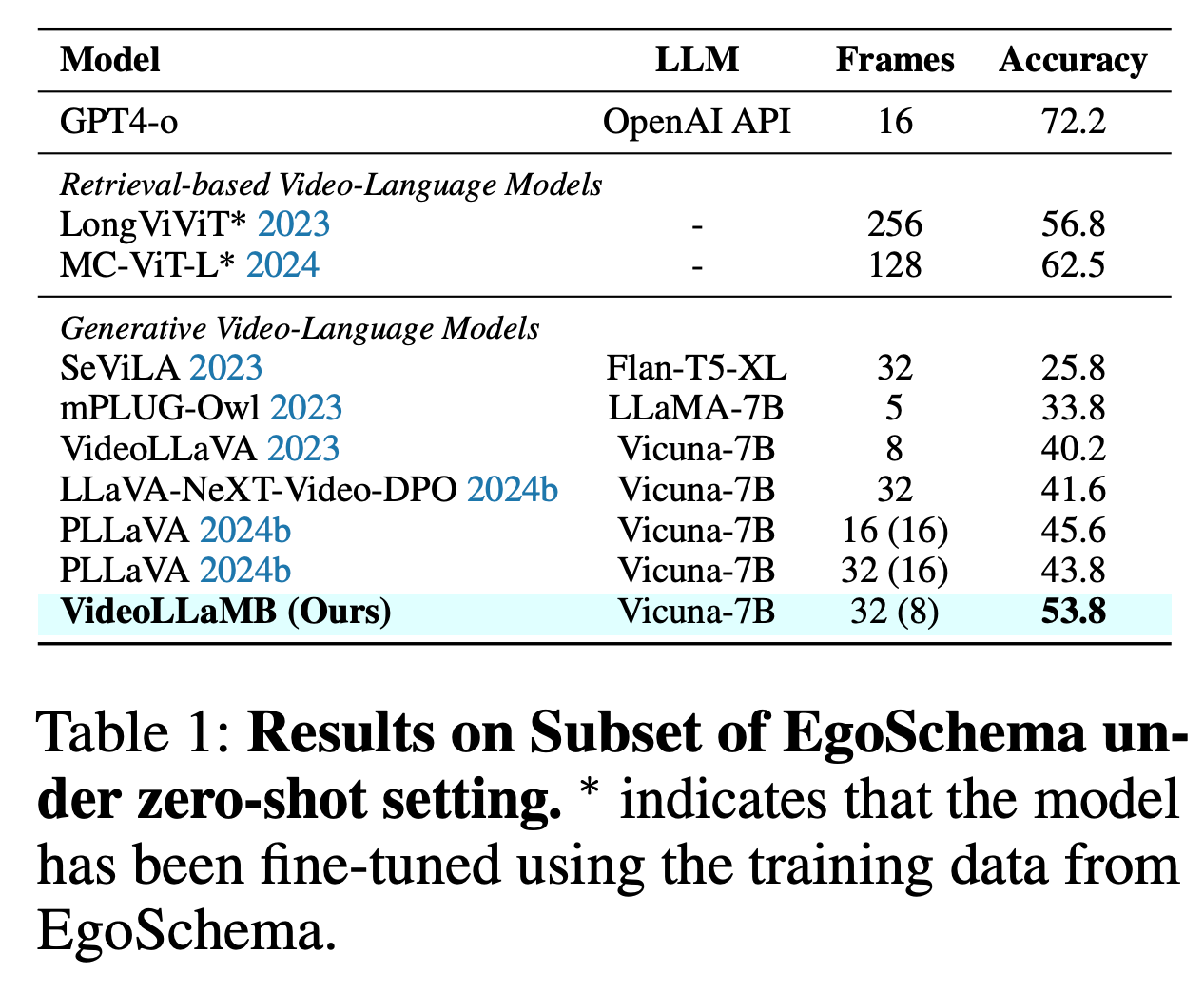
실험에 따르면, VideoLLaMB 모델은 VideoQA 작업의 벤치마크 데이터셋인 EgoSchema에서 가장 높은 성능을 달성했습니다. EgoSchema는 자아중심 비디오(Egocentric Video)를 활용한 VideoQA 작업을 목표로 하는 벤치마크 데이터셋입니다. 이 데이터셋은 상황과 장면에 대해 질문을 던지고, 모델이 이를 이해하고 답변하는 능력을 평가해요. 동일한 훈련 데이터, LLM 백본, 프레임 수를 사용하는 PLLaVA (Xu et al., 2024b)와 비교했을 때, PLLaVA보다 상당한 성능 향상을 보여주었으며, 긴 비디오를 이해하는 능력에서 우수성을 입증했어요. |
|
|
🤔 자아중심 비디오(Egocentric Video)
1인칭 시점으로 촬영된 비디오로, 촬영자가 직접 카메라를 착용하고 주변 환경을 기록한 영상을 말합니다. 이 비디오의 목적은 촬영자가 보는 시각 그대로의 시점을 기록하는 것으로, 일상 생활에서 발생하는 사건을 현실적으로 반영합니다. |
|
|
이제 인공지능에게 요구하는 능력이 점점 사람에게 요구하는 능력과 비슷해져 가고 있는 것 같습니다. 언어나 사진을 이해하는 것뿐만 아니라, 실시간 영상을 이해하고 의미 단위로 추출하여 사용자가 원하는 답변을 내놓기까지 하네요. 실시간 영상 대화를 통해 사람과 인공지능간의 상호작용이 더욱 강화되었고, 인공지능이 일상생활에 더 가까이 녹아드는게 실감나는 것 같아요!
어느새 가을, 추석이 찾아왔습니다. 가을 햇살처럼 풍요롭고 여유로운 마음으로 감사하는 일이 많은 날들이었으면 좋겠습니다. 즐거운 연휴 되시길 바랍니다🌕 |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|