LLM 내부에 존재하는 안전 계층(Safety Layers)에 대해서 알아봅니다. # 56 위클리 딥 다이브 | 2024년 9월 11일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- LLM의 정렬(Alignment)에 관한 개념을 정리합니다.
- LLM 내부에 존재하는 안전 계층(Safety Layer)을 찾는 방법을 알아봅니다.
- LLM 파인튜닝 과정에서 안전성과 성능을 모두 확보하는 방법인 SPPFT를 소개합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
인공지능의 성능이 급격히 좋아지면서, 이제는 인간의 수준에 필적한다는 과분한 칭호까지 사용되고 있습니다. 특히 대규모 언어 모델(Large Language Model, LLM)은 놀라울 정도의 언어 이해와 생성 능력을 보이며, 그동안 사람이 해왔던 여러 작업을 대신 처리해 주기도 합니다. 인공지능은 단순한 업무 자동화 도구를 넘어선 무언가가 되고 있습니다. 애초에 인간이 창조한 도구 중에서 인간 수준에 준한다는 평가를 받으며, 인간과 경쟁하는 무언가가 존재하긴 했을까요?
인공지능이 인간과 경쟁한다고 생각하니 왠지 섬뜩하기도 합니다. 실제로 인공지능의 급격한 발전을 우려한 사람들은 무분별한 연구를 잠깐 중단하고, 우리 사회가 새로운 변화를 받아들일 준비를 먼저 해야 한다는 공개서한을 발표하기도 했습니다. 사실 GPT-3를 필두로 LLM의 시대가 시작되었을 때부터, 이러한 미래는 예견되어 있었습니다. LLM이 배운 적도 없는 새로운 작업을 수행하는 창발적인 능력(Emergent Ability)을 갖추게 되자, 남용을 우려한 여러 기업과 연구소들은 LLM을 더 이상 공개하지 않기로 했습니다.
LLM은 위험할 수 있지만, 잘 통제할 수만 있다면 분명히 강력한 도구입니다. 그래서 연구자들은 LLM을 통제할 방법을 찾기 위해 꾸준히 노력하고 있습니다. 그 결과로 인간의 피드백을 바탕으로 응답을 생성하는 방법을 학습하는 RLHF, 인간의 선호도를 학습하는 DPO를 비롯한 여러 방법이 제안되었습니다. 하지만 이런 방법들이 어떻게 LLM과 인간의 가치를 정렬하고, LLM이 안전한 응답을 생성하도록 보장하는지에 대한 원리는 여전히 명확하지 않습니다.
그런데 최근 중국과학기술대학과 알리바바 그룹이 발표한 논문, Safety Layers of Aligned Large Language Models: The Key to LLM Security(Li et al., 2024)에서 LLM 내부에 안전을 책임지는 부분이 존재한다는 사실이 밝혀졌습니다. 연구에 따르면 LLM에는 악의적인 질문을 식별하고 응답을 거부하는 데 관여하는 안전 계층(Safety Layer)이 존재하며, 이는 여러 LLM에 공통적으로 발견된다고 합니다. 그렇다면 이 안전 계층은 정확히 무엇이고, 어떻게 작동하는 것일까요? |
|
|
💡 정렬(Alignment)이란?
LLM은 본질적으로 어떤 문장이 주어질 때, 확률을 기반으로 다음에 이어질 단어를 예측하는 기계일 뿐입니다. 따라서 사전 학습된 LLM의 출력은 사용자의 의도, 나아가는 인간의 가치와 잘 맞지 않을 수 있습니다. 그래서 LLM의 출력이 인간의 의도와 가치를 반영하도록 조정하는 과정을 정렬(Alignment)이라고 합니다.
LLM Alignment에는 다양한 방법이 존재합니다. 대표적으로는 OpenAI가 ChatGPT를 만들 때 사용한 방법인 RLHF(Reinforcement Learning from Human Feedback)가 있습니다. RLHF는 이름에서도 알 수 있듯이, 인간의 피드백을 바탕으로 강화 학습을 수행하여 인간의 가치를 LLM에 주입하는 방법입니다.
정렬은 단순히 LLM이 사용자의 의도를 잘 이해하도록 하기 위한 것만은 아닙니다. 유해한 답변을 생성하지 않게 하고, 잠재적인 위협을 초래할 수 있는 질문에 응답을 거부하는 등, 정렬은 LLM이 신뢰할 수 있고 안전한 도구가 되도록 하는 데 필수적인 과정입니다.
|
|
|
그런데 연구자들은 왜 LLM 내부 어딘가에 안전을 담당하는 요소가 존재할 것이라고 생각했을까요? 해답은 프롬프트에 있습니다. 사용하는 입장에서는 알 수 없지만, 우리가 LLM에 입력하는 질문은 보통 아래와 같은 형태로 들어갑니다. 이처럼 사용자의 질문은 어떤 형식에 맞게 변형이 되어 입력되는데, 여기서 이 형식을 프롬프트 템플릿이라고 합니다. 그리고 아래처럼 사용자와 LLM이 대화를 띄는 형식을 특별히 대화 템플릿(Dialogue Template)이라고 합니다. 사용자가 입력한 질문은 아래 템플릿의 {The input instruction} 부분을 대체하게 되는 것이죠. |
|
|
LLM에 입력되는 대화 프롬프트 템플릿
출처 : Safety Layers of Aligned Large Language Models: The Key to LLM Security (Li et al., 2024)
주목할 점은, 들어오는 질문과 관계없이 프롬프트의 마지막 부분은 항상 똑같다는 점입니다. 모두 ‘### Response :’로 끝나죠. 그런데 LLM이 다음에 생성할 토큰은 LLM의 마지막 레이어에서 가장 끝에 위치한 출력 벡터에 의해 결정됩니다. 여기서 한 가지 의문이 발생합니다. 앞서 이야기한 내용에 의하면, 악의적인 질문이든 평범한 질문이든 프롬프트의 마지막 부분은 항상 똑같은데, 어떻게 LLM이 이 둘을 구분하고 다른 응답을 생성할까요? 최초의 입력은 LLM의 은닉 레이어(Hidden Layer)에서 어떤 과정을 거쳐 서로 다른 방향으로 나아가는 것일까요? |
|
|
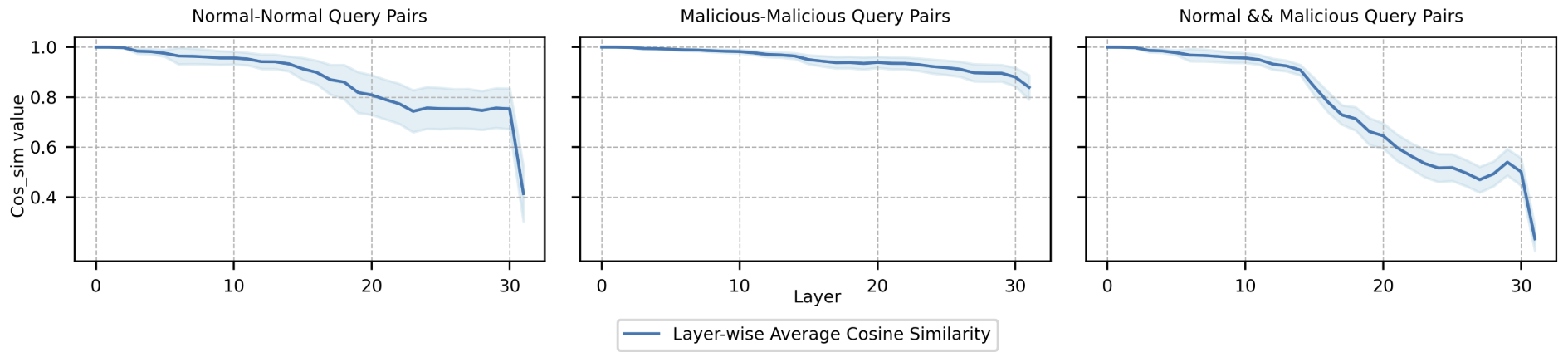
질문의 답을 찾기 위해 연구진은 먼저 일반적인 질문으로 구성된 데이터셋 N과 악의적인 질문으로 구성된 데이터셋 M을 준비했습니다. 그리고 LLM의 각 레이어에서 각각의 질문에 대한 출력 벡터를 추출했습니다. 즉, LLM 내부에 K개의 레이어가 존재한다면 하나의 질문에 대해서 K개의 출력 벡터를 얻은 셈입니다. 그리고 각각의 질문에 대해 이렇게 얻은 출력 벡터 간의 코사인 유사도(Cosine Similarity)를 계산했습니다. |
|
|
LLM의 각 레이어에서 얻은 출력 벡터를 바탕으로 일반적인 질문(Normal Query)와 악의적인 질문(Malicious Query)의 유사도를 비교한 결과
출처 : Safety Layers of Aligned Large Language Models: The Key to LLM Security (Li et al., 2024)
흥미로운 점은 서로 다른 두 개의 일반적인 질문에 해당하는 N-N Pair와 일반적인 질문과 악의적인 질문을 비교하는 N-M Pair는 유사도가 점점 낮아지지만, 악의적인 질문 쌍에 해당하는 M-M Pair의 유사도는 거의 달라지지 않는다는 것입니다. 즉, LLM의 특정 레이어가 입력이 악의적인지를 판단하면, 그 결과에 따라 응답을 거부할지, 아니면 답변을 이어서 생성할지를 결정합니다. 일반적인 질문은 각각의 의도에 맞는 응답을 생성하기 때문에 유사도가 낮아지지만, 악의적인 질문의 경우 일관되게 응답을 거부하기 때문에 유사도가 거의 변하지 않는 것입니다. |
|
|
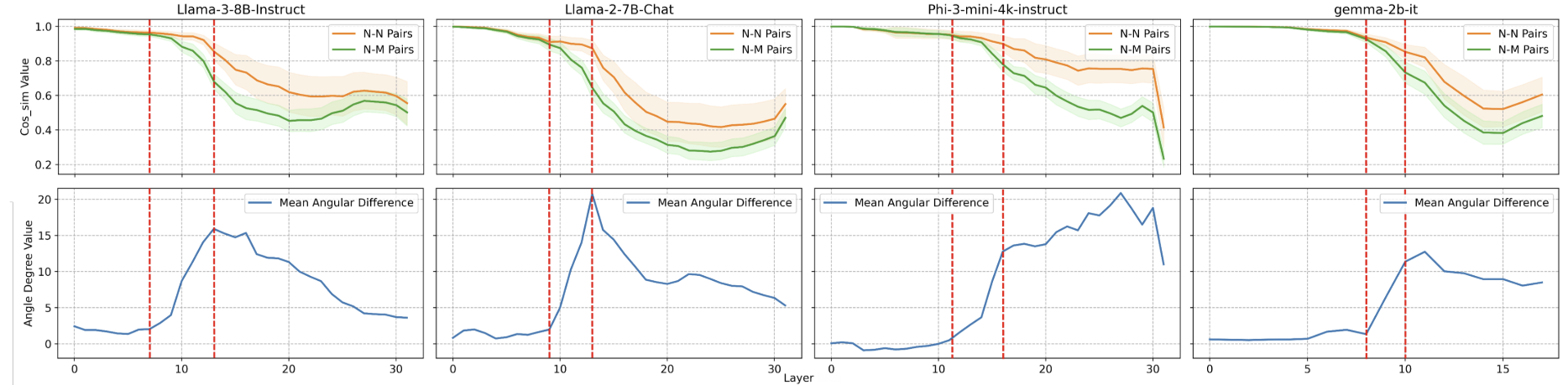
다양한 LLM의 각 레이어에서 질문 유형에 따른 유사도를 비교한 결과. 모델에 관계없이 일정한 패턴을 보인다.
출처 : Safety Layers of Aligned Large Language Models: The Key to LLM Security (Li et al., 2024)
다양한 LLM을 사용하여 실험을 반복한 결과, 거의 동일한 위치에서 이런 현상이 발생하는 것을 확인할 수 있었습니다. 안전 계층은 LLM의 종류와 관계없이 모두 비슷한 곳에 존재하는 것이었죠. 연구진은 안전 계층의 존재를 증명하기 위해 또 다른 실험도 수행했습니다. 정렬되지 않은 모델에서 얻은 출력 벡터의 코사인 유사도를 비교한 결과, 질문이 악의적인지 여부와 관계없이 유사도가 비슷한 추세로 변화하였습니다. 즉, 정렬이 이뤄지지 않은 모델 내부에는 질문이 악의적인지를 판단하는 장치가 존재하지 않는다는 것이죠. |
|
|
LLM의 신뢰성과 안전성을 확보하기 위해 정렬은 필수적이지만, 한 가지 문제가 존재합니다. 일반적으로 정렬 과정에서 LLM의 성능이 떨어지기 때문입니다. 사실 그럴 수밖에 없는 게, 잠재적인 문제를 야기할 수 있는 질문에 대한 응답을 거부하다 보면, LLM이 제공하는 정보가 제한될 수밖에 없습니다. 이처럼 정렬 과정에서 LLM의 성능이 저하되는 현상을 정렬 비용(Alignment Tax)이라고 하는데요. 연구진은 실험을 통해 발견한 사실을 바탕으로 이 문제를 완화하는 방법을 제안합니다.
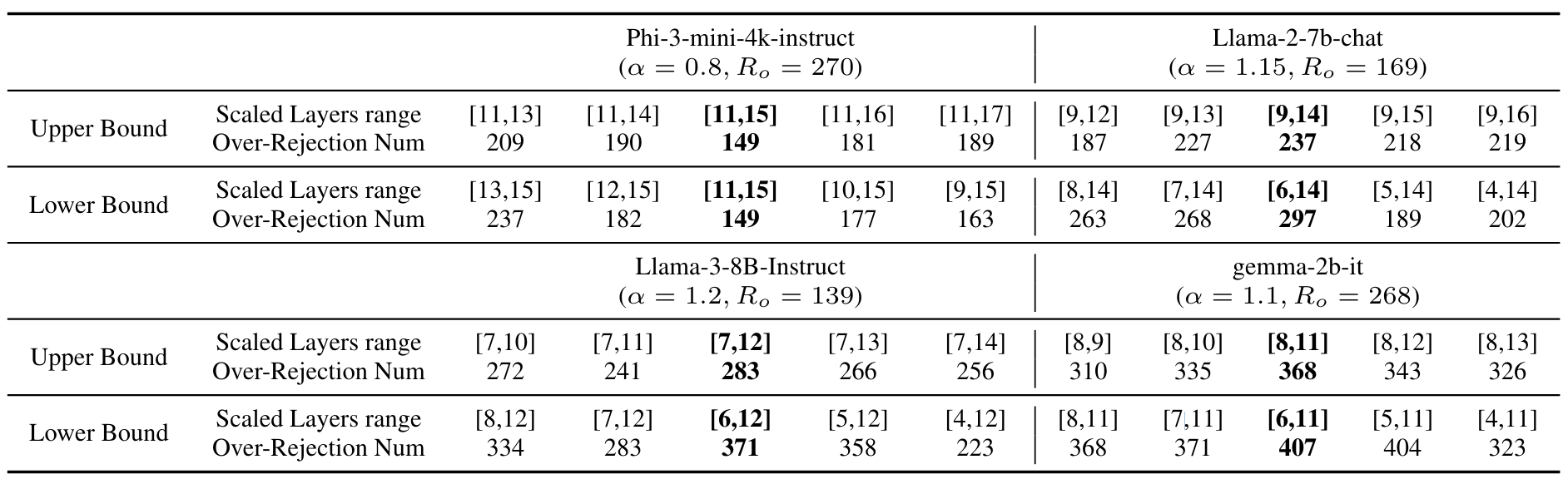
LLM의 특정한 레이어의 영향을 조절하기 위해서는 해당 레이어의 출력에 어떤 상수를 곱해주면 됩니다. 연구진은 특정 범위의 레이어에 상수 α를 곱해서 LLM이 응답을 거부하는 횟수를 측정했습니다. 그리고 이 범위를 바꿔가면서 응답을 거부하는 횟수가 어떻게 변하는지 관찰했습니다. 만약 어떤 레이어를 포함하거나 포함하지 않았을 때, 그 횟수가 극적으로 변하면 해당 레이어가 안전 계층과 큰 연관이 있다고 볼 수 있겠죠. 이런 방식을 반복하면 안전 계층의 범위를 특정할 수 있게 됩니다. |
|
|
상수 α의 값을 조절하며 안전 계층의 범위(Upper Bound, Lower Bound)를 특정하는 작업. 예를 들어 Phi-3-mini-4k-instruct 모델에서 특정 레이어의 영향이 줄어들도록 했을 때, 15번째 레이어를 포함할 경우 갑작스럽게 응답을 거부하는 횟수가 급감한다. 따라서 15번째 레이어가 안전 계층에 포함된다고 결론지을 수 있다.
출처 : Safety Layers of Aligned Large Language Models: The Key to LLM Security (Li et al., 2024)
연구진은 안전 계층의 범위를 특정한 이후, 안전 계층에 해당하는 레이어만 고정하고 나머지 레이어를 파인튜닝하는 방법인 SPPFT(Safely Partial-Parameter Fine-Tuning)를 제안했습니다. 이 방법을 사용하면 LLM의 안전성을 보장하면서 성능까지 유지할 수 있습니다. 실제 실험 결과를 보면 SPPFT를 사용했을 때, LLM의 안전을 평가하는 지표인 Harmful Rate와 Harmful Score은 낮은데 LLM의 성능을 평가하는 지표인 MMLU Score는 높은 것을 확인할 수 있습니다. |
|
|
LLM의 정렬은 아무리 강조해도 지나치지 않은 문제입니다. LLM은 인간의 역사 속에서 탄생한 그 어떤 도구보다 큰 잠재력을 갖고 있습니다. 문제는 그 잠재력이 어느 방향으로 싹틀지 아무도 알 수 없다는 것이죠. 그래서 LLM이 길들여지지 않은 맹수가 되지 않도록, 이를 확실하게 제어하는 방법을 마련할 필요가 있습니다. LLM의 정렬은 단순히 안전성을 위한 것뿐만은 아닙니다. 의도한 대로 통제할 수만 있다면, LLM은 인간의 삶을 획기적으로 개선하는 데 있어 최고의 조력자가 될 것입니다. 따라서 신뢰할 수 있는 LLM은 그 무엇보다 중요한 연구 주제입니다.
오늘 소개한 연구의 의의는 바로 여기에 있습니다. 신뢰할 수 있는 LLM을 만드는 방법을 제안하는 데 그치지 않고, LLM의 작동 원리를 분석하여 안전성을 통제할 방법을 모색했기 때문이죠. LLM은 분명 유용하지만, 여전히 많은 사람은 이 기술에 대한 불안감을 떨치지 못하고 있습니다. 아마 이것이 무슨 생각으로 글을 쓰고 그림을 그리는지 알 수 없기 때문이겠죠. 인간이 만든 기술인데, 인간이 제어하기 어렵다니 이상하기만 합니다. 하지만 끊임없이 도전하는 연구자들의 노력 덕분에, 언젠가는 우리가 낳은 기술을 완벽히 통제하고, 그로 인해 곧 한층 더 발전한 미래를 맞이할 수 있지 않을까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|