연산 효율 문제가 지속적으로 지적되는 트랜스포머, 과연 어떤 문제를 갖고 있을까요? # 46 위클리 딥 다이브 | 2024년 7월 3일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 트랜스포머의 연산 효율 문제에 대해 정리합니다.
- 전통적인 시퀀스 처리 모델인 RNN에 대해 설명합니다.
- 트랜스포머의 단점을 극복하기 위해 이루어진 최신 연구를 소개합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
인공지능에 대한 관심에 부응하기 위해 연구자들은 밤낮을 가리지 않고 연구에 매진하고 있습니다. 매일같이 쏟아지는 수많은 논문이 그 증거이죠. 그 중에서도 작년 말부터 특히 주목을 받은 논문 중 하나가, Mamba: Linear-Time Sequence Modeling with Selective State Spaces입니다. Mamba는 트랜스포머(Transformer)의 한계를 극복한 대체자로써 많은 기대를 받았습니다.
트랜스포머(Transformer)는 현대 딥러닝의 황금기를 주도한 아키텍처입니다. 2017년 Attention Is All You Need라는 논문에 의해 세상에 처음 알려진 이후 현재까지 딥러닝 아키텍처의 1인자 자리를 굳건히 지켜왔습니다. 그런데 최근 트랜스포머의 한계가 지적되면서 새로운 아키텍처에 대한 필요성이 계속해서 강조되고 있습니다. 그렇다면 트랜스포머는 어떤 문제를 가지고 있을까요? |
|
|
트랜스포머는 셀프 어텐션(Self-Attention) 메커니즘을 기반으로 하는 아키텍처입니다. 셀프 어텐션은 한 문장에 포함된 토큰들끼리의 관계를 학습하여 문장의 의미를 이해하는 메커니즘입니다. 이를 바탕으로 트랜스포머는 시퀀스 모델링을 효과적으로 수행하며, 기존에 사용하던 CNN과 RNN의 단점을 해소했습니다. |
|
|
📖 시퀀스(Sequence)
시퀀스란 순서가 있는 일련의 데이터를 뜻합니다. 텍스트, 음악, 비디오 등이 모두 시퀀스에 해당합니다. 자연어 처리에서는 텍스트를 토큰(Token)의 시퀀스로 표현합니다. 토큰은 딥러닝 모델이 한 번에 처리할 수 있는 최소 단위의 텍스트를 의미합니다. 예를 들어, 단어를 하나의 토큰으로 취급한다면, 모델은 주어진 문장에서 단어를 한 개씩 처리합니다.
자연어 처리에서 텍스트를 토큰의 시퀀스로 취급하여 태스크를 수행하는 것을 시퀀스 모델링이라고 하는데, 트랜스포머는 특히 시퀀스 변환(Sequence Transduction)을 위해 등장한 모델입니다. 대표적인 시퀀스 변환의 예시로는 기계 번역(Machine Translation)이 있는데, Attention Is All You Need 논문에서도 트랜스포머의 성능을 측정하는 주요 태스크로 기계 번역을 사용했습니다.
|
|
|
트랜스포머의 장점은 여러 가지가 있지만 그 중에서도 Self-Attention의 연산 효율에 주목하겠습니다. 아래 표에서 두 번째 열은 레이어 당 연산복잡도(Complexity per Layer)를 나타냅니다. 여기서 n은 시퀀스의 길이, d는 벡터의 차원에 해당합니다. |
|
|
각 개념을 간단히 설명하면 이렇습니다. 딥러닝 모델은 자연어 문장을 그대로 처리할 수 없기 때문에 텍스트를 벡터로 변환하는 과정이 필요합니다. 예를 들어 “The cat sat on the mat.”라는 문장의 각 토큰은 d개의 실숫값을 나열한 벡터로 변환됩니다. 트랜스포머는 모델 크기에 따라 이 값으로 512 또는 1024를 사용합니다. 그리고 구두점을 제외하고 각 단어를 하나의 토큰으로 생각하면 n은 6이 됩니다. |
|
|
출처 : ChatGPT로 제작 “The cat sat on the mat.”
그런데 셀프 어텐션의 연산량은 n에 영향을 많이 받고, RNN과 CNN은 d에 영향을 많이 받습니다. 당시에는 딥러닝 모델이 처리하는 시퀀스의 길이가 짧았기 때문에 셀프 어텐션 레이어의 이런 특징은 매우 큰 장점이었습니다. 실제로 논문에서도 다음과 같이 쓰여 있습니다. 참고로 트랜스포머는 d 값으로 512, 1024를 사용했는데, 기계 번역 모델 학습에 사용한 문장은 대부분 100 단어 이하로 길이를 가졌습니다. |
|
|
연산 복잡도 면에서 셀프 어텐션 레이어는 시퀀스 길이 n이 벡터 표현의 차원 d보다 짧을 때 RNN보다 빠른데, 대부분의 상황에서 n이 d보다 작다. … (In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case with sentence representations used by state-of-the-art models in machine translations …) |
|
|
하지만 최근에는 이러한 경향이 완전히 뒤바뀌었습니다. 우수한 문장 생성 능력을 갖추게 된 언어 모델은 이제 일반적인 목적으로 사용되고 있는데, 그 이유 중 하나는 언어 모델이 처리할 수 있는 문장의 길이가 매우 길어졌기 때문입니다. 언어 모델이 한 번에 처리할 수 있는 텍스트의 길이를 Context Length 또는 Context Window라고 합니다.
트랜스포머가 처음 등장했을 때는 이 길이가 길어야 백 단위에 그쳤지만, 현재 대규모 언어 모델이 처리할 수 있는 문맥의 길이는 수천(K)에서 수백만(M) 단위에 이르렀습니다. 즉, 과거와 다르게 d보다 n이 커지게 된 것입니다. 이런 현상 때문에 연산 복잡도가 문장 길이 n에 의존한다는 장점은 이제 단점이 됐습니다. LLM의 시대에서 트랜스포머는 이제 생성 속도를 느리게 하는 걸림돌이 되어버린 것이죠. |
|
|
속도가 문제라면 다시 RNN을 사용하면 되는 게 아닐까요? 하지만 거기에는 또 다른 문제가 있습니다. 애초에 셀프 어텐션이 나중에 등장한 메커니즘인 만큼, RNN의 단점을 보완하는 역할을 했을 거라고 예상할 수도 있었을 것입니다. RNN의 문제는 기억력입니다.
기억력의 문제란 어떤 의미일까요? 기계가 기억력의 문제를 갖는다니 조금 와닿지 않을 수 있습니다. RNN의 기억상실증에 대해 알아보기 위해서는 그 구조를 먼저 이해해야 합니다. 우선 RNN이 등장한 배경을 간단히 알아보죠.
딥러닝의 분야의 큰 축을 이루는 두 분야인 컴퓨터 비전(CV, Computer Vision)과 자연어 처리(Natural Language Processing) 중 NLP의 발전 속도가 늦춰진 원인 중 하나는 데이터의 특성 때문입니다. 딥러닝 모델을 설계하기 위해서는 입력받을 데이터의 형태를 사전에 알아야 하는데, 이미지는 정해진 크기로 모두 변환하여 일정한 형태를 갖게 할 수 있지만, 문장의 길이는 그럴 수가 없습니다.
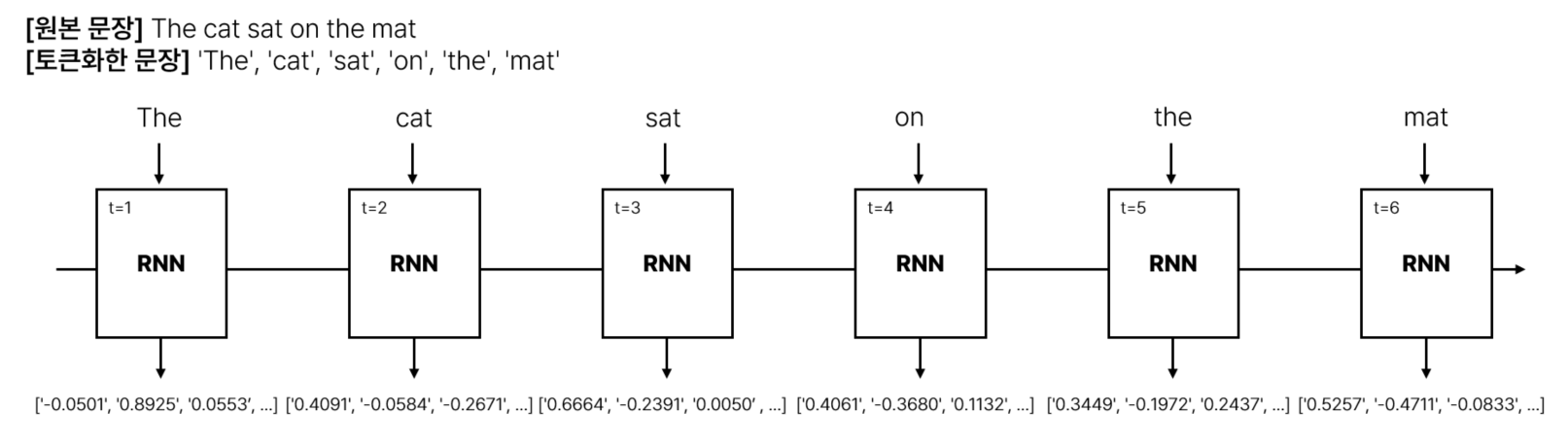
그래서 가변적인 길이의 데이터, 즉 시퀀스를 다루기 위한 모델이 필요했고, 그렇게 탄생한 게 바로 RNN(Recurrent Neural Network)입니다. 우리말로는 순환 신경망 또는 재귀 신경망이라고 합니다. RNN은 정해진 공간에 문장의 각 토큰을 순차적으로 입력받으며 학습된 정보를 갱신하는 구조를 갖습니다. 아래 그림과 같이 "The cat sat on the mat."라는 문장의 각 단어를 한 개씩 입력받고, 누적된 입력을 바탕으로 저장된 정보를 갱신하며 학습합니다.
이런 방식을 사용하면 사전에 입력으로 들어올 문장의 길이를 몰라도 된다는 장점이 있습니다. 하지만 RNN의 이런 특성 때문에 앞에서 언급한 기억상실증 문제가 발생합니다. 처음에 본 정보는 시간이 갈수록 잊게 되는 것이죠. |
|
|
그럼에도 불구하고 다시 RNN을 사용하려는 시도가 계속해서 이루어지고 있습니다. 구글은 RNN에 기반한 Hawk와 Griffin이라는 모델을 개발하였고, 이를 사용한 언어 모델 RecurrentGemma를 발표하였습니다. RWKV라는 논문에서는 트랜스포머처럼 학습하여 기억력의 한계를 극복하고, RNN처럼 추론하여 연산 효율성을 높이는 아키텍처를 소개했습니다. 또한 한 연구에서는 트랜스포머가 RNN의 변형이라는 해석을 바탕으로 Aaren이라는 모듈이 제안되기도 했습니다.
인공지능이 실생활에 파고들면서, 성능 못지 않게 중요해진 것이 바로 속도입니다. 빠르고 효율적인 모델만이 사용자가 원하는 시점에 결과를 제공할 수 있기 때문입니다. 그런데 트랜스포머의 연산 효율성 문제는 하드웨어의 한계와 맞물려 처리 속도의 중요성이 더욱 부각되고 있습니다. 이런 상황에서 RNN의 재조명은 단순히 과거로의 회귀가 아니라, 새로운 가능성을 모색하는 과정입니다.
한때 빌 게이츠가 “모든 가정에 PC를"이라는 비전을 제시했듯, 오늘날의 AI 연구자들은 “모든 이에게 AI를”이라는 꿈을 품고 있을지도 모릅니다. 현재 인공지능 분야의 발전 속도를 보면, 그들이 그리는 미래가 생각보다 현실과 가깝다고 느껴지기도 합니다. 앞서 살펴본 다양한 연구 덕분에, 머지않아 개인용 AI가 실험실 문 밖으로 나와 우리의 일상에 다가올 것입니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|