EMNLP 2025에 채택된 논문을 살펴보며 NLP 연구 흐름을 파악해봅니다. #112 위클리 딥 다이브 | 2025년 10월 8일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- EMNLP 2025에 채택된 논문의 주제를 분석합니다.
- NLP 분야의 연구 흐름과 전망을 제시합니다.
- 참신한 관점의 EMNLP 연구 3가지를 소개합니다.
|
|
|
📈 EMNLP 2025 논문으로 알아보는 NLP 트렌드 |
|
|
안녕하세요, 에디터 배니입니다.
2025년도 어느새 막바지에 접어들었습니다. 올해의 노벨상 수상자도 공개되고 있고, 슬슬 올해 AI의 발전을 회고하는 글들도 올라오고 있습니다. (참고로, 매년 발간되는 State of AI Report 2025도 내일(10월 9일) 발행될 예정입니다.)
deep daiv.에서도 올해 많은 팀원들이 주목할 만한 성과를 올렸는데요. 그중 한 가지는 뉴스레터 에디터들이 저자로 참여한 논문이 이번이 EMNLP 2025 Findings로 채택됐다는 소식입니다! 🎉 |
|
|
30주년을 맞은 이번 EMNLP는 중국 쑤저우 시에서 개최된다.
현장 참가를 준비하면서 이번 EMNLP 2025에 채택된 논문 목록을 살펴봤습니다. EMNLP는 NLP 학회 중에서 높이 평가 받는 학회 중 하나인데요. 때문에 EMNLP에 채택된 논문을 연도별로 비교해보면 보면 NLP 트렌드와 변화를 가늠할 수 있습니다. 이번 뉴스레터에서는 EMNLP 2025에 채택된 논문을 분석하고, 그중 흥미로운 관점의 연구를 몇 가지 소개하도록 하겠습니다. |
|
|
EMNLP 2025에는 어떤 논문들이 채택됐을까? |
|
|
AI의 발전을 특히 체감할 수 있는 분야가 바로 NLP 아닐까 싶은데요. 그만큼 NLP는 AI 분야 중에서도 실용적인 가치가 높은 학문입니다. EMNLP는 그 이름에서 알 수 있는 것처럼 경험적 방법론(Emperical Methods)을 중시하는 학회입니다. 그래서 다른 AI 학회에 비해 이론적 검증보다는 실험을 기반으로 한 실용적인 성격의 연구 논문이 많이 채택되는 편입니다.
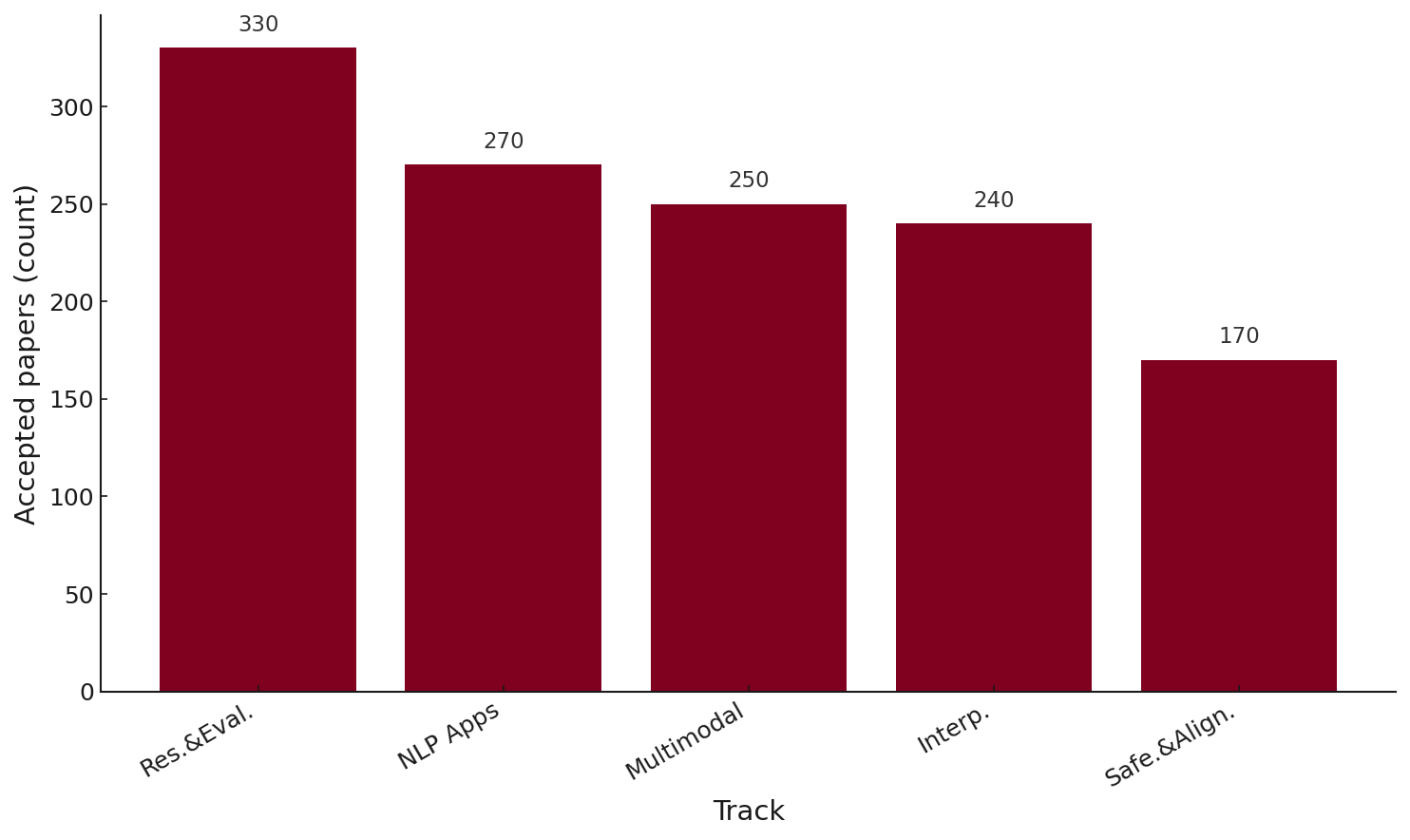
이번 EMNLP 2025에는 8174건의 논문이 제출되었고, 그중 약 22%가 Main, 17%가 Findings로 채택됐습니다. 결과적으로 약 3200여 건 정도가 채택된 것인데요. 이중에서 가장 많은 비중을 차지하는 주제(Track)는 Resources and Evaluation로 약 330여 건, 다음으로 NLP Application이 약 270여 건입니다. 이 두 주제는 모두 EMNLP의 방향성을 잘 보여줍니다. 그 뒤로 Multimodal(250여 건), Interpretability(240여 건), Safety and Alignment in LLMs(170여 건) 등으로 높은 비중을 차지하고 있습니다. (아직까지 공식적으로 공개된 자료가 아니며, 수정될 여지가 있다는 점은 참고해주시기 바랍니다.) |
|
|
EMNLP 2025의 트랙별 대략적인 채택 논문 수
출처: EMNLP 2025 (이미지: 에디터 편집)
|
|
|
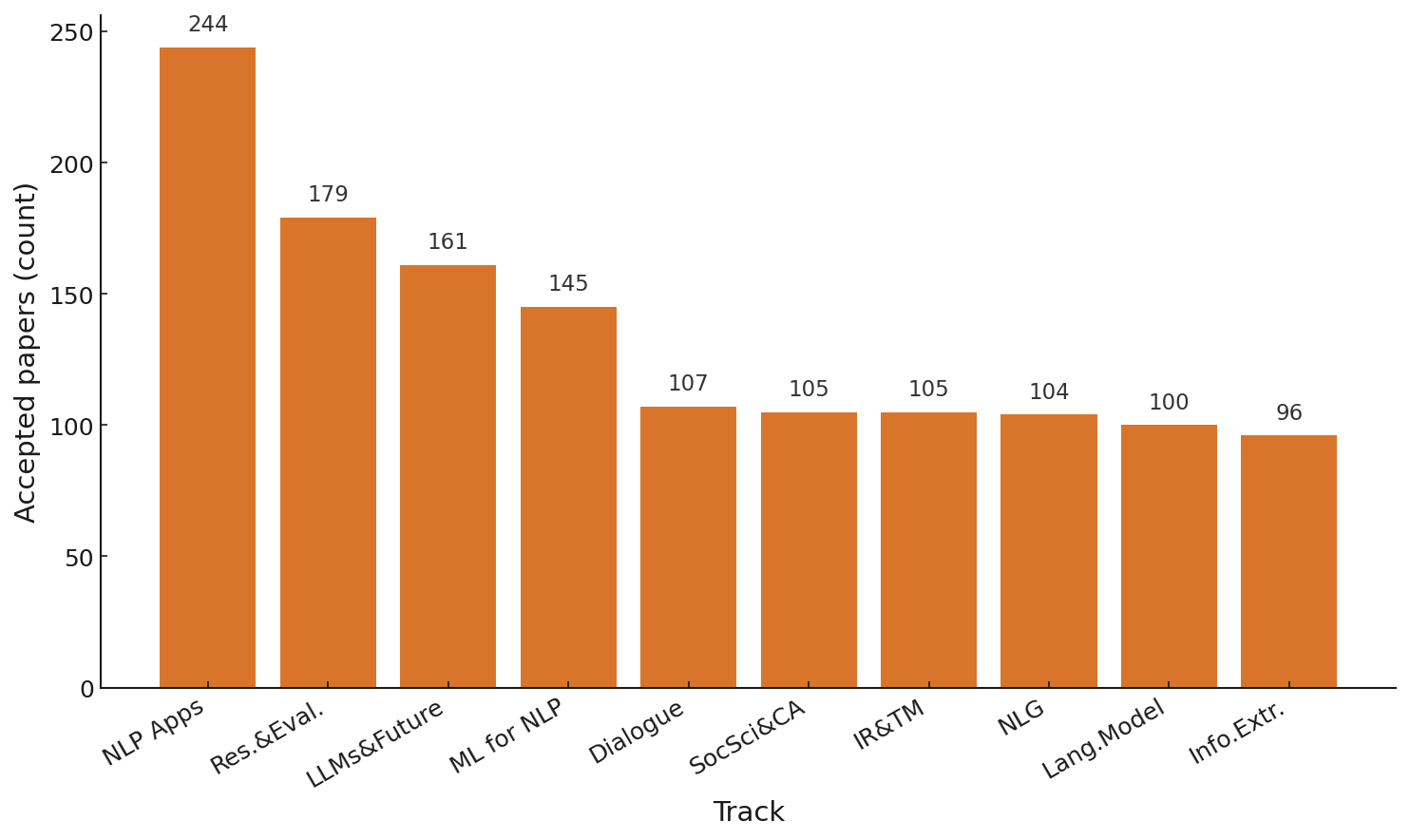
아래 그림은 EMNLP 2023의 트랙별 채택 논문 수를 나타낸 차트입니다. NLP Application, Resources가 상위에 위치하긴 하지만 그외에 다른 키워드를 찾아보기는 어렵습니다. 확실히 올해의 경향성은 2-3년 전과 대비되는 것을 보여주는데요. ChatGPT가 등장한지 이제 만 3년이 되고 있다는 점을 생각해보면 얼마나 빠르게 연구 방향성이 달라졌는지 체감할 수 있습니다. 올해의 눈에 띄는 변화가 있다면, 이제는 머신 러닝과 같은 키워드는 사라지고 자연어 생성, 모델링 기법 자체보다는 멀티모달 / 해석 방법 같은 언어 모델을 제어하기 위한 응용 분야에 더욱 치중한 연구가 늘어났다는 것입니다. |
|
|
EMNLP 2023의 트랙별 대략적인 채택 논문 수
출처: EMNLP 2023 (이미지: 에디터 편집) |
|
|
즉, 정리하면 이미 언어 모델의 성능이 어느 정도 궤도에 올랐고 다른 모달리티와 결합하여 활용할 수 있는 방법, 언어 모델 자체를 더욱 안전하게 활용할 수 있는 방법을 집중적으로 연구하고 있는 것으로 분석할 수 있습니다.
아마 여러분들이 체감하기에도 최근 공개된 언어 모델 서비스의 성능이 비약적으로 개선됐다는 느낌을 받기 어려웠을 것입니다. 보통 연구 흐름이 서비스에 앞선다는 점을 고려한다면, 앞으로도 LLM 모델의 비약적인 개선보다는 조금 더 다양한 방면(의료, 법률 분야)으로 안전하게 활용할 수 있는 AI 서비스가 공개되지 않을까 싶습니다. |
|
|
마음대로 꼽아본 EMNLP 2025 흥미로운 논문 3가지 |
|
|
1. 가짜 뉴스 시뮬레이션
개인적으로는 LLM의 사회과학적인 활용에 관심이 많습니다. 어떻게 하면 LLM을 세상에 이롭게 활용할 수 있을지 고민해보고는 하는데요. 그중 하나가 가짜뉴스입니다. 가짜뉴스의 종류는 다양합니다. 한 눈에 봐도 의도적으로 만든 허황된 가짜뉴스부터 미묘하게 진실이 섞여 있는 가짜뉴스도 존재합니다. (잠시 언론학적인 가짜뉴스의 정의는 제쳐두겠습니다.) |
|
|
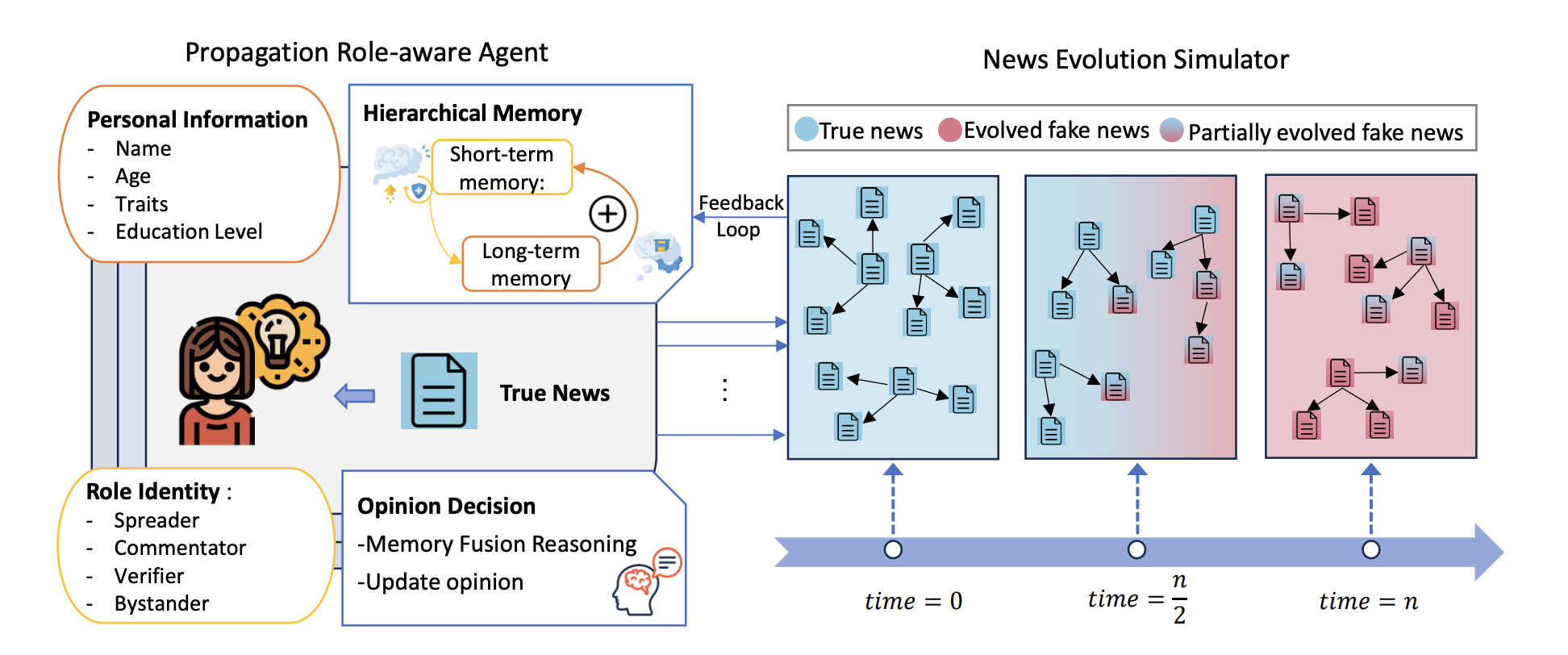
지금까지는 가짜뉴스를 생성하거나 탐지하는 논문이 많이 발표됐습니다. 그러나 이번에 공개된 논문에서는 이와는 다른 시각으로 가짜뉴스 문제를 다룹니다. 바로, 가짜뉴스가 생성되는 과정을 LLM으로 시뮬레이션한 것인데요. LLM을 여러 역할(전파자·논평자·검증자·방관자)로 나누어 ‘토론’과 상호작용을 통해 진짜 뉴스가 어떻게 점진적으로 왜곡되어 가짜뉴스로 진화하는지를 관찰합니다. 그 결과, 민감한 주제에서 진짜 뉴스가 가짜뉴스로 변화하는 속도가 빠르다는 사실과 함께 조기에 권위적으로 개입하는 경우 가짜뉴스의 확산을 의미 있게 줄일 수 있음을 보여줬습니다. 시나리오를 정확하게 분석한다면 가짜뉴스가 생성되는 과정을 역으로 탐지하며 가짜뉴스 생성을 방지할 수 있겠죠.
2. Diffusion LLM의 시대가 올까?
LLaDA 모델을 들어보셨나요? 저희 뉴스레터에서도 한 번 다룬 적이 있었는데요. 올해 초부터 Diffusion 방식으로 학습한 언어 모델이 주목받으면서 Autoregressive(AR) 구조를 완전히 대체할 수 있을지 많은 분석이 이어지고 있습니다. 이런 변화의 흐름이 중요한 이유는 언어를 이해하고 표현하는 방식의 철학이 달라지기 때문입니다.
|
|
|
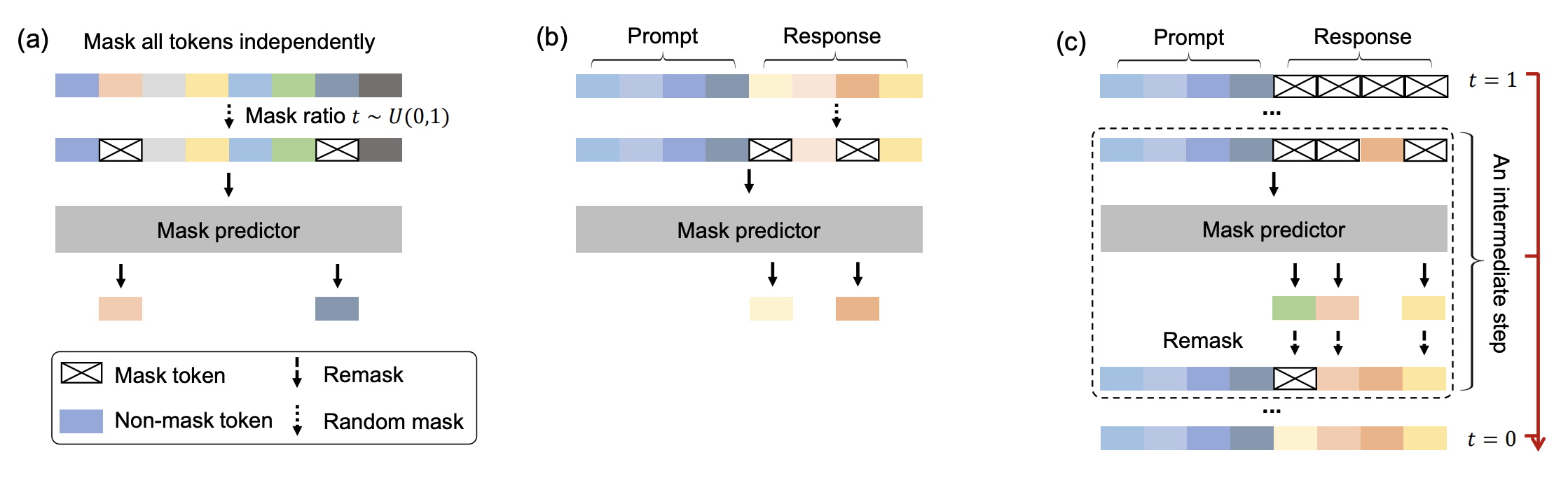
AR 구조는 왼쪽에서 오른쪽으로 단어를 예측하며 문장을 쌓아가는 형태로 문장을 생성합니다. 이와 달리 Diffusion 구조는 노이즈를 반복적으로 제거하면서 텍스트 전체의 의미를 정제해 갑니다. AR은 지역적 문맥과 흐름에 강하지만, Diffusion은 문서 전체의 전역적 구조와 논리적 일관성을 더 잘 포착하는 것으로 알려졌습니다.
이번에 발표된 연구에서는 이러한 Diffusion Language Model의 양방향적 구조와 반복적 정제 과정이 언어 의미 학습에 더 적합하다는 점에 주목했습니다. 기존 AR 기반의 단방향 Attention 모델의 한계를 비판하고, Diffusion 방식으로 언어 의미를 포착하여 전체 문맥의 일관성을 더 정확히 표현할 수 있음을 보여줬습니다. 실제로 인간이 글을 쓸 때도 앞의 문맥만 확인하는 것이 아니라, 뒤에 작성한 내용을 보면서 다시 앞의 내용을 수정하기도 하는데요. 이런 연구 결과는 앞으로의 언어모델 학습 패러다임이 단순 생성에서 정제 중심으로 옮겨갈 가능성을 시사합니다.
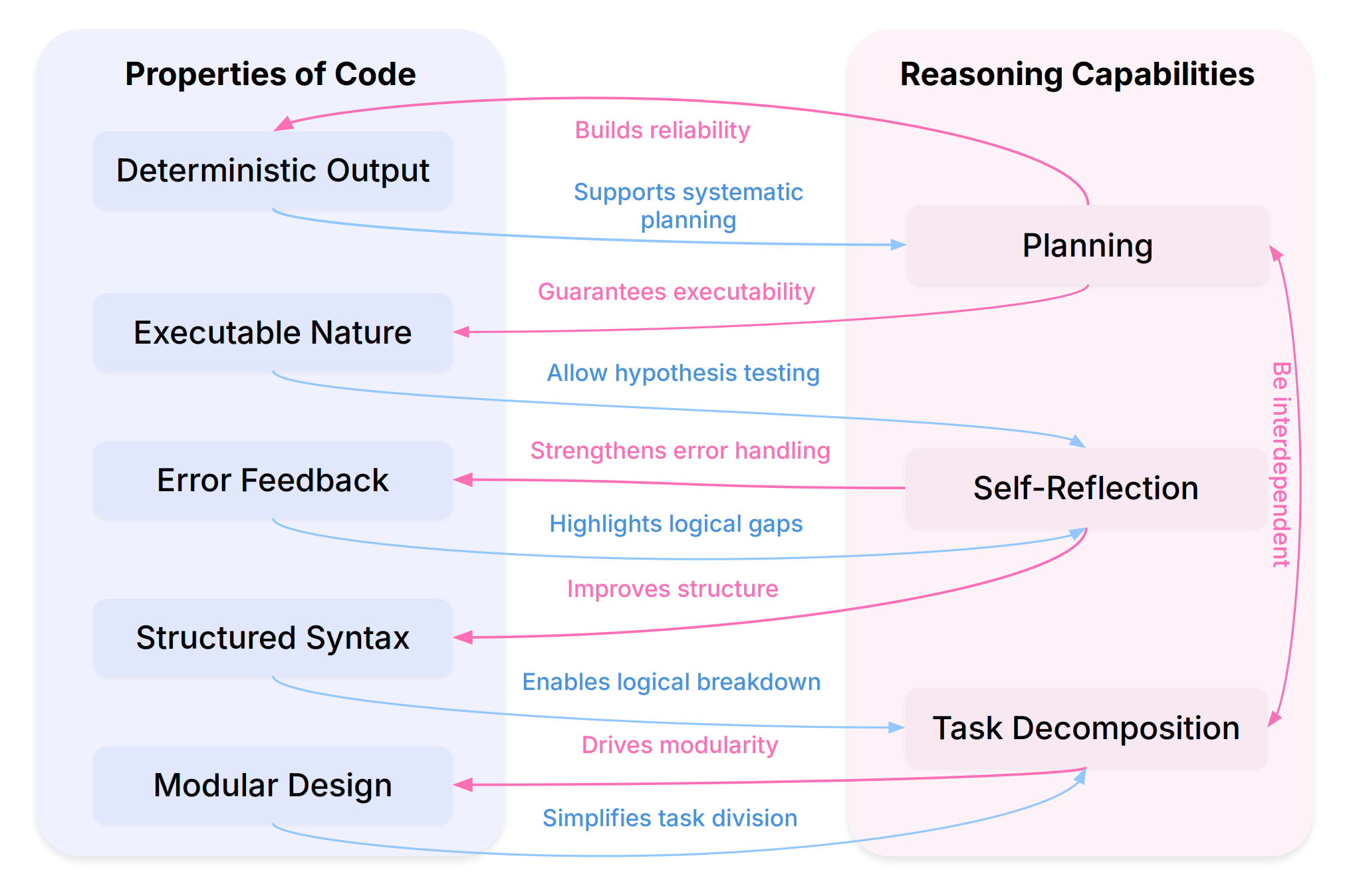
3. 코드는 논리적 언어다.
코딩을 잘하는 친구들이 논리적 사고력이 좋다는 말을 들어보셨나요? 올해 초 Meta에서 공개한 이 연구는 이 논리에 근거하여 LLM의 추론 능력을 향상시키고자 합니다. 좋은 언어 추론을 하기 위해 코드를 학습하고, 코드를 학습하기 위해 다시 언어 추론 방법을 학습하는 것(Code to Think, Think to Code)입니다. 코드를 단순한 학습 결과물이 아니라 코드 자체를 논리적 사고를 훈련할 수 있는 하나의 과정으로 본 것입니다.
코드의 구조적인 문법과 모듈성, 실행 가능성을 판단하는 과정에서 모델이 스스로 사고 경로를 점검하며 피드백하는 것처럼 일반적인 자연어 질문에서도 비슷한 논리를 적용할 수 있고, 반대로 추론 능력을 함양하면서 다시 코드를 생성하는 방법을 익히는 것이죠. 연구자들은 이를 ‘뫼비우스의 띠’로 비유합니다. 두 영역이 서로 순환적으로 발전한다고 주장하는 것이죠. |
|
|
위의 주장을 검증하기 위해 코드가 추론을 향상시키는 방향과 추론이 코드 지능을 발전시키는 방향으로 나누어 분석했는데요. 연구팀은 방대한 선행 연구를 종합해 서베이 형식으로 논문을 발표했습니다. 약 60여 편의 논문을 분석하며 코드-추론의 과정이 모델이 ‘생각하는 법’을 배우는 과정이라는 것을 보여줍니다. |
|
|
이밖에도 이번 EMNLP 2025에는 흥미로운 논문이 쏟아졌습니다. 학회 이름에 걸맞게 실용적인 논문이 많이 발표되면서 앞으로 NLP 분야의 발전을 기대하게 만들었는데요. 벌써부터 현장의 열띤 토론 분위기가 기대됩니다. 기회가 된다면 이번 EMNLP에서 구독자분들을 뵐 수 있었으면 좋겠네요. (혹시라도 현장에서 짧은 만남을 희망하신다면 인스타그램(@deep.daiv) DM이나 메일 회신 부탁드립니다 🙂) |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|