멀티 에이전트 프레임워크 PosterAgent를 소개합니다. #94 위클리 딥 다이브 | 2025년 6월 4일
에디터 스더리 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 멀티 에이전트 프레임워크 PosterAgent를 소개합니다.
- Poster2Paper라는 새로운 벤치마크를 소개합니다.
- 포스터의 품질을 평가할 수 있는 지표들에 대해 정리합니다.
|
|
|
🤜🤛 포스터 만드는 AI 팀플, PosterAgent
|
|
|
안녕하세요, 에디터 스더리입니다.
논문을 쓰고 나면 그다음은 발표 준비, 그리고 포스터 제작까지. 연구 경험이 있는 분들이라면 한 번쯤은 논문의 핵심을 요약해 시각적으로 표현하는 일의 어려움을 겪어보셨을 텐데요! 최근 발표된 Paper2Poster 논문은 이런 고민에 딱 맞는 흥미로운 시도를 소개합니다.
Paper2Poster의 핵심 과제는 단순합니다. 논문을 받아 한 장짜리 포스터로 요약하는 것! 하지만 이를 제대로 수행하기 위해선 다음과 같은 난관들을 넘어야 합니다.
- 긴 문맥과 긴 추론: 수천 단어에 달하는 논문에서 핵심만 뽑아내는 작업은 단순 요약을 넘어 계층적 이해와 반복적인 사고를 요구합니다.
- 텍스트와 시각 자료의 얽힘: 그림, 표, 수식이 텍스트에 촘촘히 얽혀 있기 때문에, 이를 정확히 뽑고 적절히 연결하는 능력이 필요합니다.
- 공간 제약 속 레이아웃 구성: 단순히 요약된 텍스트만 생성하는 것이 아니라, 텍스트와 이미지를 한정된 공간에 보기 좋게 배치하는 능력도 요구됩니다.
그렇다면 이런 복잡한 과제를 AI는 어떻게 해결할 수 있을까요? |
|
|
PosterAgent는 핵심 내용을 뽑고, 이를 포스터 형식으로 구성하는 자동화된 파이프라인을 제안합니다. 더 나아가 이 시스템을 평가하기 위한 벤치마크인 Paper2Poster와 평가 지표도 함께 제시했다는 점에서 더욱 주목할 만합니다. 그렇다면 이 시스템은 어떤 방식으로 작동하며, 이의 효과를 어떻게 평가할까요? |
|
|
먼저 포스터를 만든다고 상상해봅시다. 어떤 단계부터 거치게 될까요? 아마도 먼저 논문의 핵심 내용을 추려야 할 테고, 이를 시각 자료와 함께 어떻게 배치할지 고민한 뒤, 전체 레이아웃을 다듬어가는 과정을 거치게 되겠죠?! |
|
|
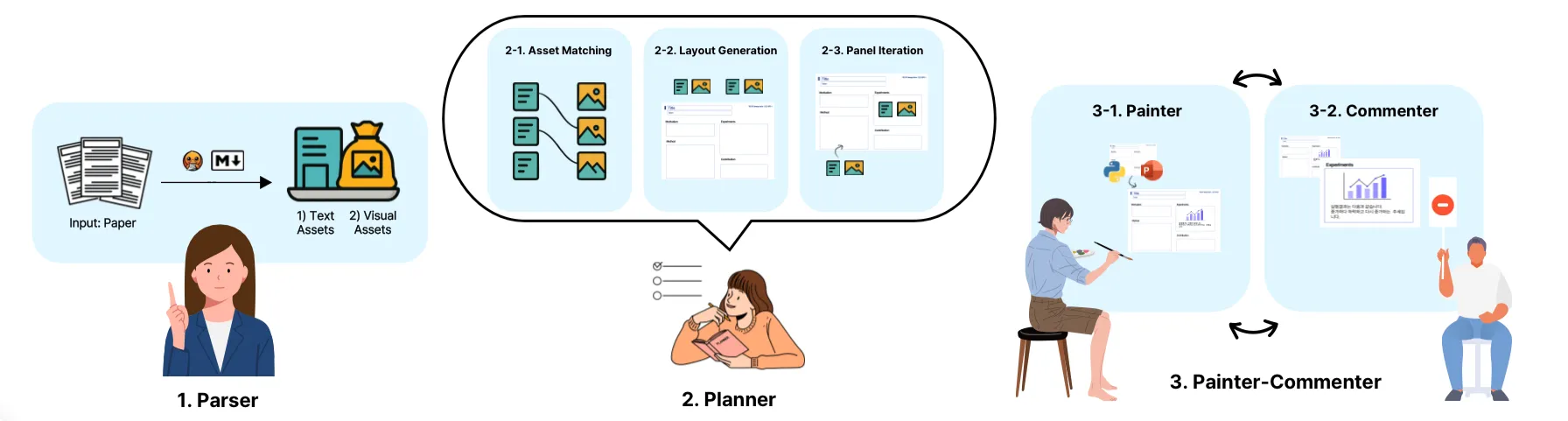
멀티에이전트 시스템인 PosterAgent 역시 이와 비슷한 과정을 따릅니다. 각 에이전트는 팀 프로젝트에서 역할을 나누듯, 논문을 정리하는 Parser, 구조를 기획하는 Planner, 결과물을 만들고 평가하는 Painter–Commenter로 구성됩니다. |
|
|
먼저, Parser입니다. Parser는 논문을 포스터 제작에 필요한 ‘자산(Asset)’으로 전환하는 역할을 맡습니다. 여기서 자산은 두 가지로 나뉩니다. 먼저 텍스트 자산(Text Assets)은 섹션별 제목을 기준으로 해당 내용을 간결하게 요약한 것으로, 논문의 계층적 구조를 살린 텍스트 기반 요약입니다. 다음으로 시각 자산(Visual Assets)은 그림이나 표의 캡션을 키(Key)로 하여 관련 이미지 파일을 함께 저장한 것으로, 포스터에 시각적으로 활용될 수 있는 요소들입니다.
특히 Parser는 단순한 추출을 넘어서, 논문 전체를 핵심 의미를 유지한 채 구조화된 형태로 압축하는 작업을 수행합니다. 이를 위해 MARKER(PDF를 Markdown으로 변환하는 도구)와 DOCLING(문서의 계층 구조를 분석하는 도구)을 활용하며, 이렇게 정제된 내용은 LLM에 입력되어 섹션 단위의 계층적 JSON 구조로 재구성됩니다. |
|
|
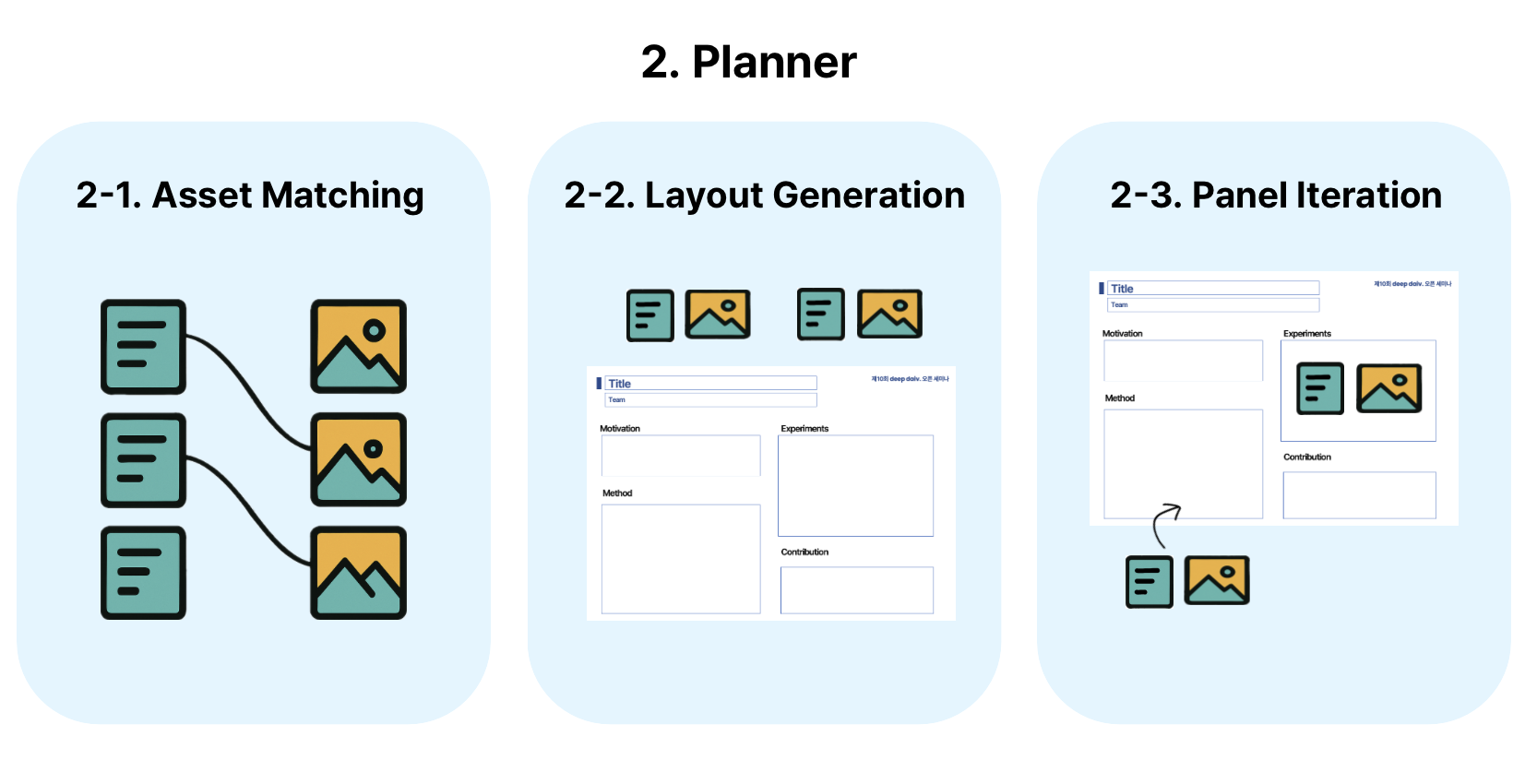
다음 단계인 Planner는 포스터 제작의 ‘설계자’ 역할을 합니다. 마치 웨딩 플래너가 공간과 순서를 조율하듯, 정보와 시각 요소의 배치를 책임지죠. 따라서 포스터를 한 번에 완성하는 것이 아니라, 순차적이고 반복적인 방식으로 포스터를 구성합니다.
Asset Matching 과정에서는 시각 자산(그림, 표 등)을 가장 관련 있는 텍스트 자산과 연결합니다. 예를 들어, 도입부 요약에는 ‘Teaser Image’를, 결과 섹션에는 실험 결과 표를 대응시키는 식입니다. 이 작업은 LLM을 활용하여 시각 자산과 텍스트 자산 사이의 의미적 유사성을 기반으로 수행되며, 결과적으로 (텍스트 자산 → 시각 자산) 쌍이 형성됩니다.
이후에는 Planner의 가장 중요한 역할로 볼 수 있는 Layout Generation이 이뤄집니다. 각 섹션이 포스터 내에서 어떤 위치와 크기를 차지할지를 결정하는 단계로, 저자들은 단순히 포스터 내 좌표를 LLM이 예측하는 방식은 불안정하다고 판단하여, 텍스트 길이, 시각 자산의 크기 등을 고려하는 Binary-Tree Layout 전략을 채택했습니다. 이는 포스터 공간을 트리 구조로 재귀적으로 분할해, 각 섹션의 분량에 비례한 영역을 할당하는 방식으로, 이를 통해 읽는 순서를 유지하면서도, 균형 잡힌 패널 레이아웃을 더 안정적으로 구성할 수 있습니다.
마지막으로 Panel Iteration은 각 섹션에 해당하는 패널을 실제 콘텐츠로 채우는 단계입니다. Planner는 각 섹션의 요약을 반복적으로 다듬어 간결하면서도 계층적인 구조가 드러나는 불릿포인트(Bullet Point) 형태로 다시 정리합니다. 이는 사람이 포스터를 구성하면서 초안을 채우고 점차 다듬어가는 방식과 유사합니다. |
|
|
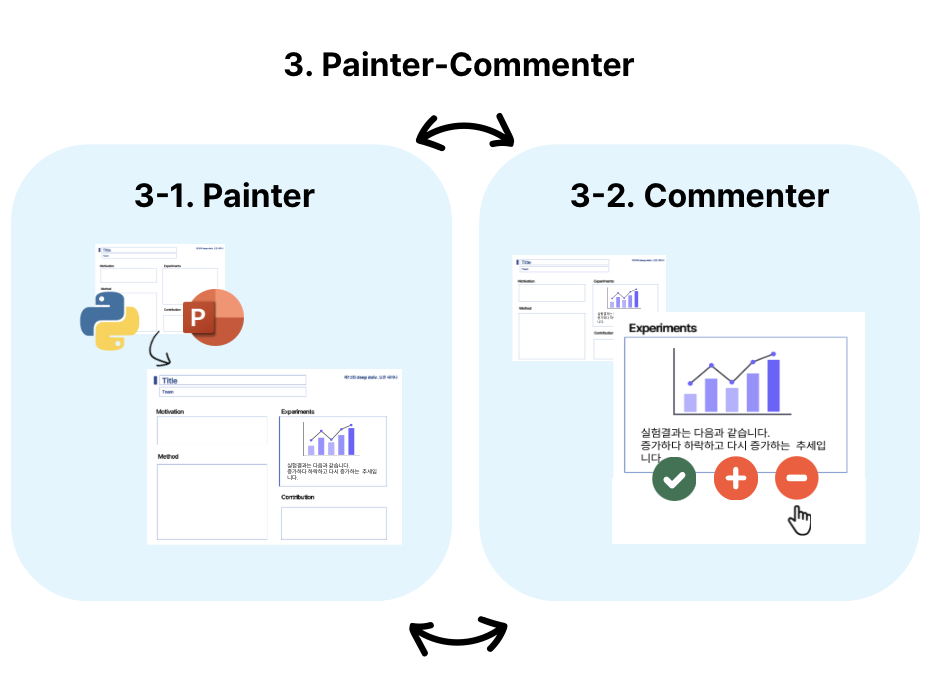
마지막 단계인 Painter–Commenter는 두 에이전트가 협업하며 반복적으로 작동하는 루프 구조로, 내용을 시각적으로 표현하는 Painter와 그 결과를 평가하는 Commenter로 구성됩니다.
Painter는 Planner 단계에서 정리된 섹션 요약, 시각 자산 쌍을 바탕으로, 각 패널의 내용을 간결한 불릿포인트로 정리한 뒤, python-pptx를 활용해 실제 포스터 패널 이미지를 렌더링합니다. 하지만 한 번의 렌더링으로 이상적인 결과가 나오긴 어렵기 때문에, 이때 Commenter가 개입합니다. Commenter는 시각 언어 모델(VLM)로, 생성된 패널 이미지에 대해 “정보 과잉(Overflow)”, “너무 비어 있음(Too Blank)”, “완료됨(Good to Go)”과 같은 피드백을 제공합니다.
이때 “VLM이 잘못 평가하면 어떡하지?”라는 의문이 들 수도 있죠. 이를 고려해 저자들은 환각(Hallucination) 문제를 보완하기 위한 두 가지 전략을 도입했습니다.
- Zoom-in 전략: 전체 포스터가 아닌 패널 단위 이미지에만 집중해 평가하도록 하여 정확도를 높입니다.
- In-context Reference Prompt: Commenter에게 하나는 실패한 패널 예시, 다른 하나는 이상적인 패널 예시를 함께 제시하여, 보다 일관된 판단을 가능하게 합니다.
이처럼 Painter는 Commenter의 피드백을 반영해 패널을 수정하고 다시 렌더링하는 과정을 반복합니다. 이 루프는 Commenter가 “완료됨”을 출력하거나 반복 횟수 제한에 도달할 때까지 지속되며, 그 결과 정확하고 읽기 쉬우며 시각적으로 균형 잡힌 포스터가 완성됩니다. |
|
|
앞서 만든 에이전트들의 결과물을 실제로 활용하려면, 그 성능을 정량적으로 평가할 수 있어야 합니다. 단순히 “예쁘다”, “깔끔하다”는 감상만으론 부족하죠. 이를 해결하기 위해 논문에서는 새로운 벤치마크, Paper2Poster를 제안합니다.
이 벤치마크는 ICML, NeurIPS, ICLR 등 대표적인 AI 학회의 2022년부터 2024년까지 발표된 논문들 중, 15~50페이지에 달하는 긴 논문들만 선별해 구축되었습니다. 실제 학회 포스터와 매칭된 100쌍의 논문-포스터 데이터가 포함되어 있으며, 가장 최신의 버전(Camera-Ready)만 수집하고, 연도별·학회별로 균형 있게 샘플링해 데이터의 다양성과 품질을 모두 확보한 점도 인상적입니다.
Paper2Poster에서는 포스터의 품질을 총 네 가지 기준으로 평가하는데요, 시각적 품질(Visual Quality), 텍스트 일관성(Textual Coherence)은 물론, 정보 전달력, 실제 이해 가능성까지 종합적으로 반영하기 위해 총체적 평가(Holistic Assesment)와 PaperQuiz를 진행합니다.
-
총체적 평가(Holistic Assessment)
GPT-4o 같은 모델이 포스터 이미지를 직접 보고 평가자 역할을 수행하는 방식입니다. 모델은 디자인과 정보 측면을 다루는 6개 항목에 대해 1~5점 점수를 매기는데, 이 방식을 통해 단순한 이미지 품질을 넘어서, 포스터가 얼마나 읽기 쉽고, 얼마나 유익한지까지 함께 평가하게 됩니다.
|
|
|
-
PaperQuiz
개인적으로 논문에서 가장 흥미로운 부분 중 하나라고 생각했는데요, 이 지표는 포스터가 실제로 논문의 핵심 내용을 잘 전달하고 있는지를 객관식 시험을 통해 확인하는 방식입니다.
- GPT-o3가 원 논문을 바탕으로 100개의 객관식 문항을 자동 생성합니다.
- 다양한 수준의 시각 언어 모델들(Ex. LLaVA(초급), Phi(중급), GPT-4o(상급))에게 포스터만을 읽고 문제를 풀도록 합니다.
- 이 모델들의 정답률이 포스터의 정보 전달력 점수가 됩니다.
또한, 포스터가 텍스트가 과도하게 길 경우 오히려 가독성을 떨어뜨릴 수 있다는 점을 고려하여 텍스트 길이에 따른 감점 요소(Length Penalty)도 함께 적용됩니다. 이로써 간결하고 핵심을 잘 전달한 포스터일수록 높은 점수를 받도록 설계되어 있습니다.
|
|
|
그렇다면 이제 PosterAgent의 실제 결과물도 한번 살펴봐야겠죠? |
|
|
위 그림은 동일한 논문을 기반으로 여러 포스터 생성 방식에 따라 만들어진 결과물들을 보여줍니다. (a)는 원 논문의 저자들이 만든 포스터이고, (b)는 PosterAgent가 생성한 포스터, (d)는 PPTAgent가 생성한 포스터입니다. 각 포스터에 대해 독해력 기반의 PaperQuiz 점수를 매겨 비교했을 때, PosterAgent가 가장 높은 점수(122.67)를 기록하였으며 인간 수준에 근접한 성과를 보임을 알 수 있습니다.
이번 뉴스레터에서는 각기 다른 전문성을 지닌 에이전트들이 협력해, 논문의 핵심을 시각적으로 전달하는 PosterAgent를 소개했습니다. 사람처럼 사고하고, 사람보다 빠르게 만드는 이러한 팀 플레이가 앞으로 어떤 새로운 가능성을 열어갈지 기대됩니다!
|
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|