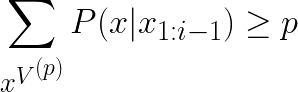확률적 디코딩과 Top-p 샘플링, Temperature을 알아봅니다. #88 위클리 딥 다이브 | 2025년 4월 23일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- Nucleus(Top-p) 샘플링 기법에 대해 알아봅니다.
- 결정론적 디코딩, 확률적 디코딩의 차이를 이해합니다.
- Temperature이 어떤 역할을 하는지 알아봅니다.
|
|
|
안녕하세요, 에디터 잭잭입니다.
이번 주에는 디코딩 샘플링 전략에 대해 알아보려고 합니다. |
|
|
|
위 그림은 ChatGPT API를 설정하는 화면 중 일부입니다. GPT는 2020년 출시된 GPT-3부터, GPT-4.1이 나온 현재까지 Top-p와 Temp 설정을 사용하고 있습니다. 이 두 설정값은 대체 무엇이길래 오랫동안 사용되고 있을까요? |
|
|
언어 모델의 디코딩이란, 모델이 입력 텍스트를 입력받아 출력할 토큰을 예측하는 과정입니다. 따라서 디코딩은 언어 모델의 마지막 단계에서 일어나는데요. |
|
|
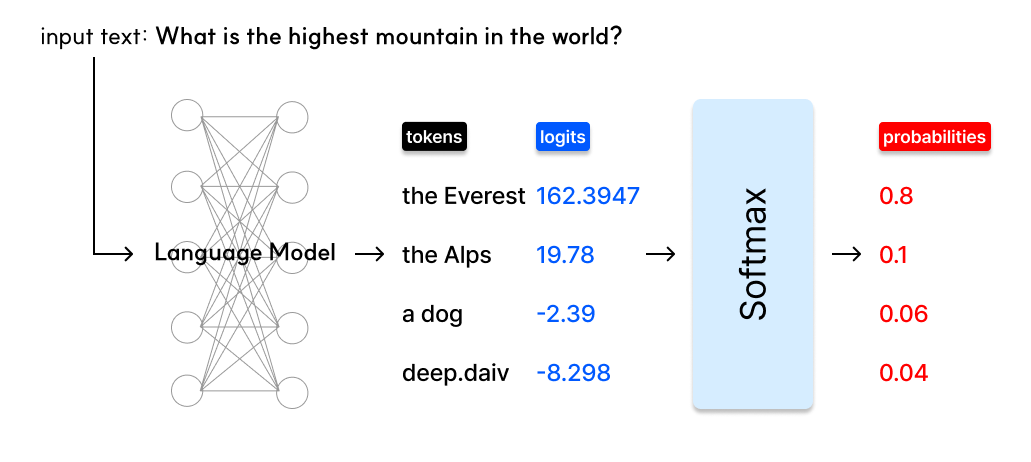
언어 모델의 디코딩 과정
출처: ⓒ deep daiv. |
|
|
위 예시에서 입력 텍스트에 대해 언어 모델이 예측한 토큰들의 Logit(로짓; 모델의 마지막 레이어를 통과한 직후의 원본 숫자)값들을 반환하면, Softmax Layer를 통해 Logit 값들을 확률(Probabilities)로 가공합니다. 그리고 이 확률에 따라 다음 출력 토큰을 결정하게 되는데, 이때 디코딩 전략이 사용됩니다. |
|
|
디코딩 전략은 크게 두 갈래로 나뉘는데요. 먼저 결정론적 방법은 확률분포에서 항상 가장 높은 확률의 토큰을 선택하는 방법으로, 다음 토큰을 예측할 때 확률이 높은 순서대로 출력하는 방법을 말합니다. 이렇게 출력하는 가장 대표적인 방법이 Greedy Search입니다.
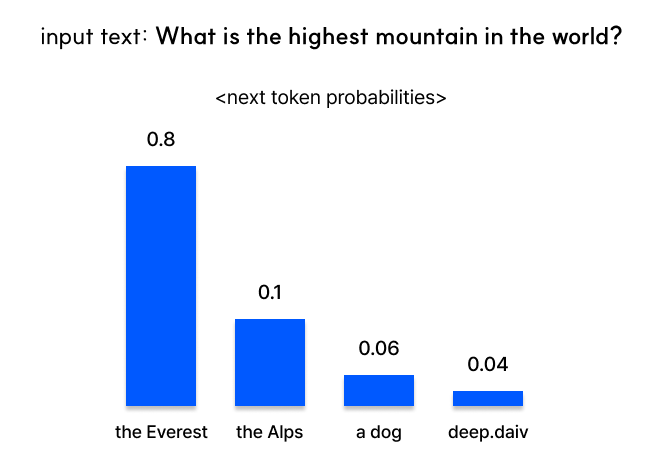
그다음으로, 확률적 방법은 확률 분포에서 나타난 확률에 따라 토큰을 무작위로 선택하는 방법입니다. 앞선 첫 번째 그림을 예시로 들어보자면, “the Everest”가 출력될 확률이 0.8, “a dog”이 출력될 확률이 0.046인거죠.
결정론적 방법인 Greedy Search를 사용한다면 모델을 몇 번 수행하느냐에 상관없이, 같은 질문에 대해서 항상 가장 높은 확률인 “the Everest”를 출력할 것입니다. 반면 확률적 방법을 사용할 경우에는 매우 낮은 확률임에도 “a dog”이 출력될 수도 있는 것이죠.
그렇다면 결정론적 방법이 성능이 더 우수한 게 아닌가, 하는 생각이 들 수 있습니다.
|
|
|
그러나 한 연구에 따르면, Open-ended 텍스트 생성(예: 대화형 AI)에서는 확률적 디코딩 방법이 결정론적 방법보다 더 나은 성능을 보입니다. Open-ended의 경우 정해진 정답이 없고 맥락에 따라 다양한 출력이 가능해서, 디코딩 전략에 있어서도 다양성을 고려하는 것이 중요하기 때문이죠. |
|
|
|
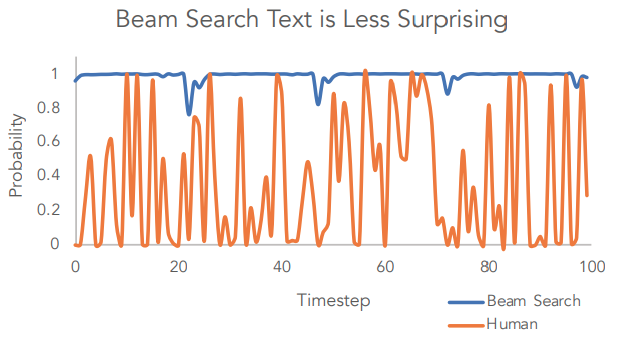
위 그래프는 같은 입력에 대해 결정론적 방법론(Beam Search)으로 출력한 텍스트와, 사람이 작성한 텍스트에서 토큰들의 확률을 비교했습니다. Beam Search로 디코딩 된 텍스트는 끝없이 반복을 하는 패턴을 보이는 반면, 사람이 작성한 텍스트는 확률의 변동성(Variance)가 더 크다는 점이 특징이에요. 따라서 사람과 비슷한 분포를 흉내 내기 위해 Open-ended 텍스트 생성에서는 확률적 디코딩 전략을 사용하는 것이 더 좋습니다.
|
|
|
대표적인 확률적 디코딩 방법인 Top-k 샘플링을 먼저 소개하려고 합니다.
Top-k 샘플링은 모델이 예측한 확률 분포 중 상위 k개의 단어만을 선택하여 샘플링한 이후, 원래의 Logit 값들에 대해 Softmax를 취해 얻은 확률분포를 바탕으로 다음 출력 토큰을 선택합니다. 따라서 k의 값에 따라 생성되는 텍스트의 다양성이 달라진다는 특징이 있어요. k가 작을수록 모델은 상위 k개의 확률이 높은 단어들만을 고려하게 되어, 출력되는 텍스트가 더 예측 가능하고 일관성 있게 됩니다. 반대로 k가 커질수록 선택할 수 있는 단어의 범위가 넓어지므로, 생성되는 텍스트는 더 창의적이고 다양한 표현을 담을 수 있습니다. k 값이 너무 커지면 텍스트의 품질이 떨어질 수 있기 때문에 적절한 값을 설정하는 것이 핵심입니다.
그러나, Top-k 샘플링은 Open-ended 텍스트 생성에서 가장 적합한 디코딩 방법은 아니에요. |
|
|
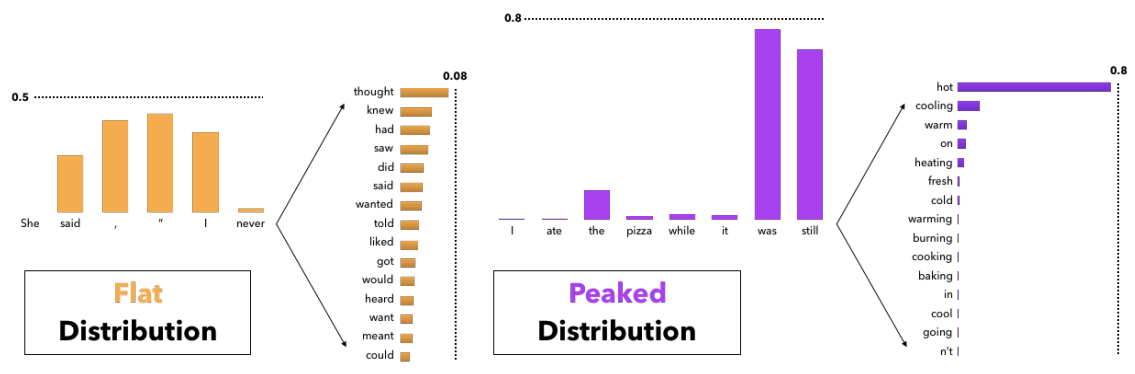
언어 모델이 다음으로 출력할 후보 단어의 확률 분포는 문맥에 따라 매우 다르게 나타날 수 있습니다. 위 그림과 같이, 일부 문맥에서는 상위 후보 토큰들이 고르게 분포되어 있을 수 있습니다. 이럴 경우 모델은 여러 적절한 단어를 선택할 수 있어요. 반면, 오른쪽과 같이 대부분의 확률 질량이 하나 또는 일부의 토큰에 집중되어 뾰족한 분포를 나타내기도 하죠.
(*확률 분포의 형태를 Temperature을 통해 조절하기도 하는데, 밑에서 더 말씀드리겠습니다.)
오른쪽 분포처럼 일부 토큰들의 확률이 매우 높은 경우, k값 이 작으면 밋밋하거나 일반적인 텍스트가 생성될 위험이 있습니다. 반대로 k 값을 너무 크게 설정하면 샘플링 시 Top-k 어휘 집합에 부적절한 후보 단어들이 포함되어, 텍스트 품질이 저하될 위험이 있어요.
|
|
|
이러한 문제를 해결하기 위해 Nucleus Sampling 기법이 등장했습니다.
Top-p 샘플링은 확률 분포에서 상위 p 확률을 가진 단어들만을 고려하여 샘플링 하는 방법이에요. |
|
|
Top-k 샘플링은 고정된 상위 k 개의 토큰을 샘플링하여 출력 후보군에 포함시켰다면, Top-p 샘플링은 상위 토큰들의 누적 확률이 p% 이상이 되도록 하는 토큰을 샘플링합니다.
|
|
|
예를 들어 p 값을 0.9로 설정하면, 모델은 확률이 상위 90%를 차지하는 단어들만을 선택하고 그 중에서 하나를 샘플링하게 됩니다. 따라서 ‘the Everest’와 ‘the Alps’가 다음에 출력될 토큰의 후보 집합에 포함되죠.
Top-k 방법은 확률 분포의 형태에 상관없이 샘플링 결과로 고정된 k 개의 토큰들을 가지게 되는 반면, Top-p는 확률분포의 형태에 따라 상위 p%에 속하는 토큰의 개수가 동적으로 변합니다.
즉, 후보의 수가 문맥에 따라 변화하며, 모델이 어휘의 확률 분포를 얼마나 신뢰하는지에 따라 선택할 수 있는 단어의 범위가 달라집니다. 이를 통해, Top-k 샘플링에서 하나의 고정된 k 값으로는 반영할 수 없는 어휘에 대한 신뢰 영역(confidence region)의 변화를 p 값으로 조정하며 잘 반영할 수 있습니다.
|
|
|
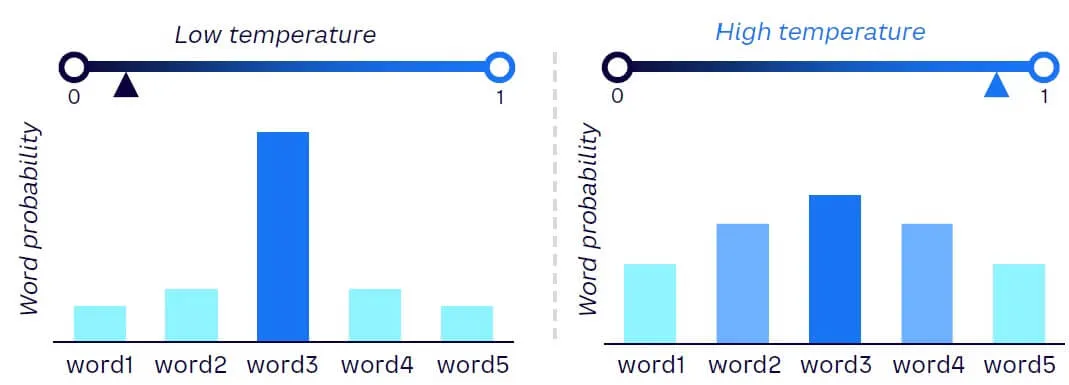
앞서 두 가지 확률적 샘플링 기법을 알아보았는데요. 샘플링 기법은 모델이 다음에 나올 단어를 고를 때, 확률 분포에서 어떤 단어를 선택할지를 결정하는 과정입니다. 반면, Temperature는 그전에 확률 분포 자체를 조정하는 역할을 합니다. Temperature 값을 높이면 확률 분포가 평평해져 다양한 단어를 선택할 확률이 커지고, 낮추면 특정 단어의 확률이 높아져 그 단어가 선택될 확률이 커집니다. 즉, Temperature는 샘플링 전에 확률 분포를 "조절하는" 역할을 합니다. |
|
|
출처: Generative artificial intelligence: Toward a new civilization?
Temperature 값이 낮을수록(0~1.0) 확률 분포가 뾰족해지고 모델은 높은 확률을 가진 단어를 선택하는 경향이 강해집니다. 따라서 생성되는 텍스트가 예측 가능하고 일관성 있는 결과를 도출합니다.
반대로, Temperature 값이 높을수록(1.0 이상) 모델은 상대적으로 낮은 확률을 가진 단어에도 더 많은 확률을 부여하게 되며, 이로 인해 더 다양한 선택을 하게 됩니다. 이로 인해 생성되는 텍스트가 창의적이고 예측할 수 없는 방식으로 변화하게 되며, 때로는 더 흥미롭고 독특한 결과를 얻을 수 있습니다.
|
|
|
오늘은 디코딩에 사용되는 샘플링 기법과 Temperature에 대해 알아보았습니다. ChatGPT API를 사용할 때나, 혹은 언어 모델을 튜닝할 때 자주 보던 설정값들인데요. 이번 뉴스레터를 준비하며 그 원리를 깊이 이해할 수 있어 저에게도 유익한 시간이었습니다. Temperature와 Top-p를 GPT-3가 출시되던 2020년부터 현재까지 꽤 오랫동안 사용해 오고 있는 것 같은데, 이를 대체할 만한 또 다른 샘플링 기법은 언제 도입될까요? 🤔
오늘도 읽어주셔서 감사합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|