확산 모델을 기반으로 하는 언어 모델, LLaDA를 소개합니다. # 81 위클리 딥 다이브 | 2025년 3월 5일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 확산 모델의 개념을 간단히 살펴봅니다.
- 다양한 언어 모델의 학습 방식을 비교합니다.
- 언어 모델에 확산 모델을 더한 LLaDA를 소개합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
2025학년도 수능 국어 영역에서 많은 수험생을 당황하게 만든 지문이 출제되었습니다. 바로 확산 모델(Diffusion Model)에 관한 내용이었는데, AI 기술에 익숙하지 않다면 다소 낯선 개념일 수밖에 없습니다. 이처럼 AI의 영향력은 예상치 못한 영역까지 확산하며, 이제는 수험생들이 마주하는 시험지에도 등장하게 되었습니다. |
|
|
확산 모델은 이미지에 섞인 잡음(Noise)을 예측하고 이를 제거하여 원본 이미지를 복원하는 방식으로 훈련됩니다. 먼저 원본 이미지에 점진적으로 잡음을 추가하면, 결국 형태를 알아볼 수 없는 상태가 됩니다. 그런 다음, 잡음이 섞인 이미지를 입력으로 주면, 모델이 이를 학습하고 점차 잡음을 제거하며 원본을 복원하는 과정을 거칩니다. 이렇게 잡음의 패턴을 예측하고 점진적으로 제거하는 과정에서, 학습된 이미지가 아닌 새로운 이미지가 생성되기도 하기 때문에 확산 모델은 생성 모델로 분류됩니다.
이러한 확산 모델은 그동안 주로 이미지 생성에 사용되었습니다. 그런데 최근 발표된 연구, Large Language Diffusion Models (Nie et al., 2025)에서는 언어 모델에도 확산 개념을 적용하려는 시도를 선보였습니다. 기존의 대형 언어 모델(LLM)은 대부분 Autoregressive(AR) 방식을 사용합니다. 지난 몇 년간 계속해서 발전하며 놀라운 성능을 보여줬지만, 본질적으로 다음 토큰 예측에만 의존하기 때문에 한계가 있다는 지적이 끊이질 않았는데요. 인간은 그런 식으로 언어를 이해하지 않는다는 이유 외에도, 성능 면에서도 계속해서 해결되지 않는 문제가 있었기 때문입니다. 그렇다면 확산 모델을 바탕으로 하는 언어 모델이라는 새로운 패러다임은 어떤 가능성을 보일 수 있을까요? |
|
|
논문에서 소개한 LLaDA(Large Language Diffuision with mAsking)는 확산 모델을 기반으로 동작하는 새로운 언어 모델입니다. 기존의 AR 모델이 다음 단어를 하나씩 예측하는 방식을 사용했다면, LLaDA는 문장의 일부를 무작위로 가리고(Masking), 이 가려진 부분을 한 번에 복원하는 방식으로 학습됩니다. 이런 개념은 기존의 BERT와 유사해 보이지만, BERT가 특정 비율의 단어를 고정적으로 가리고 예측하는 것과 달리 LLaDA는 확산 모델처럼 점진적으로 마스킹과 복원을 수행한다는 차이가 있습니다.
LLaDA의 학습과 추론이 어떻게 이뤄지는지 조금 더 살펴보기 전에, 기존의 언어 모델은 어떤 방식으로 작동했는지 간단히 되짚어 보겠습니다. AR 방식은 쉽게 생각해서 GPT의 작동 원리와 같다고 보면 됩니다. 이전 단어들이 주어졌을 때 이어질 단어가 무엇인지 맞히는 과정을 반복하며 학습하는 방식입니다.
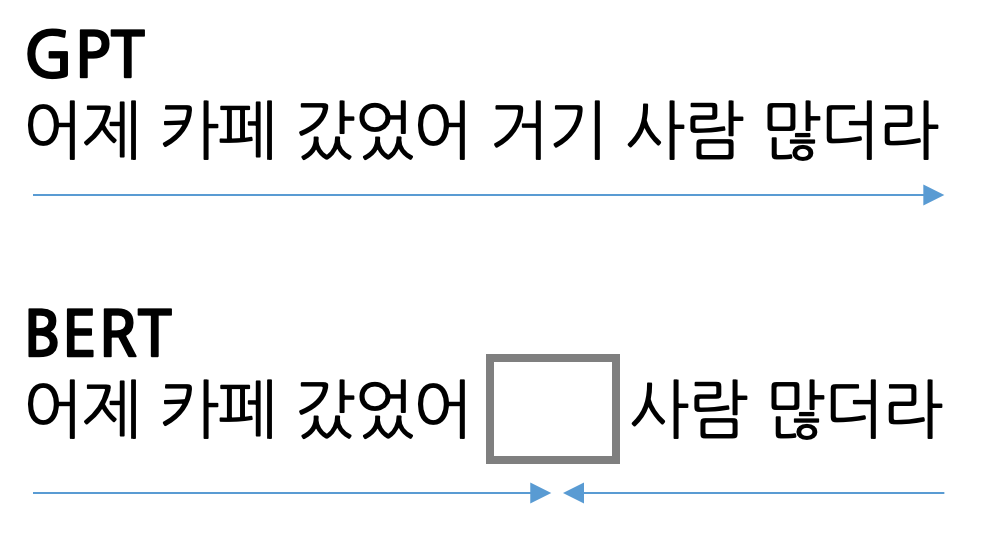
최근에 사용되는 언어 모델은 대부분이 AR 방식을 사용하기 때문에 BERT는 약간 생소할 수 있는데요. 단방향의 정보만을 사용하는 GPT와 다르게 BERT는 양방향 정보를 모두 사용합니다. 구체적으로는 원본 문장의 일부 단어를 가리고, 앞뒤 문맥을 바탕으로 가려진 단어가 원래 무엇이었는지 예측하는 방식을 통해 학습합니다. 두 모델의 학습 방식을 그림으로 나타내면 아래와 같습니다. |
|
|
GPT는 이어지는 단어를 반복적으로 예측하는 과정을 통해 학습하고, 추론 과정에서도 같은 방식으로 문장을 생성한다. 반면 BERT는 입력의 일부를 마스킹 처리하고, 마스킹 된 단어가 원래 무엇이었는지 예측하는 방식으로 학습한다. 출처: ratsgo’s NLPBOOK |
|
|
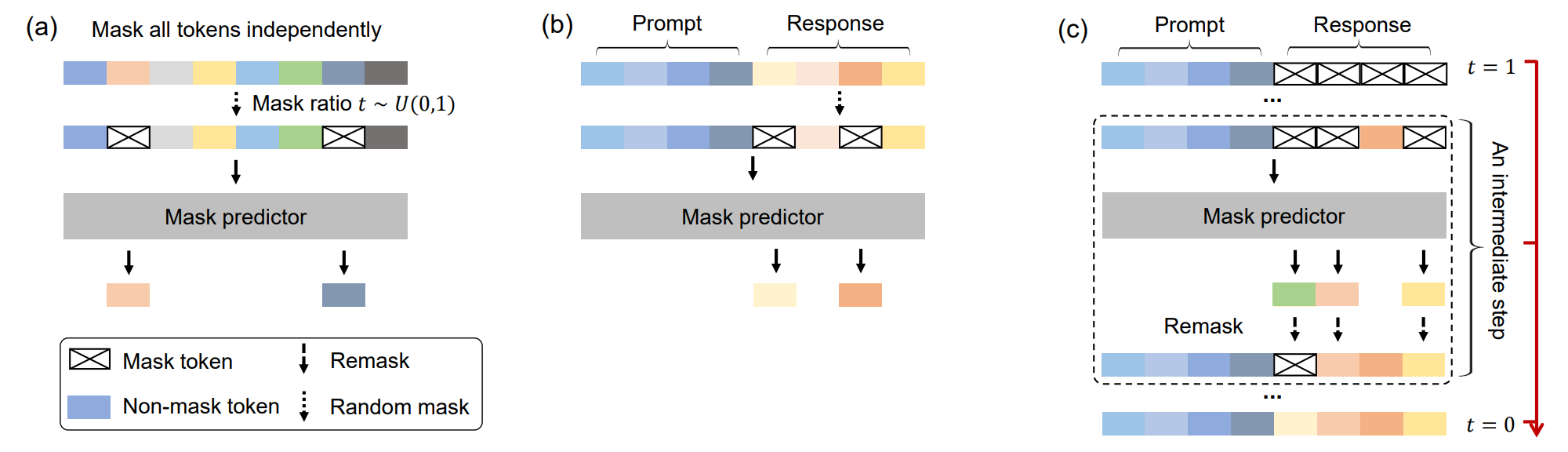
확산 개념을 바탕으로 하는 LLaDA는 입력 문장을 점진적으로 마스킹하고, 완전히 마스킹 된 문장을 다시 점진적으로 복원하는 과정을 통해 훈련됩니다. LLaDA는 BERT와 다르게 동적으로 마스킹 비율을 조정하고, 점진적으로 예측한다는 차이점 때문에 확장성을 갖출 수 있게 되었습니다. 또한 프롬프트(Prompt)와 응답(Response)으로 구성된 데이터가 주어졌을 때는, 응답 부분에만 마스킹 처리를 한 후 예측하는 방식을 통해 생성 모델의 특징도 갖게 됩니다. |
|
|
LLaDA는 몇 단계에 걸쳐 마스킹 된 부분을 예측할지 조정할 수 있으며, 매번 마스킹 된 토큰 전체를 한 번에 예측하기 때문에 기존의 LLM과 다르게 병렬성을 확보할 수도 있습니다. 하지만, 실제로는 한번에 예측을 수행하는 것보다 여러 차례에 걸쳐 응답을 예측하는 게 더욱 성능이 좋은데요.
위 그림의 (c) 부분을 보면 Remask라는 표현이 있습니다. 마스킹 된 토큰이 원래 무엇이었는지 한번에 예측한다고 해도 토큰마다 예측에 대한 확신의 정도(Confidence)가 다를 것입니다. 어떤 토큰은 원본을 예측하기 쉽고, 어떤 토큰은 그렇지 않을 수 있기 때문이죠. 그럴 경우 예측 정확도를 높이기 위해서 Confidence가 낮은 토큰을 다시 마스킹 처리하고 한번 더 예측합니다. 이런 과정을 반복하면 조금 더 품질이 높고 정확한 응답을 생성할 수 있습니다. |
|
|
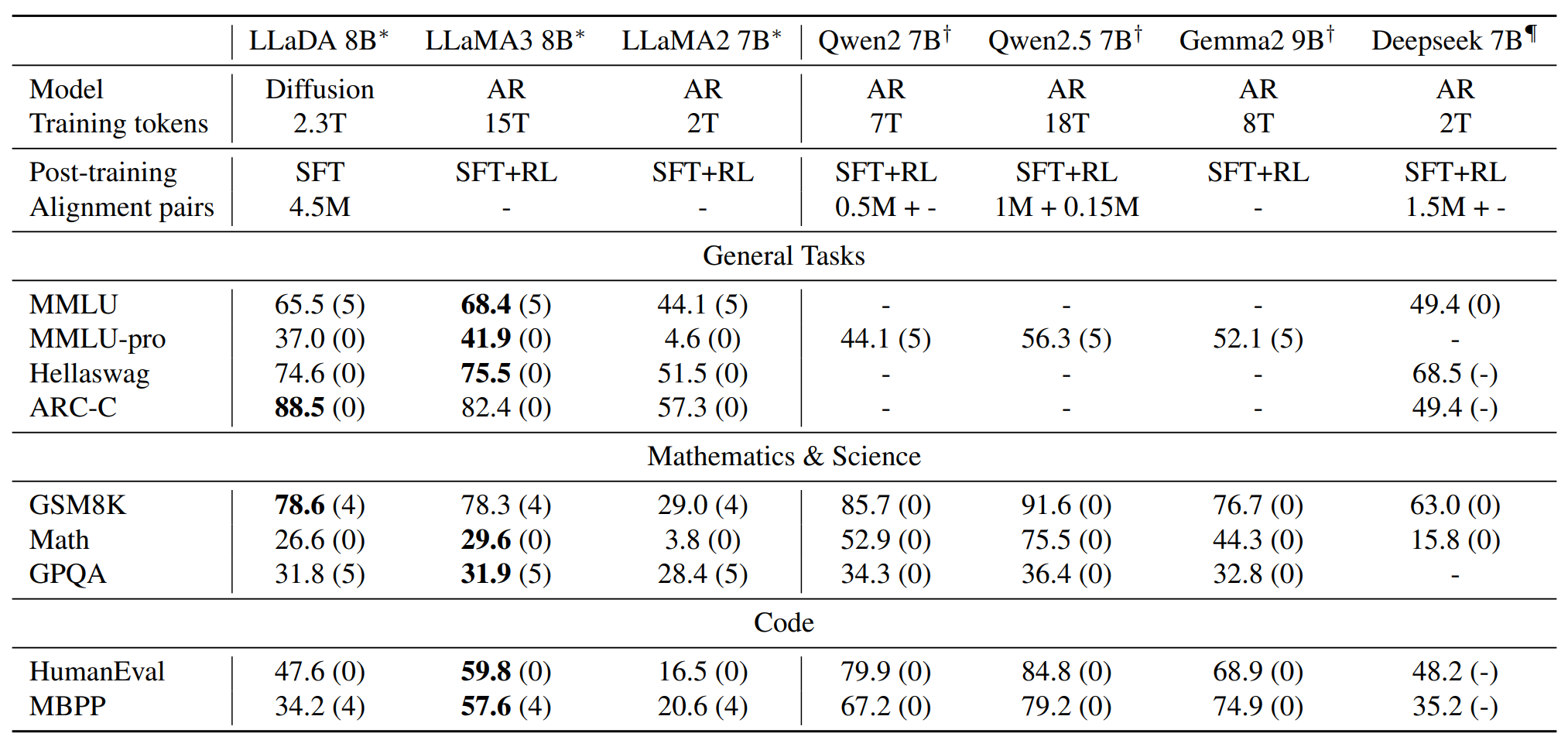
그렇다면 LLaDA는 실제로 기존의 대형 언어 모델과 비교해 어느 정도의 성능을 보일까요? 실험 결과에 따르면, LLaDA는 LLaMA 3 8B와 같은 강력한 LLM들과 비교해도 경쟁력 있는 성능을 보여줍니다. 특히, 문맥 내 학습(In-context Learning, ICL)과 지시 수행(Instruction Following) 능력에서 뛰어난 결과를 기록했습니다. 이는 확산 모델이 단순히 데이터를 복원하는 것이 아니라, 문맥적 의미를 더욱 정교하게 반영할 수 있다는 점을 시사합니다. |
|
|
|
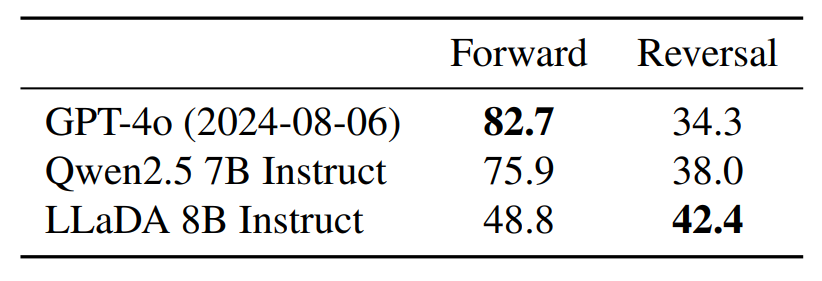
또한 LLaDA는 AR 방식의 언어 모델이 어려움을 겪던 역방향 추론(Reversal Reasoning)에서도 뛰어난 성능을 보였습니다. 예를 들어, 주어진 문장을 순방향이 아닌 역방향으로 예측하는 실험에서, LLaDA는 GPT-4o보다도 더 높은 성능을 기록했습니다. 이는 기존의 AR 모델이 단방향적인 예측 방식 때문에 역방향 문맥 이해가 어려웠던 것과 달리, LLaDA는 문장의 어느 부분에서든 유연하게 단어를 복원할 수 있기 때문입니다. |
|
|
지금까지 언어 모델의 발전은 Autoregressive(AR) 방식의 틀에서 벗어나지 못하고 있었습니다. 하지만 LLaDA는 확산 모델이라는 전혀 다른 접근 방식을 통해, 기존의 한계를 뛰어넘을 가능성을 제시합니다. 순차적인 예측에서 벗어나 더 자유롭게 문맥을 이해하고 생성하는 모델, 병렬 처리를 통해 더 빠르고 효율적인 학습이 가능한 모델인 LLaDA는 어쩌면 인간의 언어 사용 방식에 더 가까워진 모델일지도 모릅니다. 이제는 단순한 성능 향상만을 추구하는 것을 넘어, 언어 모델의 개념 자체를 다시 정의해야 할 시점이 온 듯합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|