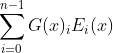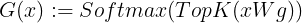MoE(Mixture of Expert)에 대해 알아봅시다. # 79 위클리 딥 다이브 | 2025년 2월 19일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- MoE의 발전 과정을 요약했습니다.
- MoE의 작동 원리를 정리했습니다.
- 어떤 작업에 MoE를 사용하는게 좋을지 살펴봅니다.
|
|
|
안녕하세요, 에디터 잭잭입니다.
MoE(Mixture of Experts)는 최근 대규모 AI 모델에서 활발히 활용되고 있는 아키텍처로, DeepSeek, Gemini, GPT-4 와 같은 최신 모델에서도 적용되고 있습니다.
규모의 법칙에 따라 모델의 규모가 커질 수록 성능이 좋아지지만, 모델의 파라미터 수가 늘어날수록 많은 계산을 필요로 하기때문에 추론 시간이 지연되는 문제가 있었죠. MoE는 여러 개의 전문가(Expert) 네트워크 중 일부만 활성화하여 연산을 수행하여 연산량을 줄이면서도 높은 성능을 유지할 수 있는 것이 특징입니다. |
|
|
1991년의 초기 MoE는 모든 전문가(Experts)에게 입력을 분배하는 방식이었어요. 이러한 방법을 Dense MoE라고 하는데요. 모델의 모든 전문가가 동시에 활성화되었으며, 각 전문가의 출력을 Softmax 가중치를 이용해 합산하는 구조였습니다. 그러나 당시에는 연산 효율성과 확장성의 한계로 인해 큰 주목을 받지는 못했어요.
2016년, Google이 Sparse MoE를 제안하며 MoE의 활용 가능성을 대폭 확장하였습니다. 기존 MoE 모델이 모든 전문가를 동시에 활성화했던 것과 달리, Sparse MoE는 입력마다 일부 전문가만 선택해 연산을 수행하는 방식을 도입해 연산량을 크게 줄이면서도, 높은 성능을 유지할 수 있도록 했습니다. 이를 통해 1370억 개의 파라미터를 가진 모델을 개발하면서도, 추론 단계에서 실제로 활성화되는 파라미터 수는 훨씬 적었기 때문에 모델을 효율적으로 운용할 수 있었어요.
최근 프랑스의 인공지능 기업 Mistral AI이 공개한 Mixtral 모델은 MoE 구조를 활용하면서도, 전문가들이 골고루 활성화되지 않았던 기존의 단점을 개선하며 화제가 되기도 했어요. |
|
|
MoE는 "전문가들의 집합"이라고 번역될 수 있는데, 여기서 말하는 ‘전문가(Expert)’는 모델 내에서 서로 다른 특성을 학습한 부분을 의미해요. 각 전문가는 특정 데이터 패턴을 학습하기 때문에, 전문가가 여러개 있다면 다양한 입력에 대해 최적의 결과를 도출 할 수 있습니다.
예를 들어, MoE 모델에는 아래와 가은 전문가들이 존재할 수 있어요.
- 수학 문제를 잘 푸는 전문가
- 자연어 이해를 잘하는 전문가
- 코드 분석을 잘하는 전문가
이처럼 각 전문가가 특정 데이터나 작업에 특화되어 있어, 입력이 들어오면 해당 문제를 가장 잘 처리할 수 있는 전문가가 활성화됩니다. 중요한 점은 모든 전문가가 동시에 활성화되는 것이 아니라, 입력에 따라 일부 전문가만 선택적으로 활성화된다는 것이에요. |
|
|
그렇다면, 어떤 전문가가 필요한지 모델이 어떻게 스스로 결정할까요?
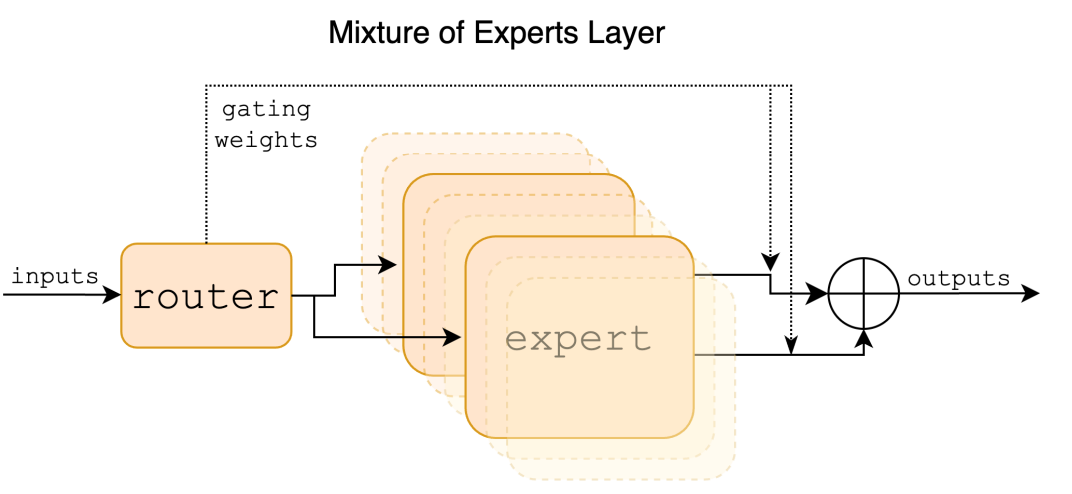
이 과정에서 핵심적인 역할을 하는 것이 바로 라우터(Router)입니다. 라우터는 입력 데이터의 특성에 맞춰 어떤 전문가를 활성화할지 결정하는 모듈로, 입력 토큰에 따라 가장 적합한 전문가를 판단해요. 라우터는 해당 전문가를 선택하여 연산을 수행합니다. 일반적으로 라우터는 모델의 앞쪽에 위치한 레이어에 배치돼요. |
|
|
|
조금 더 자세히 알아볼까요?
주어진 입력 x에 대한 MoE 모듈의 출력은 각 전문가 네트워크의 출력의 가중치 합으로 결정됩니다. 이 가중치는 바로 라우터의 출력에 의해 주어지는데요. n개의 전문가 네트워크 {E0, E1, ..., En−1}가 있을 때, 전문가 레이어의 출력은 아래와 같습니다. |
|
|
위 수식에서 G(x)_i는 i번째 전문가에 대한 라우터의 출력을 의미하고, E_i(x)는 i번째 전문가 네트워크의 출력을 나타냅니다. |
|
|
앞서, 모든 전문가가 아닌 일부 전문가만 활성화 되는것이 중요하다고 언급했는데요. 라우터 함수인 G(x)가 일부 전문가를 활성화하는 방법은, Top-K에 대해 소프트맥스를 취하는 방식이에요. 이때, 상위 K개에 속하지 않는 전문가를 -∞로 설정하여 활성화되지 않게 합니다.
또한 전문가의 개수인 n을 증가시키면서 K를 고정하면, 모델의 파라미터 수는 증가하지만 추론 단계에서의 계산 비용은 사실상 일정하게 유지할 수 있다는 특징이 있어요. |
|
|
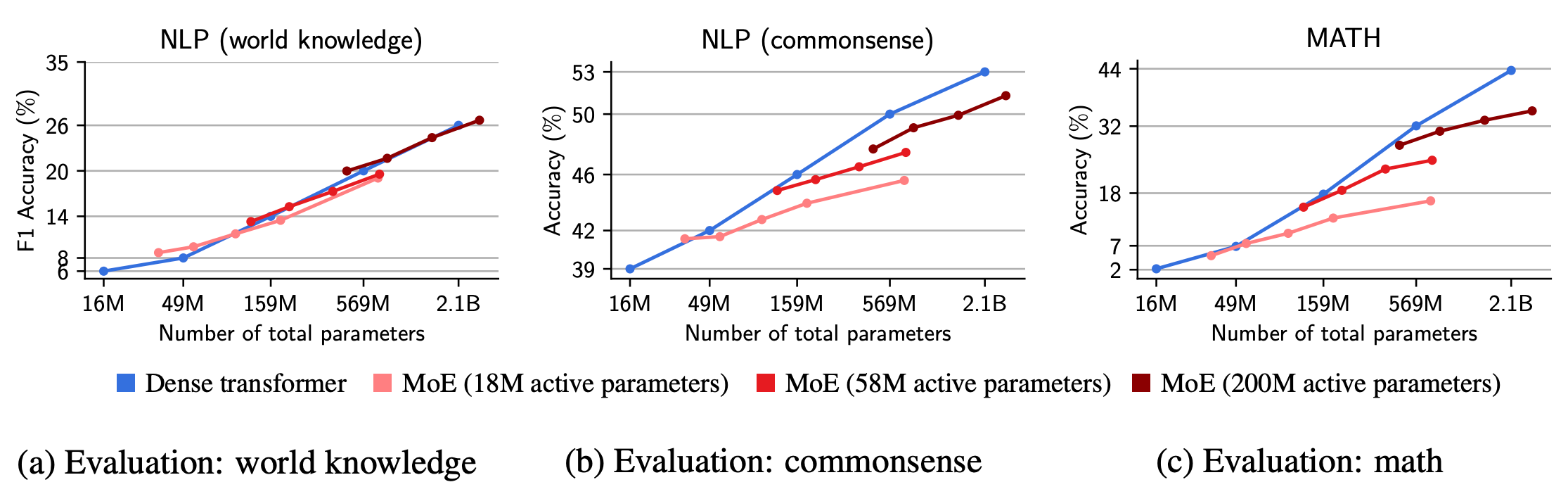
MoE는 인퍼런스 속도를 크게 향상시키는 장점이 있지만, 모든 분야에서 우수한 성능을 발휘하는 것은 아니에요. |
|
|
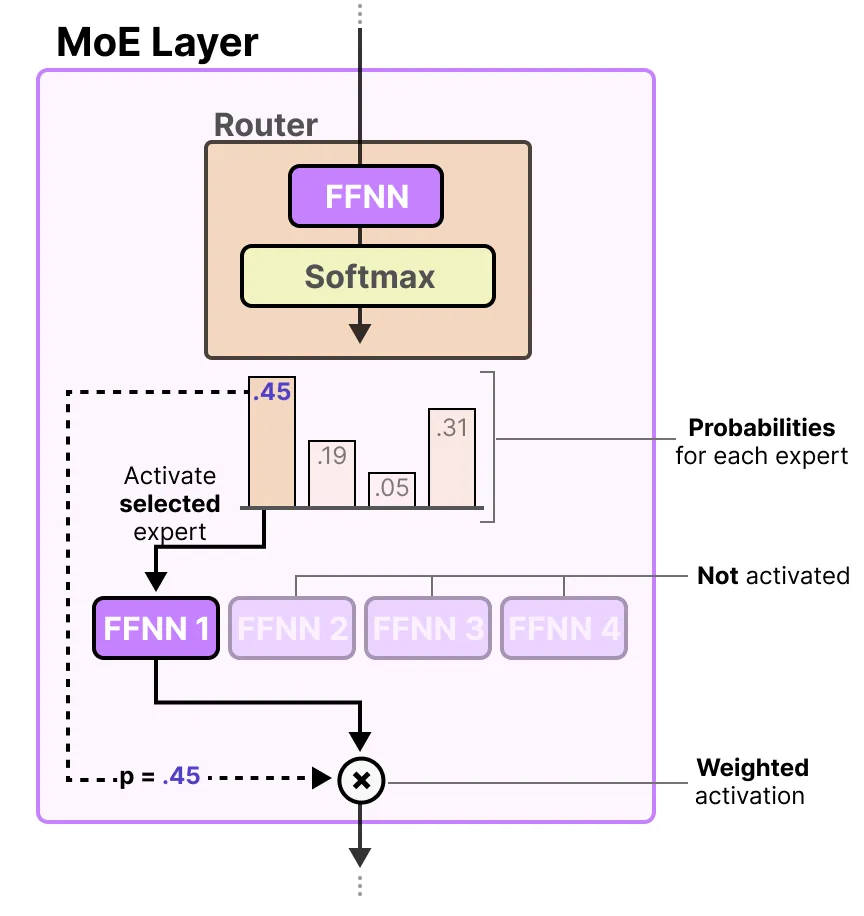
왼쪽은 MoE를 사용할 경우 VRAM에 로드해야 할 전체 파라미터이고, 오른쪽은 실제 사용되는 파라미터 수 이다.
출처 : A Visual Guide to Mixture of Experts (MoE)
MoE의 또 다른 중요한 특징은 모든 전문가를 메모리에 로드해야 한다는 점입니다. 비록 추론 단계에서는 일부 전문가만 활성화하지만, 모델을 실행하기 위해 모든 전문가를 메모리에서 로드해야 하므로, 상당한 VRAM이 필요해요. 따라서 VRAM이 제한적인 경우 밀집 모델(Dense model)이 더 적합할 수 있습니다.
따라서, 작업의 특성과 시스템 사양에 맞게 MoE를 적용하는것이 필요합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|