DeepSeek를 둘러싼 이슈와 DeepSeek 모델의 원리를 알아봅니다. # 77 위클리 딥 다이브 | 2025년 2월 5일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- DeepSeek가 주목 받은 이유를 알아봅니다.
- DeepSeek-V3와 DeepSeek-R1 모델의 특징을 정리합니다.
- DeepSeek를 둘러싼 이슈에 대해 살펴봅니다.
|
|
|
안녕하세요, 에디터 배니입니다.
지난주, 지금껏 고공행진을 달리던 NVIDIA의 주가가 급락했습니다. 중국의 AI 스타트업 DeepSeek가 OpenAI의 o1 모델의 성능을 능가하는 DeepSeek-R1 모델을 오픈 소스로 공개했기 때문입니다. 이 모델이 특별한 점은 성능보다도 모델을 개발하는 데 비용을 압도적으로 절감했다는 데 있습니다. DeepSeek에 따르면 모델을 개발하는 데 비용이 고작 80억 원밖에 들지 않았다고 하는데요. 만약 이 주장이 사실이라면 Meta의 Llama의 10분의 1, OpenAI의 ChatGPT에 비해 18분의 1 수준입니다. |
|
|
DeepSeek가 비용을 절감할 수 있었던 이유 중 하나는 보급형 GPU를 사용했기 때문입니다. 이 포인트에서 GPU 시장을 압도적으로 장악하고 있는 NVIDIA가 위기를 맞이한 것입니다. 고성능 GPU를 사용하지 않고도 o1 모델을 뛰어 넘는 성능의 모델을 개발할 수 있다면 더 이상 비싼 NVIDIA의 GPU만을 사용할 필요 없기 때문입니다.
하지만! 이른바 ‘DeepSeek 쇼크’ 이후 많은 전문가들은 비용을 과소 추정했을 것이라고 말합니다. 미국의 한 컨설팅 회사는 실제 추정 비용이 약 90배는 더 비쌀 것이라고 추정합니다. DeepSeek가 밝힌 비용은 단순히 시간당 2달러 기준으로 2개월 빌렸을 때를 가정한 것입니다. 그 속에 연구 비용, 데이터 처리 비용 등은 포함하지 않았습니다. 이번 사태로 NVIDIA에 위기가 찾아온 것처럼 보이기도 하지만, DeepSeek를 학습할 때 사용한 GPU 역시 NVIDIA의 H800 모델입니다. 결과적으로 NVIDIA의 보급형 GPU로 엄청난 모델을 개발했는데 NVIDIA의 주가가 떨어진 것이죠. (사실, NVIDIA의 GPU를 쓰지 않는 경우가 거의 없습니다.)
이런 논란과 무관하게 DeepSeek가 국제 사회에 미친 파급력은 엄청났습니다. Sora 이후로 세계가 AI 이슈로 들썩인 것은 오랜만인 듯한데요. 그렇다면 DeepSeek에 대해 알아보지 않을 수 없죠. 이번주 뉴스레터에서는 DeepSeek 모델의 원리와 이 모델을 둘러싼 이슈를 알아보도록 하겠습니다. |
|
|
DeepSeek이 SOTA를 달성할 수 있었던 이유: DeepSeek-V3 |
|
|
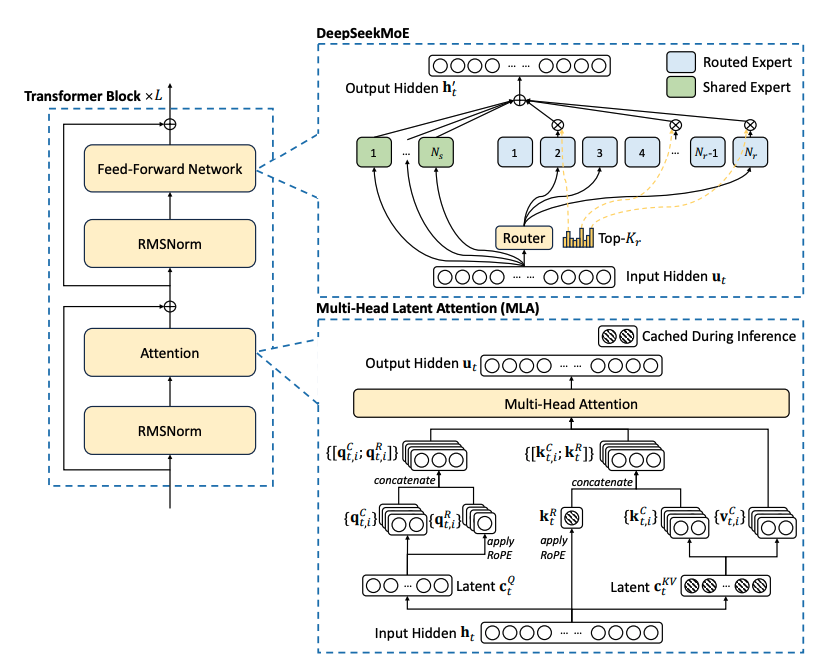
DeepSeek-R1이 세상에 갑자기 튀어나온 것은 아닙니다. 많은 연구 성과물이 그렇듯, DeepSeek 연구진도 꾸준히 모델을 개발해오고 있었는데요. 이번에 발표한 모델은 DeepSeek-V3 모델을 기반으로 강화학습을 통해 추론(Reasoning) 성능을 향상시킨 모델입니다. DeepSeek-V3모델은 작년 12월 말에 발표된 모델로, MoE(Mixture of Expert) 아키텍처를 적용한 LLM입니다. 일반적으로 MoE 아키텍처는 여러 개의 (작은) Expert 모델을 혼합하여 하나의 모델로 구축하고, 모델 추론할 때는 특정한 Expert만을 활성화합니다. |
|
|
위 그림에서 Transformer Block 안에 DeepSeekMoE가 포함되어 있는 것을 볼 수 있습니다. 기존 MoE 모델에서는 하나의 Expert에 다양한 종류의 토큰이 배정되면서 전문가가 여러 가지 정보를 동시에 학습해야 하는 문제가 있었습니다. DeepSeekMoE는 이를 해결하기 위해 전문가를 더 작은 단위로 세분화하여 각 전문가가 보다 특정한 지식에 집중할 수 있도록 설계됐습니다. 또한 기존 MoE 구조에서는 서로 다른 전문가들이 공통적인 지식을 중복하여 학습하기 때문에 비효율적이었는데요. DeepSeekMoE는 일부 전문가를 Shared Expert로 지정하여 항상 활성화되도록 만들어 효율적인 학습 구조를 만들었습니다.
DeepSeek-V3의 또다른 핵심 아키텍처 중 하나는 Multi-Head Latent Attention (MLA)입니다. 이는 추론 시 KV 캐시를 저차원 Latent Vector로 압축하는 방법론입니다. 덕분에 기존 MHA 대비 메모리 사용량을 줄이면서도 성능 저하 없이 효율적인 추론이 가능해졌습니다.
또한, DeepSeek-V3는 MoE 모델의 부하 불균형 문제를 완화하고자 Auxiliary-Loss-Free Load Balancing 기법을 도입했습니다. 기존 MoE 모델은 특정 전문가(Expert)에 토큰이 몰리는 현상을 방지하기 위해 Auxiliary Loss를 사용했지만, 이는 모델 성능 저하와 학습 복잡도 증가의 단점이 있었습니다. DeepSeek-V3는 Auxiliary Loss 없이도 부하를 균형 있게 조정하기 위해 각 전문가에 동적 Bias 값을 추가하여 토큰 분배를 자동 조정하는 방식을 적용했습니다. 이를 통해 불필요한 손실 없이 전문가 활용도를 높이고, 계산 자원의 효율성을 극대화할 수 있도록 최적화됐습니다. |
|
|
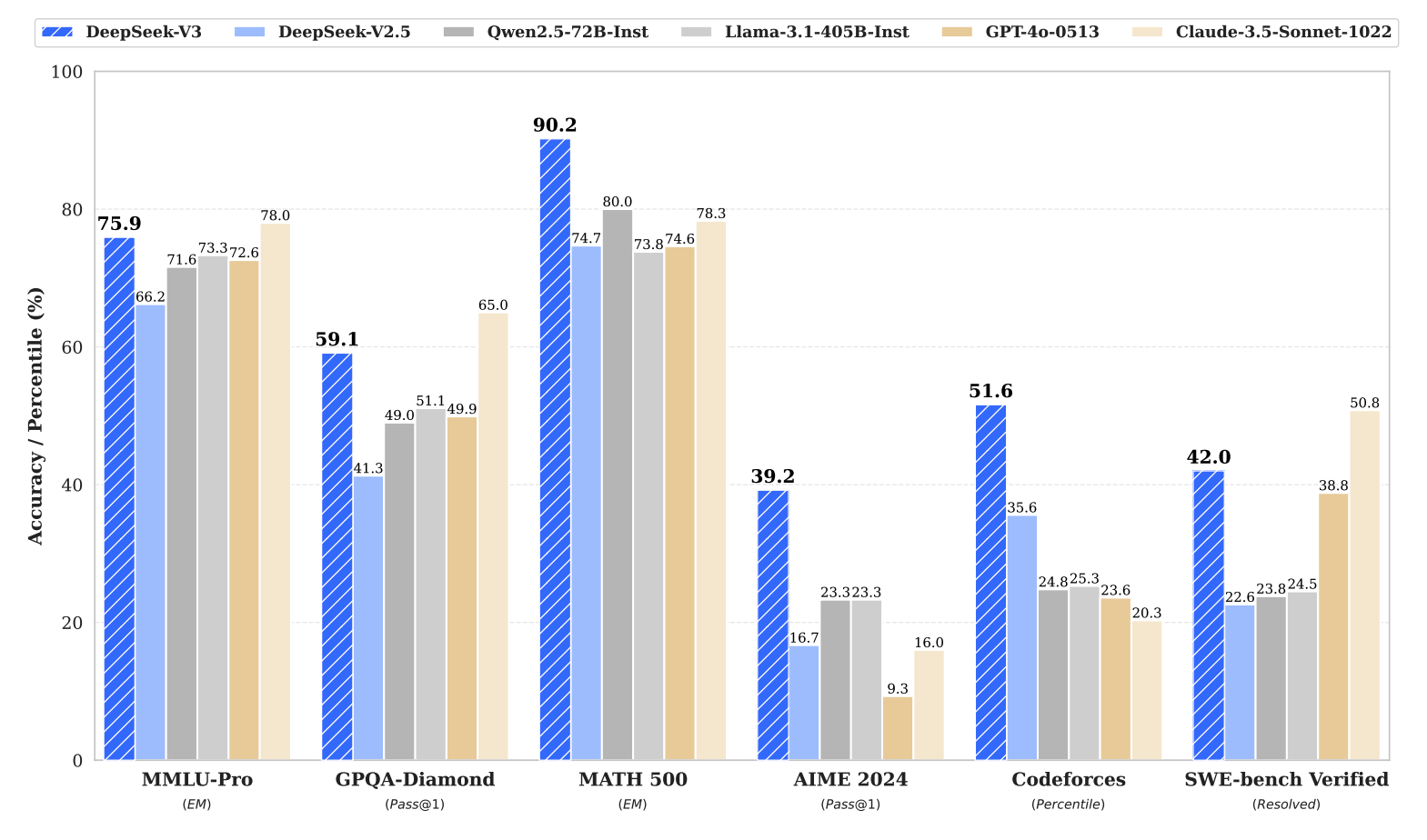
이렇게 학습된 DeepSeek-V3는 특히 수학, 코드, 논리적 추론 능력에서 뛰어난 결과를 기록했는데요. 대표적으로 MMLU(75.9), GPQA(59.1), MATH-500(90.2) 등의 점수를 기록하며, 오픈소스 모델 중 최상위권 성능을 보였습니다. DeepSeek-V3가 공개됐을 당시부터 GPT-4o나 Claude 3.5 같은 폐쇄형 모델(Closed Model)과도 견줄 만한 수준을 보여 더욱 기대를 모았습니다. |
|
|
DeepSeek는 V3 모델을 공개한 지 한 달만에 DeepSeek-R1을 선보였습니다. R1의 목표는 추론(Reasoning) 능력을 극대화하는 것이었죠. 기존 LLM은 많은 데이터를 학습해 지식은 방대하지만, 논리적으로 사고하고 문제를 해결하는 능력은 한계가 있었습니다. 특히 수학, 논리, 코딩 같은 분야에서 보다 깊이 있는 사고 과정이 필요했는데, 이 성능을 향상시키기 위해 DeepSeek는 V3를 기반으로 강화학습을 적용한 R1을 개발했습니다. 지도학습(SFT) 중심의 V3와 달리, R1은 논리적인 사고 과정을 스스로 학습합니다. 단순히 정답을 맞히는 것이 아니라, 왜 그렇게 생각하는지, 어떤 단계를 거쳐야 하는지를 강화학습을 통해 터득한 것이죠.
R1의 강화학습에는 GRPO(Group Relative Policy Optimization) 기법이 적용되었습니다. 기존 강화학습 방식에서는 별도의 평가 모델(Critic Model)이 필요했는데, 이 모델이 정책 모델(Policy Model)과 동일한 크기를 가져야 했기 때문에 연산 비용이 매우 컸습니다. GRPO는 이 문제를 해결하기 위해 그룹 내 상대적 보상(Relatively-ranked Rewards)만을 활용해 최적화를 진행하는 방식입니다. |
|
|
DeepSeek-R1이 보여준 Aha Moment
|
|
|
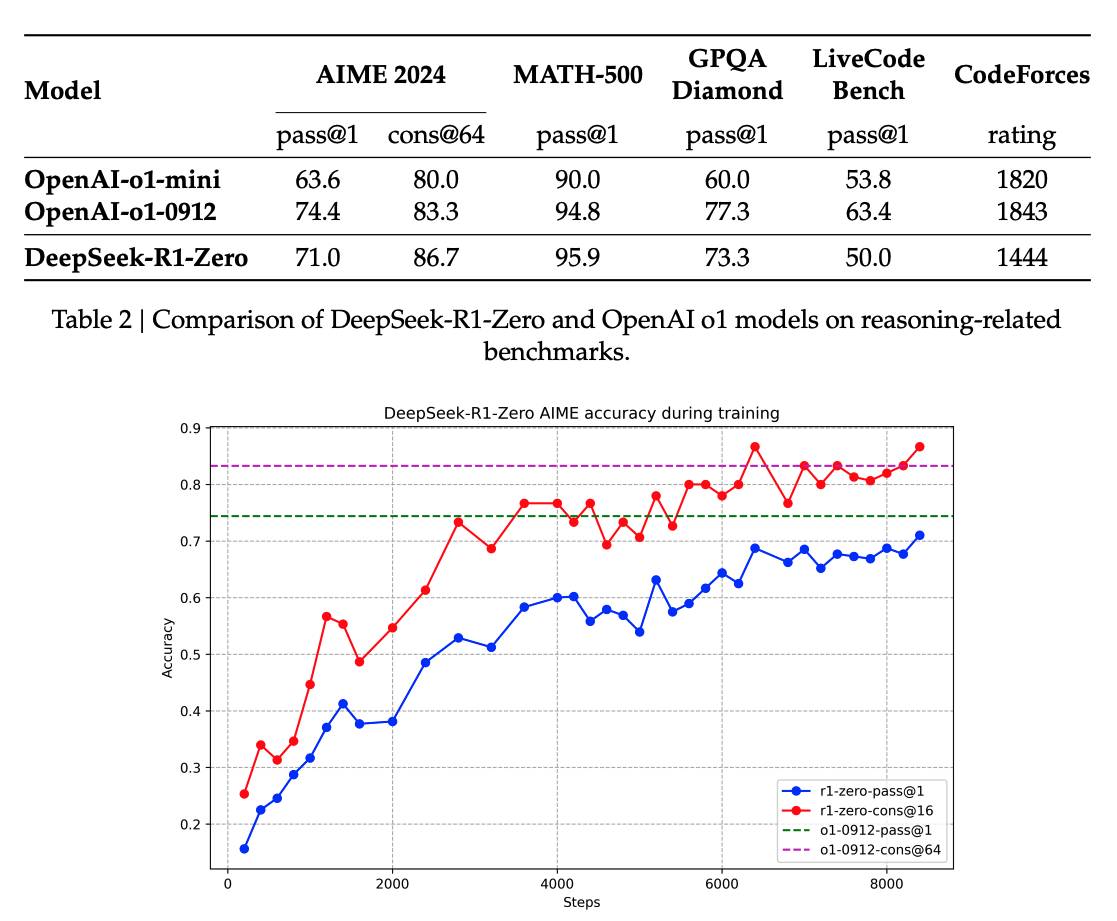
DeepSeek-R1을 학습하는 과정에서 특정 시점이 지나자 모델이 갑자기 더 깊이 있게 추론하기 시작하는 흥미로운 현상이 관찰됐습니다. 연구진은 이를 Aha Moment라고 부르는데, 이는 마치 사람이 문제를 고민하다가 갑자기 해결 방법을 깨닫는 순간과 비슷한 개념입니다. 연구진은 이 현상을 두고 그들 자신에게도 Aha Moment였고, 강화학습만이 가질 수 있는 정수라고 평가했습니다. 성능이 내내 안 좋다고 갑자기 이와 같이 추론하는 모습을 본다면 소름 돋을 것 같네요. 그렇다면 실제 성능은 어땠을까요? |
|
|
OpenAI o1의 성능을 넘어선 DeepSeek-R1
|
|
|
실제로 Aha Moment 이후 DeepSeek-R1의 성능은 급격히 향상됐습니다. 대표적으로 AIME 2024 테스트에서 Pass@1 점수가 초기 15.6%에서 71.0%로 상승했으며, 다수결(Majority Voting)을 적용하자 86.7%까지 도달했습니다. 이는 OpenAI o1-0912 수준의 성능과 맞먹는 결과입니다. |
|
|
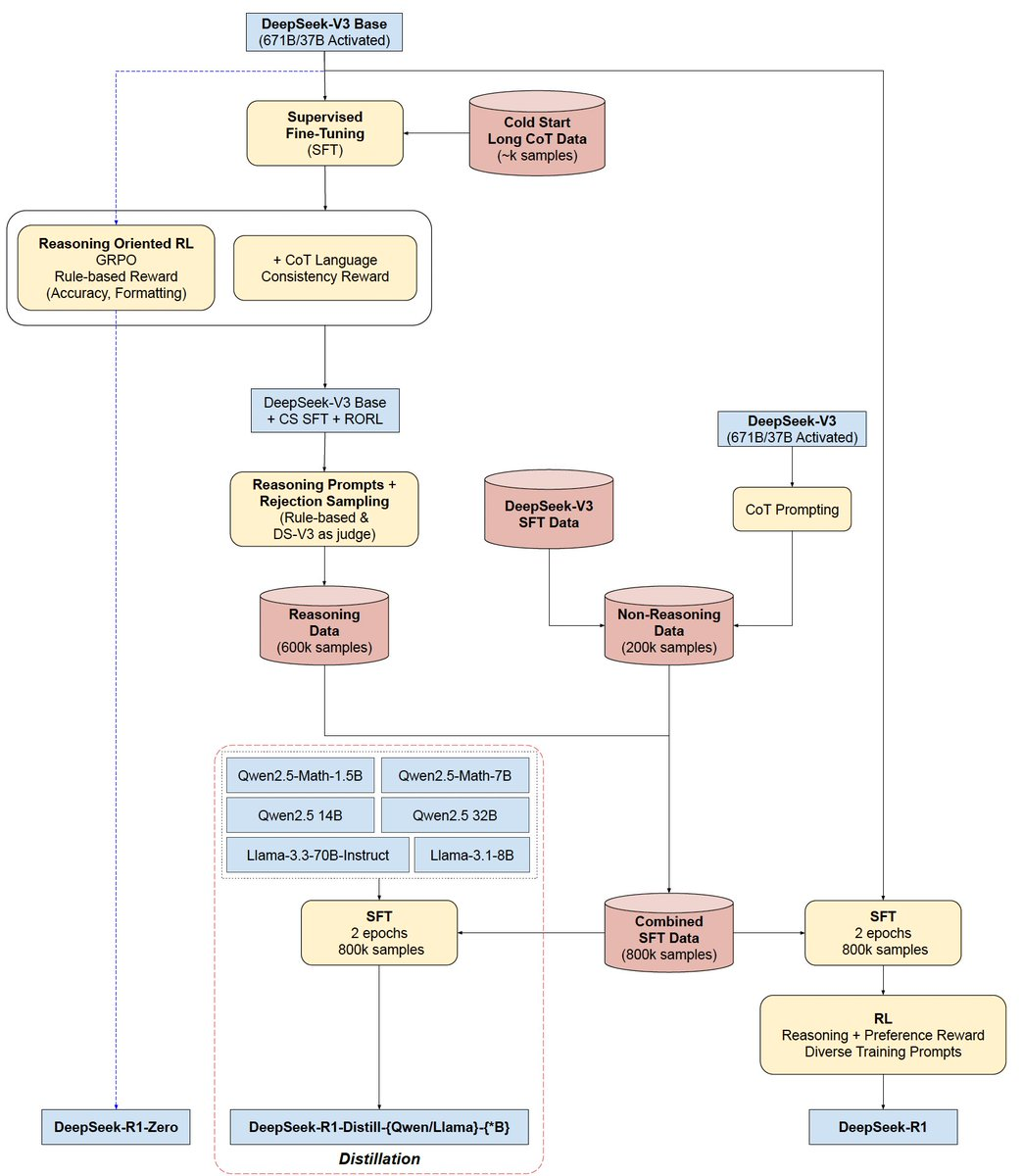
DeepSeek-V3부터 다양한 버전의 DeepSeek-R1 모델로 이어지는 로드맵
|
|
|
이렇게 학습된 모델은 다양한 버전으로 HuggingFace에 공개됐습니다. 그중 눈에 띄는 것은 Distill 모델입니다. 기존 모델은 671B(실제 활성 파라미터는 37B)이라 개인이 사용하기는 어렵지만 Distill 모델은 Qwen 기준 32B / Llama 기준 70B 모델로 상대적으로 가볍기 때문입니다. |
|
|
많은 논란을 낳은 DeepSeek에 대해 알아보았습니다. 아키텍처만 살펴봤을 때 사실 완전히 새롭다거나 특별한 모델은 아닙니다. 어떻게 보면 마케팅을 참 잘한 모델이라는 생각이 들기도 합니다.
그렇다면 DeepSeek는 일시적인 거품일까요? 꼭 그렇지만은 않습니다. 모델을 경량화하고, 저렴한 GPU에서 학습한 것은 사실이기 때문입니다. 게다가 DeepSeek의 모델은 오픈 소스(정확히는 Open Weight)로 공개되어 있습니다. 이 사실만으로도 연구자들 사이에서는 화제가 될 만한 가치가 있죠. DeepSeek 모델을 역설계하여 정말 모델이 재현(Reproduction)이 가능한지 실험해보고 있기도 하죠.
중국의 스타트업의 사례를 두고 우리나라에서도 기회의 발판으로 보고 있습니다. 물론, 기술적인 관점에서 의미 있기도 하지만 국제 정치 관점에서도 꽤 중요한 이슈입니다. AI 패권은 미국이 잡고 있다고 생각했는데, 이번 사태로 중국의 AI 기술력이 만만치 않다는 것이 입증되었기 때문입니다. 관심을 한 몸에 받고 있는 DeepSeek의 향후 발걸음이 기대되는 대목입니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|