자기 적응형 LLM(Self-adaptive LLM)이 무엇인지 살펴봅니다. # 75 위클리 딥 다이브 | 2025년 1월 22일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 인공지능의 학습 과정이 갖는 특징과 한계를 정리합니다.
- Self-Adaptive LLM의 개념을 소개합니다.
- Transformer^2 프레임워크를 살펴봅니다.
|
|
|
안녕하세요, 에디터 민재입니다.
적응은 생명체가 갖는 여러 놀라운 현상 중 하나입니다. 주변 환경에 따라 피부색을 바꾸는 동물부터 부상 후 잃어버린 기능을 인간의 뇌까지 그 사례는 매우 다양하죠. 이처럼 생명체는 끊임없이 변화하는 환경 속에서 살아가기 위해서 적응력을 발휘합니다. 인공지능도 어느 정도는 그러합니다. 사전 학습 과정에서 접하지 못한, 새로운 과제를 잘 수행할 수 있도록 스스로 가중치를 조정하는 파인 튜닝 과정이 있기 때문입니다.
하지만 인간과 인공지능의 적응에는 여전히 근본적인 차이가 존재합니다. 우리는 매 순간 주변 환경에서 들어오는 자극을 받아들이고, 이러한 경험을 축적하는 동시에 즉각적으로 판단 방식을 바꿉니다. 굳이 정의하자면, 실시간 재학습을 하는 셈이죠. 반면 인공지능은 사전에 주어진 데이터로 학습을 마친 후, 실제로 어떤 과제를 수행하는 추론 단계에 들어서면, 그 시점에서는 내부 가중치가 변하지 않습니다. 이러한 이유로 인공지능 모델은 인간보다 정적(Static)이라고 여겨집니다.
그래서 최근 들어 작업에 따라 동적으로 가중치를 조정하는 인공지능에 대한 연구가 다수 이뤄지며, Test(Inference) time Tuning과 같은 용어가 자주 눈에 띕니다. 과거에는 학습(Training)과 추론(Inference)이라는 두 단계가 명시적으로 구분됐지만, 이제는 추론 단계에서 가중치를 약간 조정하면서 인공지능이 유연하게 작업을 처리할 수 있게 하자는 것이죠.
그 중 특히 주목할 만한 연구는 Sakana AI에서 최근 발표한 연구인 Transformer^2: Self-adaptive LLMs (Sun et al., 2025)입니다. 논문에서는 자기 적응형 LLM(Self-adaptive LLM)이라는 개념을 정의하고, 이 목표를 달성하기 위해 Transformer^2(Transformer-squared)라는 프레임워크를 함께 제안하였습니다. 그렇다면 각각은 구체적으로 어떤 개념이며, 왜 중요할까요? |
|
|
사실 앞서 언급한 것과 같이, 인공지능에도 적응과 비슷한 개념은 이미 존재합니다. 가중치를 조정하는 모든 과정이 그에 해당합니다. 다만, 인공지능이 환경에 적응하는 과거의 방식에 문제가 있었기 때문에 대안이 필요했을 뿐입니다.
인공지능의 학습 과정은 크게 두 가지로 구분됩니다. 첫째는 분야와 관계없이 전반적으로 사용할 수 있는 방대한 지식을 학습하는 단계인 사전 학습(Pre-training)입니다. 그다음으로는 조금 더 세부적인 분야의 과제를 전문적으로 수행할 수 있도록 학습하는 단계인 사후 학습(Post-training)입니다.
사전 학습 단계에서는 천문학적인 컴퓨팅 자원을 투자하여 일반적인 목적으로 사용할 수 있는 인공지능을 구축합니다. 그리고 사후 학습 단계에서는 그보다 훨씬 적은 자원을 통해 특정 분야의 전문가처럼 동작하는 인공지능을 만들고자 합니다. 문제는 그럼에도 불구하고 사후 학습에 필요한 자원이 적지 않다는 점입니다. 이런 문제를 해결하기 위해 인공지능 전체를 학습하는 대신 일부만 효과적으로 학습하는 방법인 PEFT(Parameter-Efficient Fine-Tuning)가 제안되었으나, 이런 방법도 여전히 메모리 문제에서 완전히 자유롭진 못합니다.
Self-adaptive LLM은 약간의 파인 튜닝이 필요하긴 하지만, LoRA와 같은 기존의 PEFT 방법론보다 여러 방면에서 효율적이며, 추론 과정에서 사용자의 입력에 따라 유연하게 대응할 수 있다는 장점까지 갖습니다. Self-adaptive LLM은 Transformer^2라는 프레임워크를 바탕으로 구현되는데, 기술적인 내용을 파헤치기 전에 어떤 흐름으로 작동하는지 먼저 살펴보겠습니다.
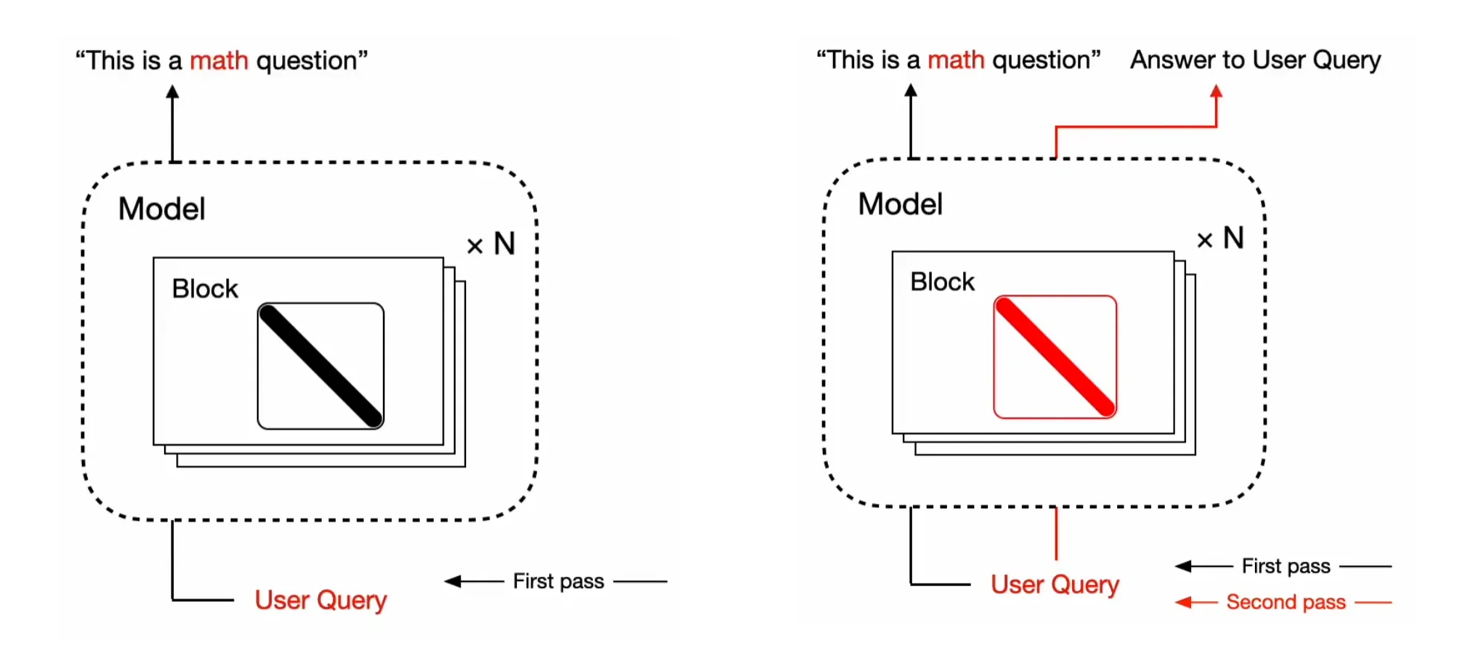
Transformer^2 프레임워크 내에서 LLM의 추론은 아래 그림과 같이 두 단계로 구성됩니다. 먼저 사용자의 입력이 들어오면, 질문의 유형을 파악합니다. 그리고 질문의 유형에 따라 LLM의 가중치를 동적으로 조정합니다. 여기까지만 보면 그리 특별할 게 없어 보입니다. 하지만, 이 연구의 의의는 Transformer^2 프레임워크의 학습 단계에서 더 자세히 드러납니다. |
|
|
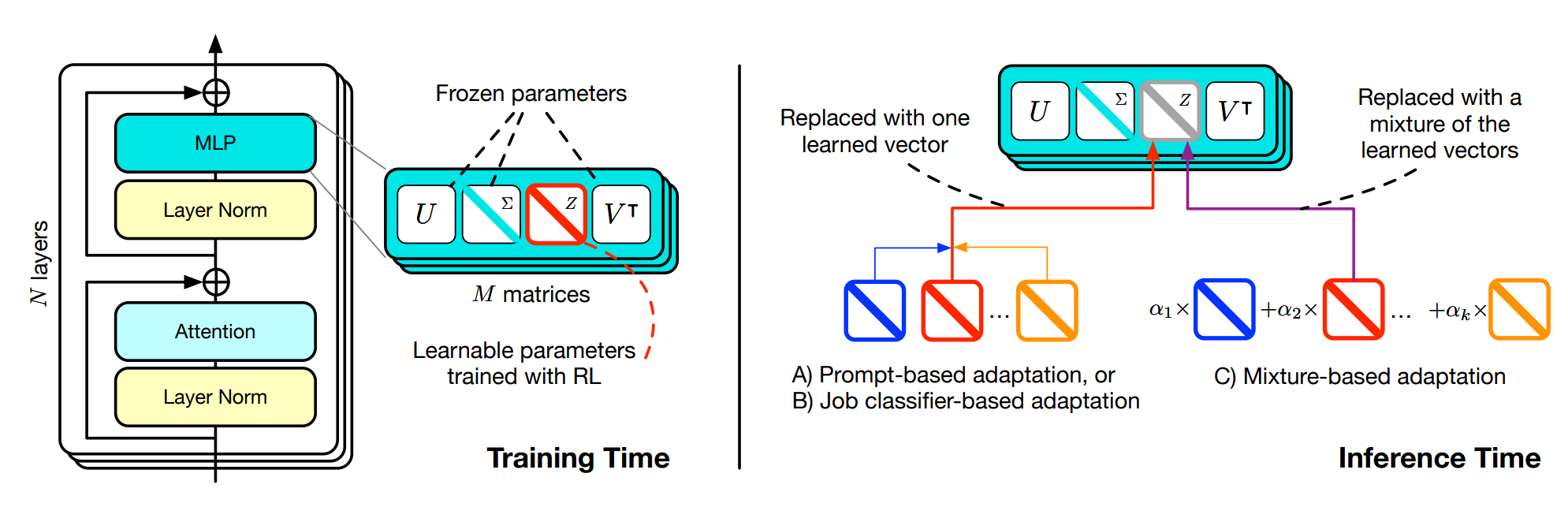
결국 추론 단계에서 상황에 맞게 가중치를 조정하기 위해서는, 사전에 교체할 가중치를 학습하고 저장해야 합니다. 이를 위해 연구진은 특잇값 파인 튜닝(Singular Value Fine-Tuning, SVF)이라는 개념을 도입합니다. SVF는 특잇값 분해(Singular Value Decomposition, SVD)라는 수학적 개념을 기반으로 하는데, 이를 먼저 간단히 알아보겠습니다.
SVD를 활용하면 가중치 행렬 W는 U, Σ, V^T라는 세 개의 행렬로 분해할 수 있습니다. 이때 U와 V는 직교 행렬이며 Σ는 r개의 특잇값으로 구성된 대각 행렬입니다. 이 개념이 중요한 이유는, 딥러닝 모델이 입력 x를 받고 가중치 행렬 W를 곱해서 출력 y를 생성하는 과정을 다른 시각으로 바라볼 수 있게 해주기 때문입니다. SVD를 활용하면 행렬의 각 부분이 출력을 형성하는 데 기여하는 정도를 파악할 수 있게 해주고, 결국 중요한 정보가 무엇인지를 알 수 있게 됩니다.
결국 Transformer^2 프레임워크의 학습 단계에서는 특잇값만을 학습해서 특정 태스크에 대한 전문성을 높이는 것을 목표로 합니다. 게다가 LLM은 이미 사전 학습 단계에서 필요한 대부분의 정보를 학습했다는 사실이 기존의 연구에서 밝혀지며, 결국 중요한 건 파인 튜닝이 아니라, 특정한 작업을 수행할 수 있도록 유도하는 과정임이 지적되기도 했습니다.
이 과정을 그림으로 나타내면 아래와 같습니다. 그림의 왼쪽 부분을 보면, 학습 단계에서는 사전 학습된 LLM의 가중치 행렬 중 특잇값만을 학습합니다. 이어서 오른쪽 부분의 추론 단계에서는, 입력에 따라 적절한 벡터를 찾아 가중치를 조정하여, 태스크에 따른 성능을 유연하게 개선할 수 있습니다. |
|
|
SVF의 또 한 가지 독특한 점은 강화 학습을 사용한다는 점입니다. 일반적으로 LLM의 학습 데이터는 사용자의 입력이 주어지면 그에 대한 대답이 줄글로 작성된 형태를 보입니다. 하지만 논문에서 채택한 학습 방식은 단순히 입력과 그에 대한 단순한 정답만을 필요로 해서, 훈련에 사용할 데이터셋을 구성하기도 쉽고, 학습 효율성도 높다는 장점이 있습니다.
예를 들어, LLM이 수학 문제를 풀도록 훈련할 때를 생각해 보겠습니다. 기존에는 문제와 풀이 과정이 모두 포함된 데이터셋이 필요했지만, SVF를 위해서는 단순히 문제에 대한 답만 있으면 데이터셋을 구성할 수 있습니다.
이처럼 Transformer^2 프레임워크를 사용하면 SVF라는 학습 방법론을 바탕으로 기존의 PEFT 방법론보다 효율적으로 인공지능 모델을 훈련할 수 있습니다. 게다가 추론 단계에서는 주어진 태스크에 적응하여 높은 성능을 발휘할 수도 있습니다. 과거에는 학습과 추론이 명시적으로 구분되었고, 각 태스크에 따라 다른 인공지능 모델을 필요로 했습니다. 하지만 이제는 상황에 맞게 LLM이 스스로 가중치를 조절하고, 마치 생명체와 같이 적응을 하는 양상을 보입니다.
|
|
|
최근 들어 유독 자주 등장하는 키워드가 있습니다. 바로 추론(Reasoning)입니다. Large Language Model은 이제 Large Reasoning Model로 나아가고 있습니다. 인공지능이 마치 생명체와 같이 상황에 따라 적절한 판단을 내리고, 그에 따라 어떤 행동을 해야 할지를 결정하는 일련의 추론 과정을 거친다고 인정받은 셈입니다.
OpenAI의 연구자인 Noam Brown의 트윗에서도 드러나듯이, 이제 LLM 연구는 LLM의 추론 과정을 어떻게 최적화할지에 초점이 맞춰져 있는 듯합니다. 실제로 학습이 아닌 추론 단계에서 얼마나 많은 컴퓨팅 자원을 사용하느냐에 따라 같은 모델의 성능도 크게 달라질 수 있다는 연구도 활발히 이뤄지고 있습니다.
앞서 언급한 것과 같이 사전 학습된 LLM은 이미 많은 지식을 학습했고, 중요한 건 실제로 작업을 수행하는 단계에서 사용할 지식을 잘 선별하는 능력입니다. 그리고 그게 바로 추론 과정을 최적화하는 방법입니다. 새 해가 밝음과 동시에 LLM 연구는 새로운 국면을 맞이하고 있습니다. 그리고 또 다른 새해가 찾아올 때, 우리가 마주할 인공지능은 어떤 모습을 하고 있을까요? |
|
|
🧑💻제10회 deep daiv. 오픈 세미나 👩💻 |
|
|
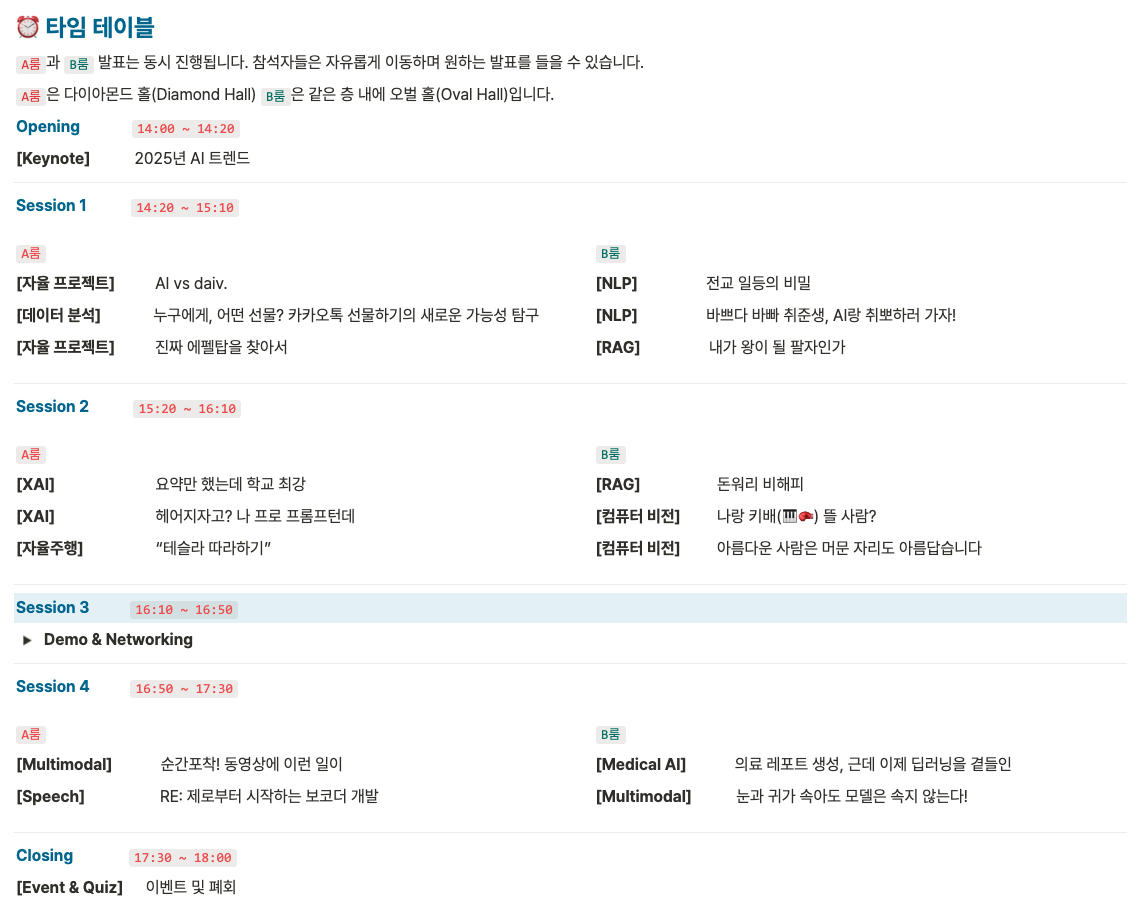
🥳 <제10회 deep daiv. 오픈 세미나> 개요
행사 일시 | 2025년 1월 25일(토) 오후 2시 - 6시
행사 장소 | 하이서울유스호스텔 다이아몬드홀 (B1F)
참가 대상 | 인공지능에 관심 있는 누구나
초대 인원 | 선착순 50명
초대 마감 | 1월 23일(목) 오후 7시 (🚨 선착순 조기 마감될 수 있습니다.)
참가 비용 | 10,000원
|
|
|
오는 25일 토요일 오후 2시에 제10회 deep daiv. 오픈 세미나가 개최됩니다. 다이브 팀원들이 준비한 총 16개의 AI 프로젝트와 함께 다양한 데모를 즐겨보실 수 있는 기회입니다. 세미나에 참여하시는 모든 분께는 고퀄리티 노션 발표 자료를 공유드립니다. 독자 여러분의 적극적인 참여 바랍니다! |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|