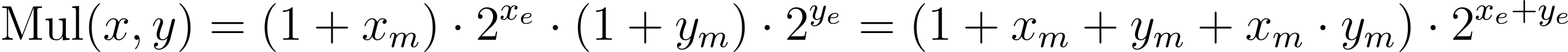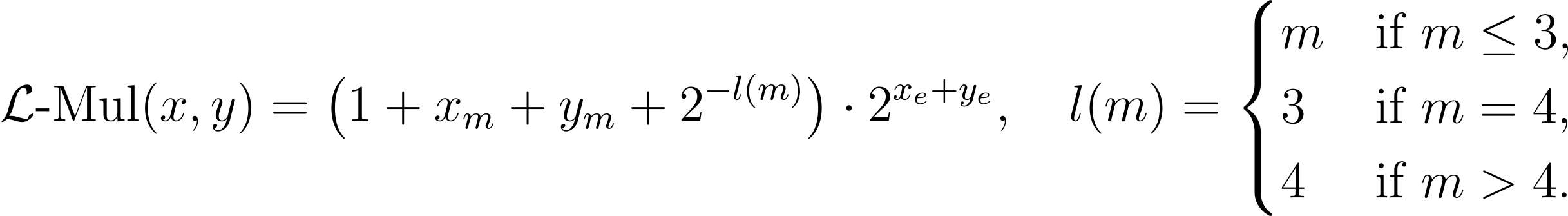인공지능의 에너지 효율을 획기적으로 높이는 알고리즘 L-mul을 소개합니다. # 62 위클리 딥 다이브 | 2024년 10월 23일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 인공지능 연구로 인해 발생하는 에너지 문제에 대해 논의합니다.
- 데이터의 형태와 연산의 종류에 따른 복잡도와 에너지 소모량을 정리합니다.
- 인공지능의 에너지 효율을 획기적으로 높이는 알고리즘 L-Mul을 소개합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
인공지능은 많은 분야에서 가능성을 입증하며 전 세계의 기대를 모으고 있지만, 동시에 많은 우려를 낳기도 했습니다. 최근 여러 매체에서 중점적으로 다뤄지는 윤리 문제가 그중 하나이죠. 이 문제도 물론 중요하지만, 곧 직접적으로 인류에게, 나아가 지구 전체에 큰 영향을 미칠 수 있는 문제도 있습니다.
바로 환경 문제인데요, 이는 지속적으로 지적되고 있는 만큼 우리가 의식하는 것 이상으로 심각한 문제입니다. 인공지능 연구와 관련된 환경 문제는 다양한 차원에서 발생합니다. 인공지능 학습에 사용할 데이터를 관리하기 위한 인프라를 구축하는 과정에서 발생하는 문제, 물이나 전기처럼 인공지능을 운용하는 과정에서 소비되는 다양한 형태의 자원과 관련된 문제 등이 있습니다. 미국 에너지 관리청(EIA)은 2023년 기준, ChatGPT 서비스를 운용하는 데는 매일 564MWh의 전력이 사용되었는데, 이는 약 18,000가구가 하루에 사용하는 전력량과 동일한 양이라고 합니다.
환경 문제 중에서도 특히 에너지 문제에 대해서는 인공지능 분야에서 이미 많은 논의가 이뤄지고 있습니다. OpenAI의 CEO인 샘 올트먼은 미래의 AI의 향방은 에너지 혁신에 달려 있다고 말하기도 했으며, 이 외에도 인공지능이 발전하는 데 가장 큰 걸림돌은 다름 아닌 에너지일 것이라는 주장도 빈번히 제기되고 있죠.
이처럼 에너지 문제 해결이 시급한 상황에서 최근 흥미로운 연구가 발표되었습니다. BitEnergy AI는 Addition is All You Need for Energy-efficient Language Models (Luo and Sun, 2024)라는 논문을 통해 딥러닝 모델의 연산 과정에서 사용하는 에너지를 획기적으로 줄이는 방법을 제안하였습니다. 논문에서는 부동 소수점(Floating Point, FP) 연산을 정수형(Int) 연산으로 근사하는 방법을 통해 딥러닝 모델의 추론 과정에서 사용하는 전력량을 최대 80%까지 절약할 수 있다고 하였는데요, 그 원리가 무엇인지 알아보겠습니다. |
|
|
먼저 컴퓨터가 숫자를 표현하는 방식을 간단히 살펴보겠습니다. 컴퓨터는 이진법을 기반으로 작동하며, 모든 정보를 0과 1의 값을 갖는 비트(Bit)로 표현합니다. 이런 방식은 정수형 데이터를 표현하는 데는 문제가 없지만, 소숫점을 포함할 경우 이야기가 달라집니다. 고정된 비트 수는 소수점을 완벽하게 표현하기 어렵기 때문인데요, 이를 해결하기 위해 부동 소수점(Floating Point)이라는 방식이 도입되었습니다.
예를 들어 32개의 비트를 사용하여 소수를 표현하는 방식인 FP32는 IEEE 754 표준을 따라 다음과 같이 숫자를 표현합니다. |
|
|
|
32개의 비트 중 첫 비트는 부호 비트(Sign Bit)로, 숫자가 양수인지 음수인지를 표시합니다. 그다음 8개의 비트는 지수(Exponent Width)로 소수점의 위치를 결정하며 매우 큰 수나 작은 수를 표현할 수 있도록 합니다. 나머지 23개의 비트는 가수(Mantissa 또는 Fraction)로, 실제 유효 자릿수를 나타냅니다. 가수는 숫자의 정밀도를 결정하는 요소입니다. |
|
|
앞서 살펴본 내용을 데이터 타입에 따른 연산 복잡도와 에너지 관점으로 확장해 보겠습니다. 데이터에 대한 연산은 크게 덧셈과 곱셈이 있습니다. 일반적으로 곱셈은 덧셈에 비해 복잡하게 작동하고, 그 과정에서 사용되는 에너지 또한 더 많습니다. |
|
|
데이터의 형태, 정밀도, 연산의 종류에 따라 소모되는 에너지
출처: Addition is All You Need for Energy-efficient Language Models (Luo and Sun, 2024)
n개의 비트로 표현되는 정수 데이터의 덧셈은 O(n)의 복잡도를 갖습니다. 반면 부동 소수점의 곱셈 과정에서는, 지수 부분 덧셈, 가수 부분 곱셈과 더불어 반올림(Rounding)이 수행됩니다. e와 m이 각각 지수와 가수를 표현하는 데 사용하는 비트 수라면, 지수 비트의 덧셈은 O(e), 가수 비트의 곱셈은 O(m^2)의 복잡도를 갖습니다.
이처럼 부동 소수점 데이터는 복잡하게 표현되는 만큼, 연산 복잡도도 높고 그에 따라 연산 과정에서 소모하는 전력도 많습니다. 따라서 정수형 덧셈을 통해 부동 소수점의 곱셈과 같은 결과를 얻을 수 있다면 에너지 효율을 크게 높일 수 있겠죠. 그런데 인공지능 모델의 연산은 대부분 행렬의 곱셈으로 이뤄집니다. 행렬의 곱셈에서는 이를 구성하는 각 요소의 덧셈(Add)과 곱셈(Mul)이 모두 수행됩니다. 만약 행렬의 각 요소가 32비트 부동 소수점으로 표현된다면, Mul-Add 연산에서는 총 0.9 + 3.7 = 4.6 (pJ)만큼의 에너지가 필요합니다. 그런데 부동 소수점의 곱셈을 정수의 덧셈으로 교체할 수 있다면, 같은 연산을 하는 데 0.1 + 0.9 = 1.0 (pJ) 만큼의 에너지밖에 필요하지 않습니다. 에너지 소모량을 거의 80% 가까이 줄인 것이죠.
|
|
|
부동 소수점의 곱셈을 정수의 덧셈으로 대체할 수만 있다면 에너지 효율이 상당히 개선된다는 건 알았는데, 어떻게 그게 가능할까요? 연구진은 부동 소수점 곱셈(FP Mul)에 사용하는 연산식을 일부 수정하여 새로운 알고리즘을 제안하였습니다. 기존의 FP Mul은 다음과 같은 식으로 표현할 수 있습니다. |
|
|
대부분의 연산은 가수 부분의 곱셈(x_m · y_m)에서 발생하여 전체 연산 복잡도가 O(m^2)가 되게 합니다. 연구진은 이 부분을 제거하여, 연산 복잡도가 O(m)인 새로운 곱셈 알고리즘인 L-Mul을 제안하였습니다. 이 연산은 다음과 같이 표현됩니다. |
|
|
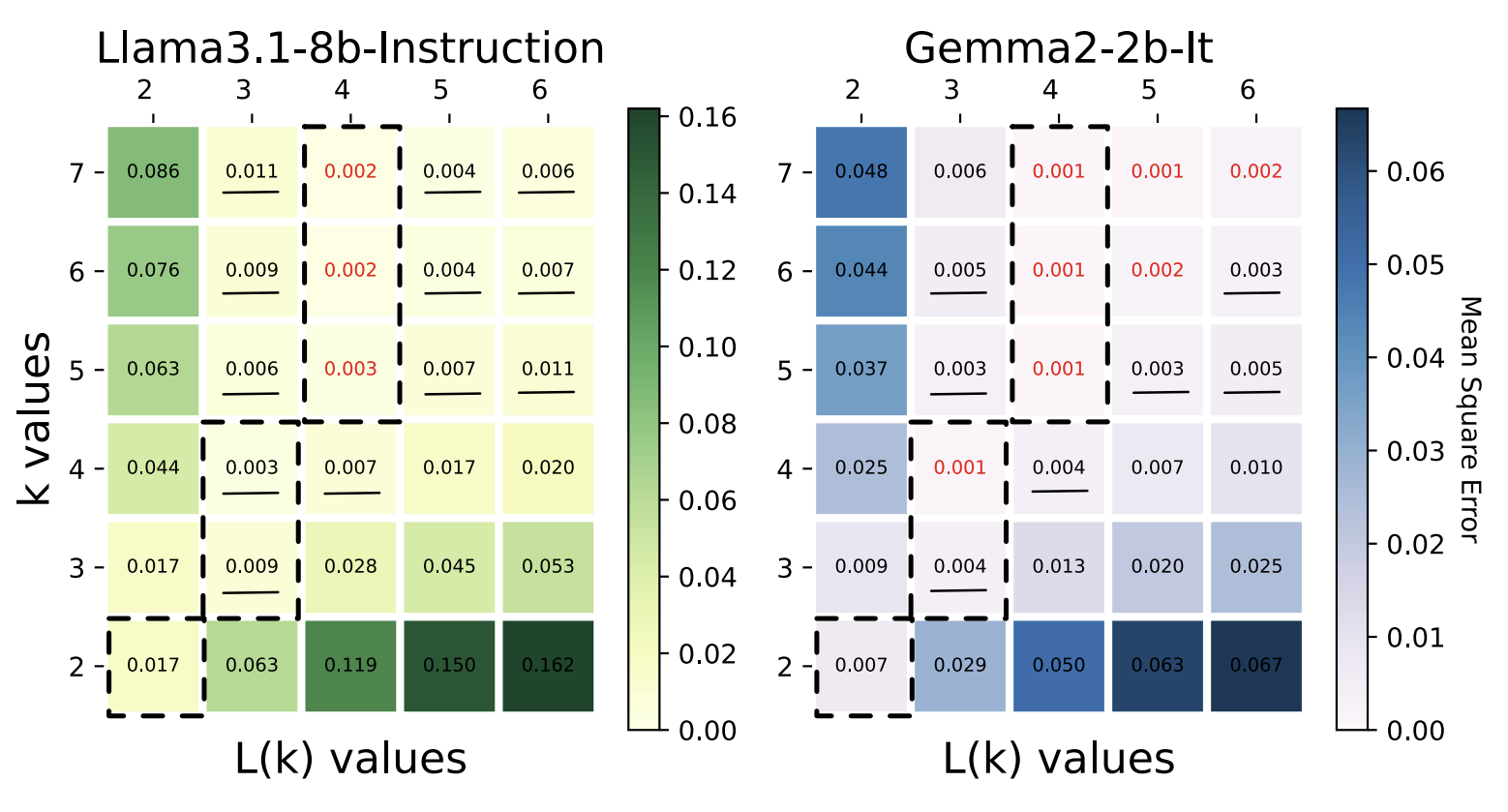
가수(Mantissa) 부분을 표현하는 데 사용한 비트의 개수(k)에 따라 l(k)를 다르게 설정했을 때의 오류 시각화
출처: Addition is All You Need for Energy-efficient Language Models (Luo and Sun, 2024)
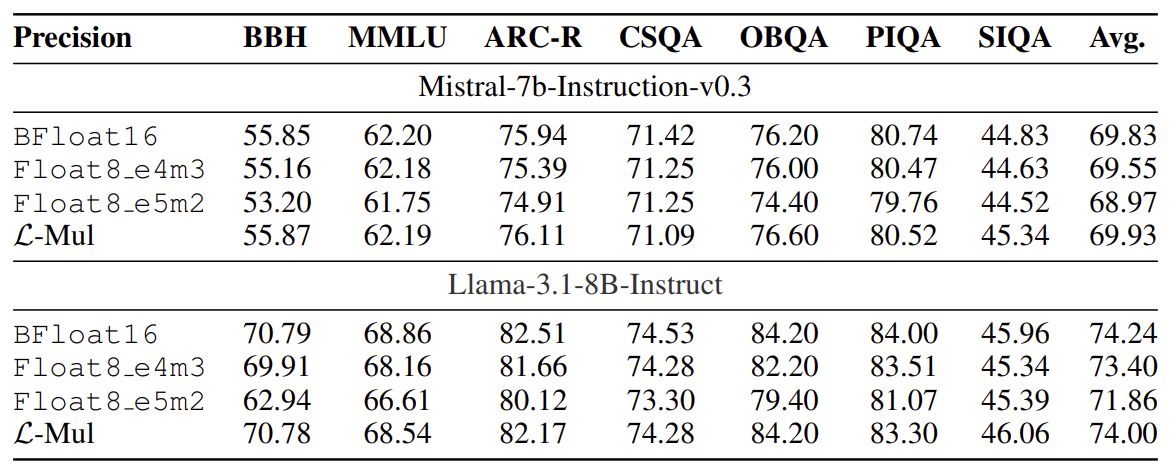
논문에 따르면 L-mul 알고리즘은 이론적으로 8비트 부동 소수점(FP8)의 곱셈을 사용하는 것보다 연산 정확도가 높습니다. 게다가 딥러닝 모델 가중치의 분포는 대체로 편향되어 있기 때문에, 이론적인 수치보다 높은 연산 정확도를 기대할 수 있다고 주장합니다. 실제로 LLM의 연산 과정에 L-Mul 알고리즘을 적용하여 실험한 결과, 거의 모든 벤치마크에서 성능 저하가 발생하지 않았습니다. |
|
|
어떤 산업의 전망을 평가하는 데 사용되는 여러 요소 중, 지속 가능성은 최근 들어서 특히 중요한 기준이 되었습니다. 무분별한 연구와 개발이 장기적으로 인류에 미칠 영향을 우려하는 목소리가 점차 커지고 있기 때문인데요. 실제로 AI는 그 자체로 혁신적인 기술이지만, 이를 지탱하기 위해서는 막대한 에너지 자원이 필요합니다. 현재의 인공지능이 가져오는 성과는 매번 우리를 놀라게 하지만, 그 이면에 숨겨진 문제는 절대로 간과할 수 없습니다.
인공지능 연구자들도 지속 가능한 AI를 개발하는 데 특별한 관심을 쏟아야 합니다. 오늘 소개한 연구는 지속 가능한 AI를 만드는 목표를 실현하는 중요한 한 걸음입니다. 단순히 계산 효율성을 높이는 것을 넘어, 인공지능 기술이 환경에 미치는 영향을 줄이는 데 기여한다는 점에서 큰 의의가 있는데요. 이는 에너지 효율성이 AI의 미래를 좌우하는 중요한 요소임을 다시금 상기시켜 줍니다.
나아가 이 연구는 지속 가능한 AI를 추구하면서도 기술 혁신을 이뤄낼 수 있음을 보여줍니다. 앞으로도 우리는 성능 향상이라는 단기적 목표에 매몰되는 대신, 기술의 발전이 우리에게 미칠 장기적 영향을 고려한 해결책을 모색해야 할 것입니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|