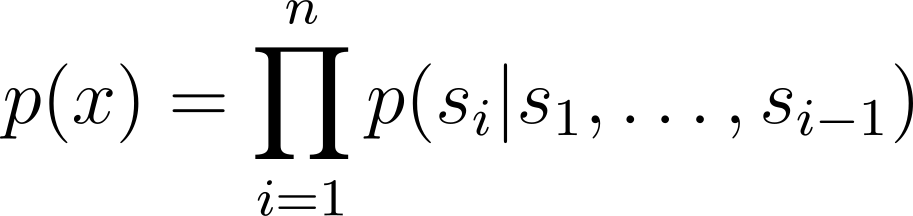프롬프트 엔지니어링의 기술적 원리에 대해서 알아봅니다. # 49 위클리 딥 다이브 | 2024년 7월 24일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 언어 모델이 문맥을 통해서 학습하는 방식, In-Context Learning을 소개합니다.
- In-Context Learning 개념을 바탕으로 프롬프트 엔지니어링을 설명합니다.
- OpenAI API를 활용한 실험을 통해 프롬프트 엔지니어링의 기술적 원리를 살펴봅니다.
|
|
|
안녕하세요, 에디터 민재입니다.
AI 기반 챗봇이 대중화되면서 이제는 일반인들도 쉽게 접할 수 있게 되었습니다. 국내 ChatGPT 애플리케이션 이용자는 지난 6월 300만 명을 넘어섰고, 월간 사용자 증가율은 가파르게 증가하고 있습니다. 웹 서비스 사용자를 집계하지 않은 것을 고려하면, ChatGPT를 비롯한 대규모 언어 모델(Large Language Model, LLM) 기반 챗봇 이용자의 수는 이보다 훨씬 많을 것입니다.
그런데 많은 사람들이 이러한 서비스의 핵심 기술인 LLM에 대해 잘 알지 못해 오해가 생기곤 합니다. ChatGPT와 같은 LLM 기반 챗봇을 단순한 검색 엔진으로 여겨, 부정확한 답변만 내놓는 실패작으로 취급하는 경우도 있었죠. 태생적으로 다음에 이어질 단어를 예측하는 프로그램인 LLM의 입장에선 억울한 누명이었을 것입니다.
반면에 LLM의 잠재력을 일찍 파악한 사람들은 이를 효과적으로 활용할 방법을 모색했습니다. 그 결과로 프롬프트 엔지니어링이라는 기술이 탄생했고, 이를 통해 LLM 기반 챗봇을 더욱 효율적으로 사용할 수 있게 되었습니다. 많은 기술 문서 또는 기사 등에서 프롬프트 엔지니어링을 원하는 결과를 얻기 위해 프롬프트를 구체적으로 작성하고 최적화하는 과정이라고 설명합니다. 적당한 정의지만, 이것이 왜 가능한지는 설명하고 있지 않는 경우가 대부분입니다. 그렇다면 프롬프트 엔지니어링이란 정확히 무엇이며, 어떤 원리로 작동하는 것일까요? |
|
|
문맥을 통해 학습하기, In-Context Learning |
|
|
프롬프트 엔지니어링을 이해하기 위해서는 먼저 In-Context Learning(ICL)의 개념을 알아야 합니다. ICL은 GPT-3를 소개한 논문, Language Models are Few-Shot Learners에서 제안된 개념인데요, 이걸 본격적으로 알아보기 전에 몇 가지 필요한 배경지식을 정리하겠습니다.
현대 딥러닝 모델은 대규모 데이터셋으로 사전 학습된(Pre-trained) 모델을 추가로 학습(Fine Tuning)하는 방식으로 만들어집니다. 자연어 처리에서는 거대한 말뭉치를 학습하며, 언어 자체를 이해할 수 있는 사전 학습 모델을 먼저 만들고, 구체적인 작업을 수행할 수 있도록 추가로 학습을 시키는 것이죠. 이런 방식을 전이 학습(Transfer Learning)이라고 하고, 이런 패러다임 덕분에 많은 AI 시스템의 성능과 학습 효율이 눈에 띄게 개선됐습니다.
하지만 여전히 한 가지 문제가 남아 있었습니다. 바로 각 태스크에 맞는 데이터셋(Task-specific Dataset)의 필요성입니다. 파인튜닝 과정에서는 문제와 정답(Label)의 쌍으로 이루어진 데이터셋(Supervised Dataset)이 필요합니다. 이런 형태의 데이터는 사람이 직접 만들어야 해서, 시간과 비용이 많이 든다는 치명적인 단점이 있습니다.
GPT-3 논문에서 이와 관련해 매우 중요한 논의가 이뤄집니다. 바로 Task-specific Dataset의 필요성이 사라져야 하는데, 그 이유는 대부분의 언어 기반 태스크를 학습할 때, 사람은 레이블이 있는 데이터셋이 필요하지 않기 때문입니다. 사람은 외부 환경과 상호작용을 하며 자연스럽게 작업을 수행하는 일반적인 능력을 얻고 이를 바탕으로, 명시적으로 학습하지 않는 일도 해낼 수 있죠. 그런데 GPT-3는 제한적으로나마 이런 학습 능력을 갖추게 되었습니다.
이렇게 학습하는 것을 바로 In-Context Learning이라고 합니다. LLM은 Pre-training 과정에서 방대한 양의 데이터를 학습하면서 패턴 인식 능력(Pattern Recognition Abilities)을 갖게 됩니다. 그리고 실제 사용할 때는 앞서 얻은 능력을 바탕으로 주어진 예시를 보고 새로운 작업을 수행하게 되죠.
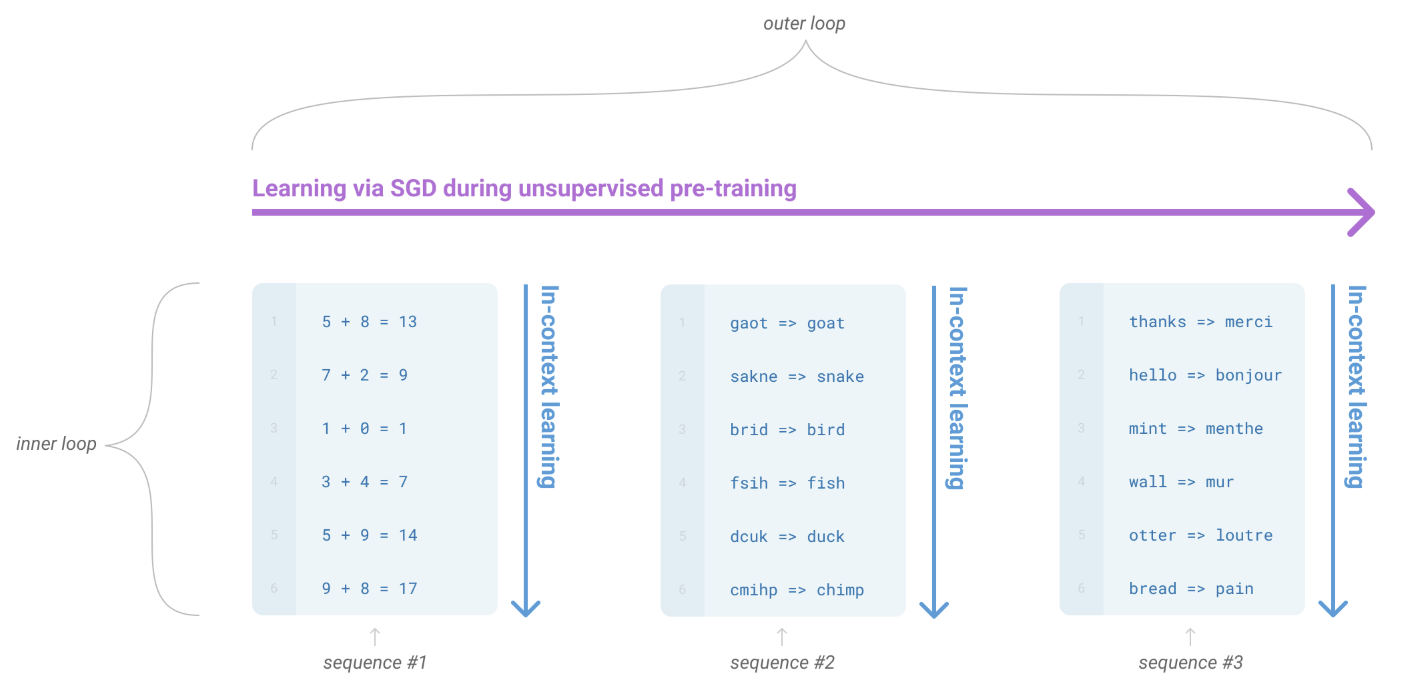
기계학습의 다양한 분야 중 하나로 메타 러닝(Meta Learning)이란 게 있습니다. 메타 러닝은 학습하는 방법을 학습하는 것(Learning to Learn)을 의미하는데요, 메타 러닝에서 학습 방법을 학습하는 단계를 외부 루프(Outer Loop), 그리고 이를 바탕으로 새로운 작업을 수행하는 단계를 내부 루프(Inner Loop)라고 합니다.
이 개념을 LLM에 그대로 적용하면, Pre-training 과정 중 패턴 인식 능력을 기르는 것을 외부 루프, 몇 가지 예시만을 보고 새로운 작업을 수행하는 사용 단계를 내부 루프라고 볼 수 있겠죠? 실제로 GPT-3 논문에서는 다음과 같이 GPT-3의 In-Context Learning 능력을 메타 러닝 개념에 빗대어 설명합니다. |
|
|
GPT-3의 학습 방법을 메타 러닝 관점에서 설명한 그림
출처 : Attention Is All You Need (Vaswani et al., 2017)
ICL의 중요한 특징은 모델 가중치를 업데이트하지 않는다는 것입니다. 일반적으로 딥러닝 모델은 학습은 데이터를 바탕으로 모델 가중치를 수정하며 새로운 지식을 학습하는데, 특이하죠? 원리는 앞에서 설명했듯이, 사전 학습 과정에서 익힌 패턴 인식 능력 덕분입니다. 이제 LLM은 엄청난 양의 데이터를 새롭게 학습하지 않아도, 사전에 학습한 능력을 바탕으로 여러 새로운 작업을 수행할 수 있게 되었습니다.
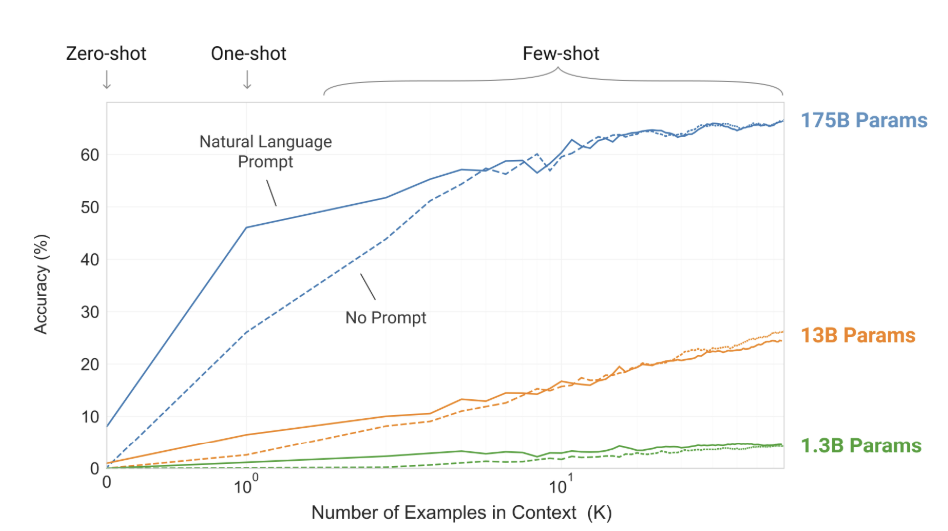
아래 그림은 모델의 크기에 따른 ICL 성능을 정량화한 것입니다. 여기서 Shot은 프롬프트에 제공되는 작업 예시를 의미하는데, 예시가 하나도 주어지지 않고 작업 명령만이 전달되면 Zero-shot, 예시가 한 개 주어지면 One-shot, 여러 개 주어지면 Few-shot이라고 합니다. |
|
|
언어 모델의 규모와 프롬프트에 제시된 작업 예시(Shot)에 따른 작업 정확도
출처 : Attention Is All You Need (Vaswani et al., 2017)
예를 들어, 하위 범주의 단어가 제시되면 그에 대응하는 상위 범주의 단어를 찾는 작업을 지시한다고 생각해보죠. Zero-shot은 단순히 이 작업을 설명하는데 그치지만, One-shot부터는 “라마 - 동물”과 같이 작업 예시를 프롬프트에 포함하여 제시합니다.
그러면 LLM이 In-Context Learning을 할 수 있게 되었다는 건 알았습니다. 주어진 문맥을 바탕으로 작업을 수행하는 방법을 이해하고, 사전 학습 과정에서 명시적으로 익히지 않은 새로운 태스크를 잘 수행한다는 것이죠. 그런데 이건 왜 가능할까요?
|
|
|
드디어 이야기는 다시 프롬프트 엔지니어링으로 돌아옵니다. 여기까지 이해했다면, 프롬프트 엔지니어링의 원리를 이해하는 것도 어렵지 않습니다. ICL의 개념을 되돌아보면, 사실 프롬프트 엔지니어링의 원리가 굉장히 단순하고, 또 당연하다고 볼 수 있습니다.
우선 언어 모델의 학습 방식을 생각해 보죠. 언어 모델링(Language Modeling)은 흔히 다음 토큰 예측(Next Token Prediction)이라고 표현하기도 합니다. 이를 수식으로는 다음과 같이 나타낼 수 있습니다. |
|
|
s를 토큰이라고 생각하면, 어떤 문장 x가 생성될 확률은 연속되는 토큰이 생성되는 확률의 곱으로 생각할 수 있습니다. 예를 들어, “여름이라 날씨가 참 덥죠?”라는 문장이 생성될 확률은 “여름”, “이라”, “날씨”와 같은 토큰들이 순차적으로 이어질 확률을 모두 곱한 값입니다.
그렇다면 각 토큰의 확률은 어떻게 정해질까요? 이건 학습 데이터를 바탕으로 결정되는데요, 앞의 예시에서 우리는 개념적으로 “여름”과 “덥다”라는 단어는 같은 문장에서 자주 함께 나타날 것으로 생각할 수 있습니다. 그리고 실제로 학습 데이터도 그렇게 되어있을 겁니다. 따라서 “여름이라 날씨가 참”이라는 표현 뒤에는 “덥죠?”라는 말이 자연스럽게 이어집니다.
정리하면 언어 모델은 문장의 일부가 주어졌을 때 그 뒤에 적절한 토큰이 나타날 조건부 확률을 최대화하는 방향으로 학습합니다. 그리고 실제로 사용될 때는, 학습한 데이터를 바탕으로 확률이 가장 높은 문장을 생성하죠. 그렇다면 이제 프롬프트 엔지니어링의 실체를 알 수 있습니다. 프롬프트 엔지니어링은 사용자의 의도에 맞는 응답이 생성될 확률을 높이기 위해 모델의 입력을 구성하는 작업입니다. 즉, 원하는 출력이 나올 조건부 확률을 간접적으로 조절하는 것이죠.
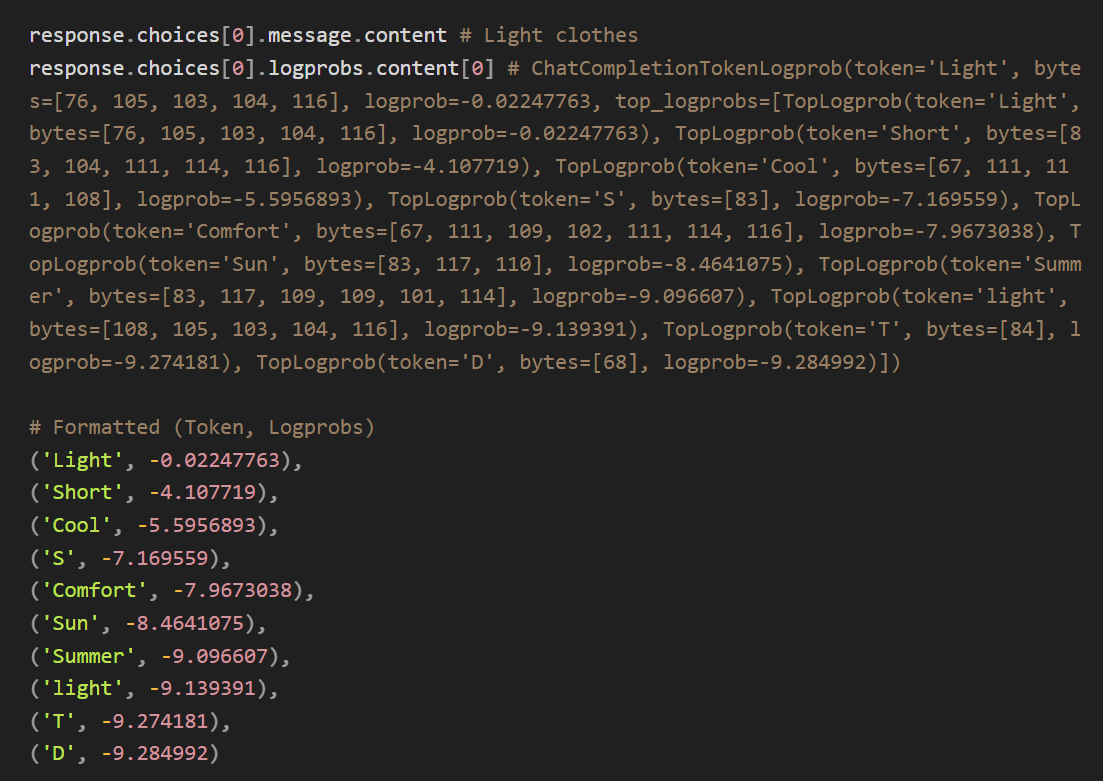
이런 해석이 올바른지 한번 직접 검증해 보겠습니다. OpenAI API를 사용하면 GPT가 응답을 생성할 때 선택한 토큰의 확률을 확인할 수 있습니다. 먼저 “여름에는 어떤 종류의 옷을 입어야 할까요? 단어로 대답하세요.”라는 질문에 GPT는 “가벼운, 짧은, 시원한, 편안한, 티셔츠”와 같은 단어에 높은 확률을 부여했습니다. 예상한 대로 여름옷과 잘 어울리는 키워드죠. |
|
|
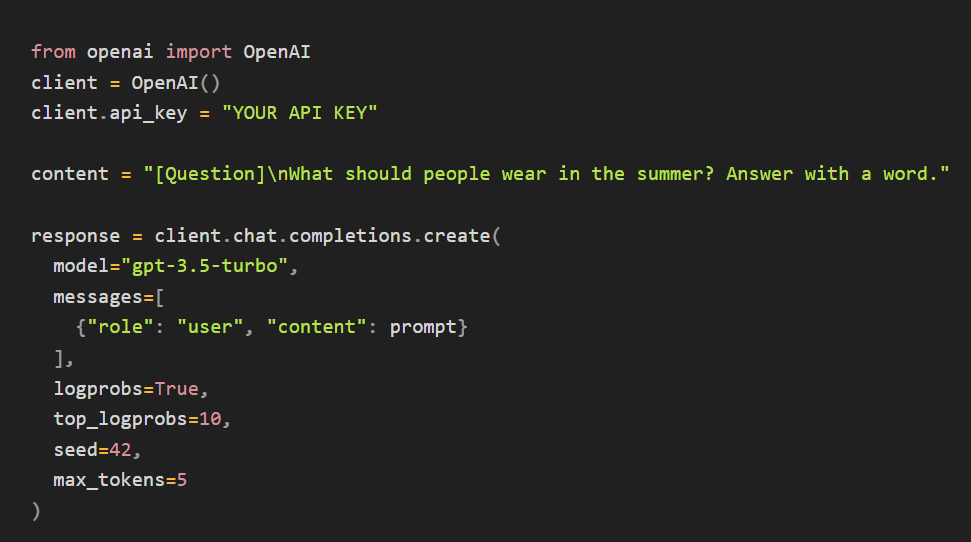
💡 OpenAI API에서 토큰의 확률 확인하기
글에서 사용한 응답 예시는 아래 코드를 사용하여 생성했습니다. 응답을 생성할 때 lobprobs라는 인자를 True로 설정하고, top_logprobs라는 인자에 0에서 20 사이의 값을 입력하면, 각 토큰의 생성 확률을 확인할 수 있습니다.
|
|
|
© deep daiv.
아래는 본문에서 사용한 질문에 대한 응답의 각 토큰 확률입니다. 실제로 Light, Short, Cool과 같은 단어들이 높은 확률을 가짐을 확인할 수 있습니다. 참고로 이 값은 로그 확률이므로, 원래의 확률을 얻으려면 지수 함수에 이 값을 대입하면 됩니다. 예를 들어, Light가 생성될 확률은 e^-0.022 즉, 약 97.8%입니다. |
|
|
간단한 실험을 통해 같은 질문에 대해서도 언어 모델이 전혀 다른 응답을 생성할 수 있음을 확인했습니다. 핵심은 프롬프트의 구성에 따라 동일한 의미의 질문에도 다양한 응답을 얻을 수 있다는 것이죠.
LLM은 놀라운 성능을 보여주지만, 그 작동 원리는 생각보다 단순합니다. 방대한 양의 데이터에서 학습한 정보를 바탕으로 단어를 순차적으로 생성해 나갈 뿐이죠. 단순히 사용자의 입장에서 이 정도까지 알아야 하는지 의문이 들 순 있습니다. 하지만 인공지능 연구자가 아니더라도 기술적 원리를 이해하면 LLM을 더욱 효과적으로 활용할 수 있고, 그 한계점도 명확히 인식할 수 있습니다.
언어 모델과 프롬프트 엔지니어링에 대한 올바른 이해는 AI 기술의 발전과 활용에 매우 중요합니다. 잘못된 해석이 퍼지면 인공지능에 대한 신뢰도가 낮아질 수 있기 때문입니다. AI 기술이 빠르게 발전하고 다양한 분야에 적용되는 현시점에서 이런 사실은 더욱 중요합니다. 따라서 LLM의 원리와 프롬프트 엔지니어링의 중요성을 제대로 인식하고, 이를 바탕으로 AI 기술을 올바르게 활용하는 방법을 알아야 합니다. 이를 통해 인공지능 기술이 앞으로도 우리에게 더욱 긍정적인 영향을 미칠 수 있기를 기대합니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|