메타의 수석 AI 과학자, 얀 르쿤이 제시한 세계 모델이 무엇인지 살펴봅니다. # 40 위클리 딥 다이브 | 2024년 5월 22일
에디터 민재 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 얀 르쿤이 지적한 GPT의 한계에 대해 정리합니다.
- 사람과 기계의 학습 과정에서 나타나는 차이를 살펴봅니다.
- 얀 르쿤이 제안한 세계 모델과 이를 기계가 학습하는 방법을 설명합니다.
|
|
|
안녕하세요, 에디터 민재입니다.
이번 뉴스레터에서는 인공지능 분야의 대부 중 한 명으로 불리는 얀 르쿤의 세계 모델(World Model)을 소개합니다. 이 주제는 두 편에 걸쳐 다뤄질 예정이며, 전반부에서는 얀 르쿤이 지적한 생성적 방법론(Generative Approach)의 한계와 그가 생각하는 인간의 학습 방식을 정리합니다. 후반부에서는 얀 르쿤이 제안한 아이디어의 구현체인 JEPA 아키텍처를 자세히 살펴봅니다. 얀 르쿤이 세상을 바라보는 방법은 무엇인지, 그의 통찰을 따라가며 인공지능이란 무엇인가에 대해 다시 생각하는 시간을 가져보죠. |
|
|
ChatGPT의 등장과 함께 시작된 언어 모델의 시대는 인류에게 전례 없는 삶의 변화를 가져다주었습니다. UBS에서는 ChatGPT를 두고 “인터넷이 등장한 이후 20년 동안 이 정도로 성장 속도가 빨랐던 서비스가 없었다”라고 평가했습니다. 굳이 수치를 대지 않아도, 이제 우리는 피부로 느끼고 있습니다. 신기한 기술에 불과했던 인공지능이, 우리의 일상에 얼마나 스며들었는지를 말이죠.
넓은 의미에서 인공지능이 인간의 지능을 모방한 무언가라고 생각한다면, 결국 사람이 할 수 있는 것이라면 모두 기계도 할 수 있게 되지 않을까 하는 생각도 듭니다. 실제로 인공지능이 대체하지 못할 직업에 대한 질문을 받게 되면, 자신 있게 답을 내놓기는 쉽지 않습니다. AI 시대의 한 가운데에 선 우리는 이제, 기존에 인간을 정의하던 고유한 속성에 대해 재고해 볼 필요가 있습니다.
그런데 일각에서는 언어 모델이 단순히 확률론적 앵무새(Stochastic Parrot)에 불과하다는 주장도 있습니다. 심지어 언어 모델을 비롯한 모든 인공지능 연구의 기반 기술인 머신러닝이 통계를 미화한 것에 불과(Machine learning is just glorified statistics)하다는 조롱도 있었죠. 이런 반발은 단순히 신기술이 유행할 때면 으레 그랬던 것처럼 과도기에 발생하는 정기 행사일 뿐일까요?
단순히 그런 이유 때문은 아닐 것입니다. 일반인공지능(Artificial General Intelligence, AGI)에 도달하기 위해서, 실제로 언어 모델이 자연어를 처리하는 방식과 사람이 언어를 통해 사고하는 방식이 일치하느냐는 생각보다 중요한 문제일지도 모릅니다. |
|
|
🦜 확률론적 앵무새 (Stochastic Parrot)
이 표현은 On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (Bender et al., 2021)이라는 논문에서 처음 사용됐습니다. 이는 대규모 언어 모델(Large Language Model, LLM)이 그럴듯한 언어 생성 능력을 갖추긴 하지만, 그 의미를 이해하지 못하고 있음을 비판하기 위해 사용되었습니다.
논문에서는 엄청난 양의 환경적, 재정적 자원을 소모하는 LLM이 원인을 알 수 없는 편향을 학습하고, 끝내 잠재적인 위협을 초래할지도 모른다는 사실을 지적합니다. 실제로 GPT를 필두로 한 현시대의 LLM은 대부분 학습한 확률 분포에 따라 다음 토큰 예측(Next Token Prediction)을 수행하는 기계일 뿐이라는 이야기가 기술적으로 틀린 말은 아닙니다. |
|
|
Meta의 수석 AI 과학자인 얀 르쿤(Yann Lecun)은 ChatGPT와 그것이 동작하는 방식인 자기회귀적(Auto-Regressive) 성질에 대해 여러 차례 비판하였습니다. 그는 자기회귀적인 LLM에서 발생하는 오류는 지수적으로 증가하며, 틀린 답을 내놓을 확률이 그에 따라 증가한다고 지적했습니다.
예를 들어 생성된 토큰이 정답이 아닐 확률을 e라고 한다면, 길이가 n인 문장이 올바르게 생성될 확률은 (1-e)^n이 됩니다. 오류는 누적이 되고, 정답일 확률은 기하급수적으로 감소하죠. 오류가 발생할 확률을 줄인다면 이런 현상을 완화할 수는 있지만, 근본적인 해결책은 아닙니다. 얀 르쿤은 이에 대한 대안으로 자기회귀적이지 않은(Non Auto-Regressive) LLM을 제안합니다.
얀 르쿤은 현재의 LLM이 인간, 심지어는 동물이 세상을 인식하는 수준에도 미치지 못한다고 했습니다. LLM은 언어 능력에도 불구하고 세상에 대한 이해도가 낮다고 비판했죠. 그는 현재의 AI는 인간 수준에 근접하지도 않으며 자기회귀적인, 또는 생성적(Generative)인 모델은 진정으로 세상을 이해하는 방법을 모사하지 않는다고 했습니다. 얀 르쿤이 AI 연구를 통해 궁극적으로 이루고자 하는 바는, 인간이 세상을 이해하는 방식을 모델링하고, 이를 기계에 주입하는 것이 아닐까요? |
|
|
사람이나 동물은 자신을 둘러싼 환경과 상호 작용을 하며 엄청난 양의 배경지식을 학습합니다. 이렇게 축적된 지식은 흔히 상식(Common Sense)이라고 불리는 것의 기초가 되죠. 이를 기술적으로 표현하면, 끊임없는 비지도 학습을 통해 특정 작업과 무관한(Task-Independent) 일반적인 지식을 학습하는 것이라고 할 수 있습니다. 상식은 무엇이 그럴듯한지, 또는 불가능한지를 구분하게 해주며, 이를 통해 그들이 살아가는 세상을 이해하는 방식인, 이른바 세계 모델(World Model)을 구축할 수 있습니다. 우리는 세계 모델을 통해 행동의 결과를 예측하고, 추론하고, 계획을 세우며 문제에 대한 새로운 해결책을 마련합니다.
얀 르쿤은 우리가 세계 모델을 구축하는 방식은 비지도 학습의 일종인 자기 지도 학습(Self-Supervised Learning, SSL)으로 이루어진다고 했습니다. 머신러닝에 관한 배경지식이 있는 분은 인간이 환경과 상호작용하며 학습하는 방식에서 강화 학습을 떠올릴지도 모릅니다. 하지만 얀 르쿤은 자율 주행 자동차를 예로 들며, 이를 반박합니다. 자율 주행은 인간이라면 하지 않을 실패를 포함한 수천 번의 시행착오를 통해 학습합니다. 하지만 우리는 물리적 직관을 발휘해 사고를 예측하고, 실패를 극적으로 줄이며 적은 시도를 통해 학습할 수 있습니다. 이처럼 강화 학습은 인간이 세계 모델을 학습하는 방식과 근본적인 차이가 있기 때문에, 그는 특별히 자기 지도 학습이라는 개념을 사용했습니다. |
|
|
📖 인공지능의 학습 방법
인공지능 모델이 학습하는 방법은 일반적으로 데이터의 형태에 따라 크게 세 가지로 나뉩니다. 학습하는 데이터의 정답을 레이블(Label)이라고 하는데, 레이블이 있는 데이터를 학습하는 경우 지도 학습(Supervised Learning)이라고 합니다. 대표적으로 개와 고양이의 사진을 보고, 둘 중 어느 것인지를 결정하는 문제가 있죠. 반대로 레이블이 없는 데이터를 학습하면 비지도 학습(Unsupervised Learning)이라고 합니다. 비지도 학습은 정답을 맞히는 것보다는, 데이터의 분포에서 패턴을 추출하는 게 목표입니다. 대표적인 과제인 군집화(Clustering)는 여기저기 흩어진 데이터를 적절히 그룹으로 묶어 각 그룹의 대표적인 특징이 무엇인지를 발견합니다.
그렇다면 나머지 하나인 강화학습(Reinforcement Learning)은 무엇일까요? 일반적으로 강화학습은 학습의 주체인 에이전트(Agent)가 환경(Environment)과 상호 작용하며, 정책(Policy)에 따라 행동(Action)을 결정하고, 그에 따른 보상(Reward)을 바탕으로 학습한다고 설명합니다. 하지만 이런 정의는 직관적이지 않습니다. 레이블의 관점에서 강화학습을 다시 정의해보죠. 지도 학습은 정답을 명시적으로 제시하고, 최선의 결과가 무엇인지를 직접 학습합니다. 반면 비지도 학습은 어떠한 정보조차 주어지지 않죠.
강화학습은 정답이 주어지지 않는다는 점에서는 비지도 학습과 유사해 보이지만, 보상을 통해 학습한다는 점에선 지도 학습과 비슷합니다. 하지만 명백한 차이는, 보상이 항상 최선의 결과에 의해서만 주어지지는 않는다는 것입니다. 에이전트가 올바르지 않은 선택을 할 경우, 음수에 해당하는 보상인, 처벌(Penalty)이 주어질 수도 있고, 최선은 아니지만 나쁘지 않은 선택을 할 경우 적은 양의 보상이 주어지기도 합니다. 따라서 최적(Optimal)의 선택지가 무엇인지 명시적으로 학습하지 않는다는 점이 강화학습의 특징입니다. |
|
|
세계 모델을 통해 학습한 상식은 단순히 미래의 결과를 예측하는 데만 쓰이지는 않습니다. 상식은 생략된 시간적 또는 공간적 정보를 채우는 데도 도움이 됩니다. 알 수 없는 상황에 직면했을 때, 우리는 보통 내재한 세계 모델에 합치하는 정보에는 주의를 기울이고, 그렇지 않은 정보는 무시하는 경향이 있습니다. 이렇게 위험을 피하기도 하며, 새로운 배움을 통해 세계 모델을 일부 수정하기도 합니다.
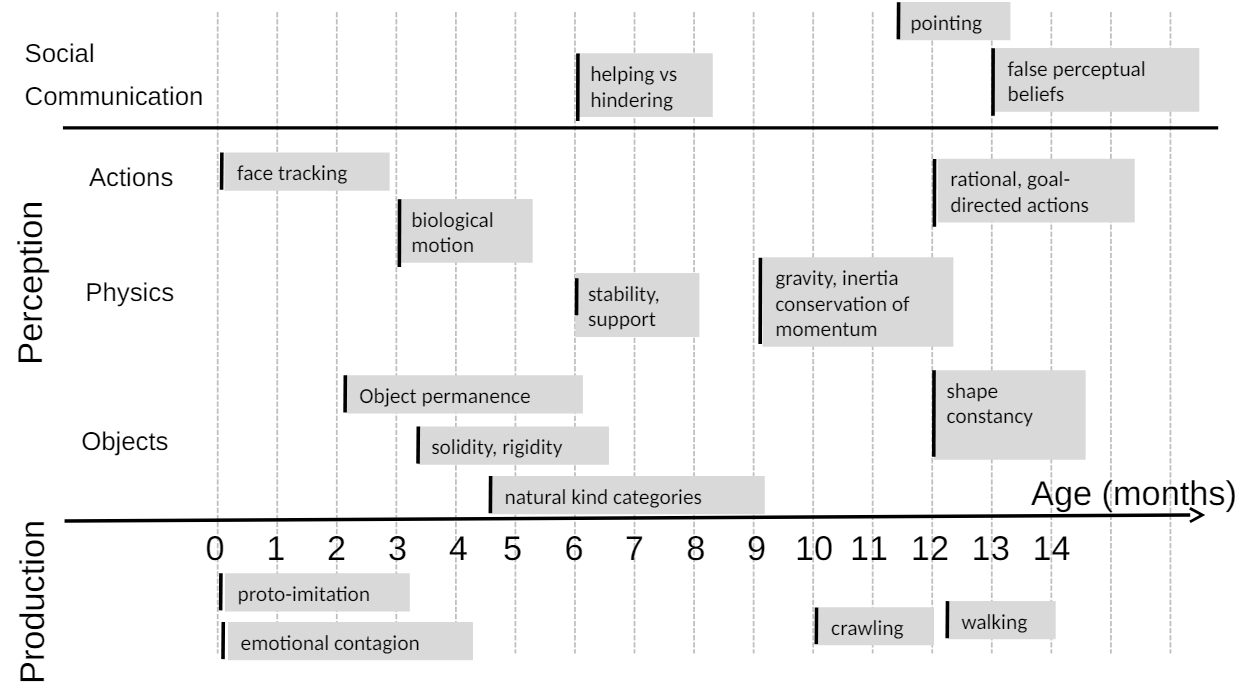
우리는 태어난 지 얼마 되지 않아 빠른 시간 안에 세상이 어떻게 돌아가는지를 학습합니다. 엄청난 양의 정보가 머릿속으로 물밀듯이 들어오지만, 그저 당연한 것으로 여길 뿐이죠. 하지만, 우리가 학습하는 상식에도 일종의 순서와 위계가 존재합니다. Emmanuel Dupoux가 영아의 시기별 학습 개념을 정리한 자료에 따르면, 인간은 태어난 직후 매우 기초적인 개념을 학습하고 점점 더 복잡하고 추상적인 개념을 순서대로 깨칩니다. |
|
|
출처: A Path Towards Autonomous Machine Intellingence (Yann Lecun, 2022) |
|
|
그런데 인간과 동물이 살아가는 데 필요한 모든 지식을 하나의 세계 모델에 전부 담을 수 있을까요? 얀 르쿤은 우리의 뇌가 전전두피질(Prefrontal Cortex) 어딘가에 하나의 세계 모델 엔진을 담고 있다고 말합니다. 그 세계 모델은 주어진 과제에 따라 매우 유연하게 동작하며, 우리는 단일한, 구성 가능한 세계 모델 엔진(Configurable World Model Engine)을 사용하여 모든 상황에 대처할 수 있습니다. 그렇다면 기계는 어떻게 우리의 세계 모델을 학습할 수 있을까요? |
|
|
얀 르쿤은 A Path Towards Autonomous Machine Intelligence라는 제목의 포지션 페이퍼를 통해 기계가 사람과 같이 학습하도록 하는 방법을 제안했습니다. 이를 실현하기 위해 AI 연구에서 해결해야 할 문제를 세 가지 제시합니다. 먼저 기계가 세계를 표현하고, 예측하고, 행동하는 방법은 관찰을 통해 이루어져야 합니다. 실제 세상과의 상호작용은 비용이 많이 들고, 위험하기도 합니다. 또한 이런 방법은 앞서 논의했듯 사람의 방식과는 매우 다르죠.
그다음으로 제시한 문제는 조금 더 기술적인 면을 다룹니다. 복잡하고 불확실한 현실 세계를 효과적으로 포착하기 위해, 모델 아키텍처는 전 범위에서 그라디언트 기반 학습(Gradient-based Learning)이 가능해야 한다는 것입니다. 기존의 규칙 기반 추론은 미분이 불가능한 함수를 사용하는데, 이런 문제는 딥러닝 모델의 학습을 어렵게 하므로 극복해야 할 문제입니다.
마지막으로 얀 르쿤은 기계가 계층적인 방법(Hierarchical Manner)으로 인지 작용과 행동 계획을 표현해야 한다고 언급합니다. 앞서 논의한 바와 같이 우리는 다양한 수준의 추상화를 통해 예측하거나 계획을 수립하고, 복잡한 과제를 단계별로 분해하여 수행합니다.
얀 르쿤은 이처럼 인공지능이 극복해야 할 근본적인 문제를 해결하는 방법을 장장 62페이지에 걸친 논문을 통해 단계별로 제시합니다. 논문에서는 아래 그림과 같이 각각의 모듈이 모두 미분 가능하며, 학습할 수 있는 아키텍처를 제안합니다.
아키텍처를 구성하는 각 모듈을 간단히 살펴보겠습니다. 먼저, Configurator 모듈은 다른 모듈에서 입력을 받아 처리한 후 각 모듈에 지시를 내립니다. Perception 모듈은 주변 환경(World)의 현재 상태를 파악합니다. Cost 모듈은 에이전트가 느끼는 불편(Discomfort)을 정량화합니다. 이를 에너지라고 하며, 에이전트는 에너지를 낮게 유지하는 것을 목표로 행동을 선택합니다. 마지막으로 논문의 핵심인 World Model 모듈은 Perception 모듈이 제공하지 않은 생략된 정보를 추정하고, 그럴듯한 미래를 예측합니다.
|
|
|
얀 르쿤이 제안한 자율 지능을 위한 시스템 아키텍처
출처: A Path Towards Autonomous Machine Intellingence (Yann Lecun, 2022)
World Model 모델은 일종의 시뮬레이터이며 하나의 상황에 대해 다양한 미래를 예측할 수도 있습니다. 실제 세상은 완벽하게 예측 가능하지 않으며, 특히 적대적인 지능형 에이전트를 포함한 환경에서는 더욱 미래를 예측하기가 어렵습니다. 그렇지 않더라도 행동을 예측하기 어려운 무생물이나 완벽하게 관찰 가능하지 않은 개체를 포함한 상황에도 완벽한 예측은 불가능에 가깝습니다. 그렇기 때문에 애초에 세계를 모델링하기 위해 설계된 기계는 다수의 그럴듯한 미래를 예측하는 방법을 학습해야 합니다.
얀 르쿤이 제안한 아키텍처의 각 모듈은 상호 작용을 하며 학습하고, 인간과 같이 세상을 인식하게 됩니다. 고수준에서 제안한 이 아키텍처는 어떤 방식을 통해 무수히 이어지는 이진수의 나열로 대응될 수 있을까요? |
|
|
얀 르쿤은 이미 전부터 생성적인 방법론은 인간이 세계를 지각하는 방식과 동떨어져 있음을 깨닫고 있었습니다. 우리가 예측할 때는 분명히 과거의 정보를 활용합니다. 하지만 그 정보는 과거 우리가 학습한 것을 그대로 재현한 것이 당연히 아닙니다. 기억은 왜곡되고, 불필요한 정보는 걸러지며, 추출된 핵심 정보만이 잠재의식에 남게 되죠. 얀 르쿤은 이처럼 우리가 활용하는 정보가 임베딩(Embedding) 되어있다는 개념에 착안하여 Joint Embedding Predictive Architecture(JEPA)를 제안합니다. 이는 명시적으로 정해진 미래를 예측하는 기존의 생성적 방법과는 다릅니다.
JEPA는 다양한 예측을 허용하고, 본질적으로 미래를 정확하게 예측하는 것은 불가능하다는 전제를 바탕으로 학습합니다. 또한 미래를 예측할 때, 가지고 있는 정보를 모두 사용하지는 않습니다. 갈림길에 선 자동차가 어느 방향을 향할 지 예측하는 데, 주변의 나무가 몇 그루 있는지는 중요하지 않죠. 얀 르쿤이 제안한 JEPA는 인공지능이 세상을 이해하는 방식에 어떤 혁신을 일으킬 수 있을지가 기대됩니다. 분명히 GPT의 원리는 인간의 언어적 사고가 작동하는 방식과는 다릅니다. 하지만 놀라울 정도의 성능을 보이는 것 또한 사실입니다. 그렇다면 과연 사람처럼 세상을 이해하는 JEPA는 또 어떤 방식으로 우리를 놀라게 할까요?
|
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆 |
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|