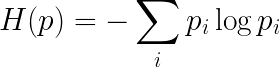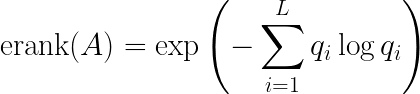Vision Token Pruning 방법을 소개합니다. #134 위클리 딥 다이브 | 2026년 3월 11일
에디터 잭잭 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- Vision Token Pruning의 핵심 아이디어를 소개했습니다.
- Attention과 Diversity 기반 Pruning 방법을 정리했습니다.
- AgilePruner를 통해 Image-aware Pruning 전략을 살펴봤습니다.
|
|
|
안녕하세요, 에디터 잭잭입니다. 오늘은 Vision Token Pruning 을 주제로 다뤄보려고 합니다.
사람이 어떤 장면을 볼 때는 이미지의 모든 정보를 동일하게 처리하지 않습니다. 예를 들어 “고양이는 어디에 있는가?”라는 질문을 받으면 장면 전체를 세밀하게 분석하기보다, 고양이가 있을 것 같은 영역에 시선을 집중하죠. 즉 인간의 시각 시스템은 별다른 노력 없이 중요한 정보와 그렇지 않은 정보를 자연스럽게 구분하며, 제한된 인지 자원을 효율적으로 사용합니다.
|
|
|
로봇이 주변 환경을 인식하는 상황은 사람이 장면을 볼 때와 비슷합니다. 로봇이 카메라를 통해 환경을 인식하면 하나의 장면 안에는 여러 객체와 배경 정보가 함께 포함됩니다. 예를 들어 로봇에게 “테이블 위의 빨간 컵을 집어”라는 명령이 주어졌다고 해보겠습니다. 로봇의 카메라에는 컵뿐만 아니라 책, 노트북, 의자, 벽, 창문 등 다양한 물체들이 동시에 관찰될 수 있습니다. 하지만 실제로 로봇이 행동을 결정하는 데 필요한 정보는 컵과 그 주변의 일부 환경뿐입니다.
그런데 로봇은 실제 물리 세계에서 동작하기 때문에 여러 제약 조건을 함께 고려해야 합니다. 로봇은 보통 자체 장치에서 동작하므로 사용할 수 있는 연산 자원, 메모리, 전력이 제한적이며, 동시에 주변 환경을 실시간으로 인식하고 즉각적으로 행동을 결정해야 합니다. 이러한 조건에서는 장면의 모든 시각 정보를 동일하게 처리하기보다, 과업 수행에 필요한 정보에 연산을 집중하는 접근이 더욱 중요해집니다.
이러한 문제의식에서 등장한 연구 흐름이 바로 Vision Token Pruning입니다. 이 기법은 이미지에서 생성되는 수많은 시각 토큰 중 중요한 토큰만 선택적으로 유지하여 전체 연산량을 줄이려는 접근입니다. |
|
|
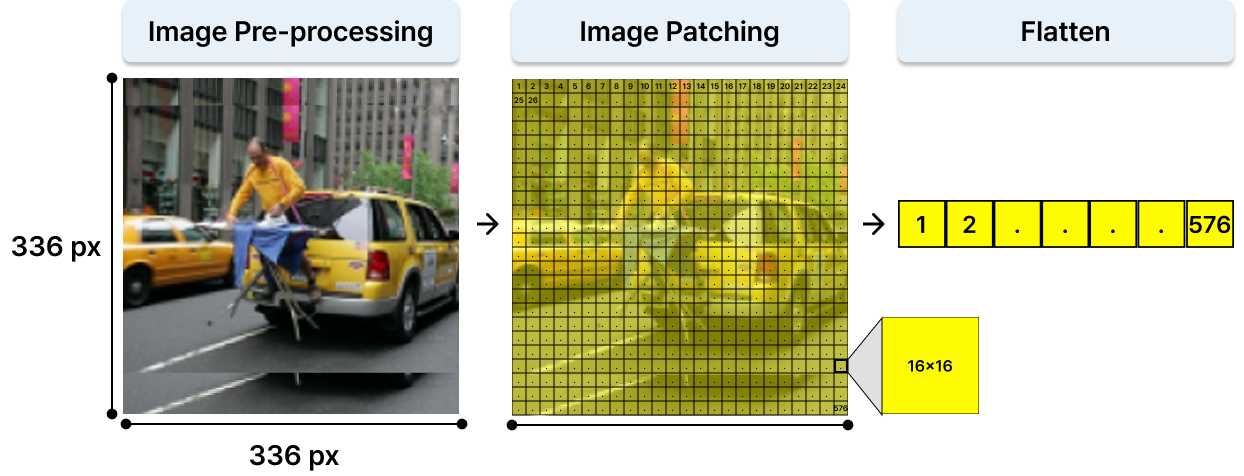
이러한 아이디어를 이해하기 위해서는 먼저 모델이 이미지를 어떤 형태의 입력으로 변환해 사용하는지 살펴볼 필요가 있습니다. 최근 널리 사용되는 Vision Transformer 기반 모델에서는 하나의 이미지를 여러 개의 패치(Patch)로 나누어 각각을 시각 토큰(Vision Token)으로 변환한 뒤 처리합니다. 아래 그림은 이러한 이미지 전처리 과정을 단계별로 보여줍니다. |
|
|
Vision encoder 내부의 이미지 전처리 과정
출처: ⓒ deep daiv.
예를 들어 336×336 크기의 이미지가 입력되었다고 가정해 보겠습니다. 먼저 입력 이미지는 모델이 사용할 수 있는 해상도로 전처리됩니다 (Image Pre-processing). 이후 이미지는 일정한 크기의 작은 패치로 분할됩니다 (Image Patching). 그림처럼 16×16 크기의 패치로 나누면, 가로와 세로 방향으로 각각 24개의 패치가 생성되고, 결과적으로 총 24×24=576개의 패치가 만들어집니다. 즉 하나의 이미지는 최종적으로 576개의 시각 토큰 시퀀스(Flatten)로 표현되어 Vision Transformer에 입력됩니다. |
|
|
Vision Encoder를 통해 생성된 시각 토큰들은 이후 텍스트 토큰과 함께 LLM에 입력되어 여러 층의 Attention 연산을 거치며 서로 상호작용하게 됩니다. Transformer의 Self-attention은 모든 토큰 쌍 간의 관계를 계산하는 구조를 가지고 있기 때문에, 토큰의 개수를 N이라고 하면 Attention 연산의 복잡도는 N^2에 비례합니다. 즉 시각 토큰의 수가 많아질수록 모델이 수행해야 하는 연산량은 제곱 형태로 빠르게 증가하게 됩니다.
이 문제는 입력 해상도가 높아질수록 더욱 심각해집니다. 예를 들어 고해상도 이미지를 사용하는 경우 하나의 이미지가 2,880개 이상의 시각 토큰으로 분할되기도 합니다. 또한 비디오 입력에서는 이러한 토큰이 시간 축으로도 반복되기 때문에 여러 프레임이 함께 처리되면서 전체 토큰 수가 더욱 빠르게 증가합니다. 그 결과 Attention 연산의 규모가 커지면서 추론 속도와 메모리 사용량 모두에 큰 부담이 발생합니다.
따라서 중요하지 않은 시각 토큰을 줄이기 위한 Vision Token Pruning 연구가 활발히 이루어지고 있습니다. |
|
|
이 기법이 가능한 이유는 이미지의 모든 시각 토큰이 동일한 중요도를 가진 것은 아니기 때문입니다. 많은 경우 한 이미지의 대부분은 수행해야 하는 과업과 직접적으로 관련이 없는 정보일 수 있습니다. 예를 들어 앞서 살펴본 “테이블 위의 빨간 컵을 집어라”라는 상황에서는 컵 주변의 일부 영역만이 로봇의 행동을 결정하는 데 핵심적인 정보를 제공하며, 벽, 창문, 바닥과 같은 영역은 상대적으로 덜 중요한 정보일 가능성이 높습니다.
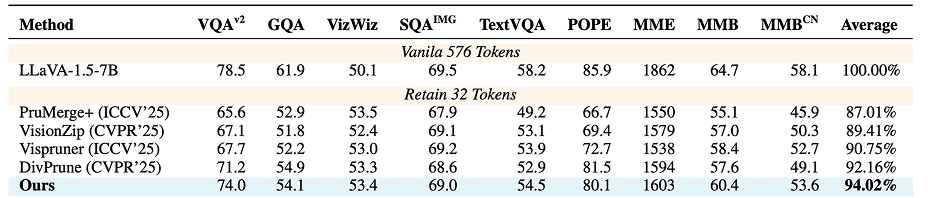
따라서 이미지의 모든 토큰을 동일하게 처리하기보다 일부만 남기더라도 모델의 성능을 크게 저하시키지 않으면서 계산 비용을 크게 절감할 수 있다는 결과가 여러 연구에서 보고되고 있습니다. 예를 들어 오늘 살펴볼 논문 중 하나인 AgilePruner에서는 576개의 시각 토큰 중 단 32개만 사용했음에도, 모든 토큰을 사용하는 경우 대비 약 94% 수준의 성능을 유지하는 결과를 보여줍니다. |
|
|
Vision Token Pruning은 어디에서 일어날까? |
|
|
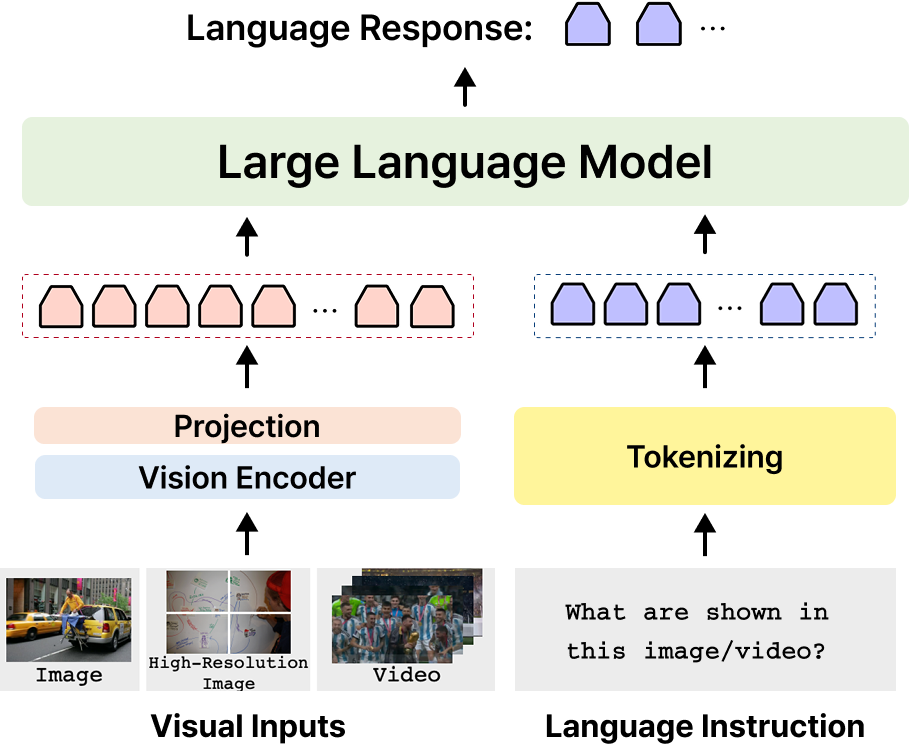
멀티모달 대형 모델(MLLM)은 일반적으로 위 그림과 같은 구조로 이루어져 있습니다. 오늘 다룰 Vision Token Pruning 방식은 시각 토큰이 LLM에 입력되기 이전 단계에서 토큰 수를 줄이는 방법입니다. 이 접근에서는 Vision Encoder를 통과한 뒤 생성된 시각 토큰 중 일부만 선택적으로 유지한 후, 이를 LLM의 입력으로 전달합니다. |
|
|
MLLM의 구조. 이미지는 먼저 Vision Encoder를 통과하면서 여러 개의 시각 토큰으로 변환된다. 이후 이 토큰들은 텍스트 토큰과 함께 LLM에 입력되어 추론 과정에 사용된다.
출처: ⓒ deep daiv.
예를 들어, LLaMA-7B 모델은 약 32개의 Transformer 레이어로 구성되어 있습니다. LLM에서는 각 레이어의 Self-attention 연산이 토큰 수에 대해 제곱(Quadratic) 형태로 증가하기 때문에, 토큰을 LLM 내부의 중간 레이어에서 줄이는 것보다 LLM에 입력되기 이전 단계에서 미리 줄이는 것이 더 큰 연산 절감 효과를 가져옵니다. 이렇게 하면 이후 모든 레이어에서 수행되는 Attention 연산이 줄어들기 때문에, 모델 전체의 계산량을 보다 효과적으로 줄일 수 있습니다.
이때 중요한 문제는 어떤 토큰을 남기고 어떤 토큰을 제거할 것인가를 결정하는 기준입니다. 기존 연구에서는 주로 두 가지 관점에서 이 문제를 접근해 왔습니다. 하나는 중요한 토큰을 선택하려는 Attention-based 방법이고, 다른 하나는 토큰 간 중복을 최소화하여 다양한 정보를 유지하려는 Diversity-based 방법입니다. |
|
|
Attention-based Vision Token Pruning |
|
|
먼저 Attention-based 접근에서는 Vision Encoder 내부에서 계산되는 Attention 값을 토큰 중요도의 지표로 활용합니다. 일반적으로 중요한 시각 토큰은 다른 토큰들과 더 많은 상호작용을 가지기 때문에, 중요하지 않은 토큰보다 Attention 값이 상대적으로 높게 나타나는 경향이 있습니다. 이러한 특성을 이용하면 Attention 값을 기준으로 중요도가 낮은 토큰을 제거할 수 있습니다. 이러한 접근을 대표적으로 보여주는 연구가 VisionZip입니다. |
|
|
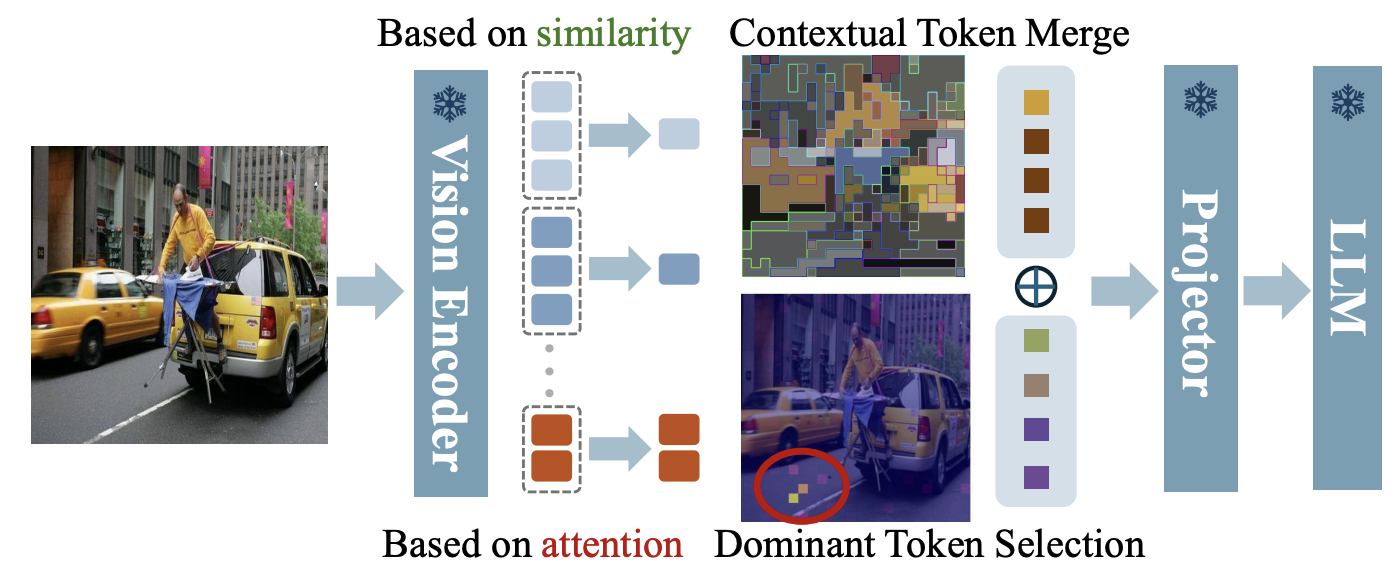
출처: VisionZip: Longer is Better but Not Necessary in Vision Language Models (Yang et al., 2025)
VisionZip은 각 시각 토큰들이 받는 Attention Score를 중요도 지표로 사용합니다. 다른 토큰들로부터 많은 Attention을 받거나 여러 토큰과 강하게 연결된 토큰은 장면의 핵심 정보를 담고 있을 가능성이 높다고 판단합니다. 이러한 기준을 바탕으로 Attention Score가 높은 토큰을 Top-K 방식으로 선택합니다. 여기서 K는 LLM에 전달하려는 비전 토큰의 개수를 의미합니다.
이렇게 선택된 K개의 토큰은 유지하고, 나머지 토큰은 제거하거나 병합(Merging)하여 전체 토큰 수를 줄입니다. 그 결과 LLM에 전달되는 입력 토큰 수가 감소하고, 이후 모든 Transformer 레이어에서 수행되는 Self-attention 연산량도 함께 줄어들게 됩니다.
|
|
|
Diversity-based Vision Token Pruning |
|
|
그러나 높은 Attention Score가 항상 토큰의 중요도를 정확하게 반영하는 것은 아닙니다. 한 연구에서는 Attention만을 기준으로 토큰을 선택할 경우 과업 수행에 중요한 토큰이 간과될 수 있음을 보여주었습니다. 또한 이렇게 선택된 토큰들이 이미지의 특정 영역(예: 주요 객체 주변)에 집중되는 경향이 있어, 이미지에 포함된 다양한 시각 정보를 충분히 반영하지 못할 가능성도 있습니다.
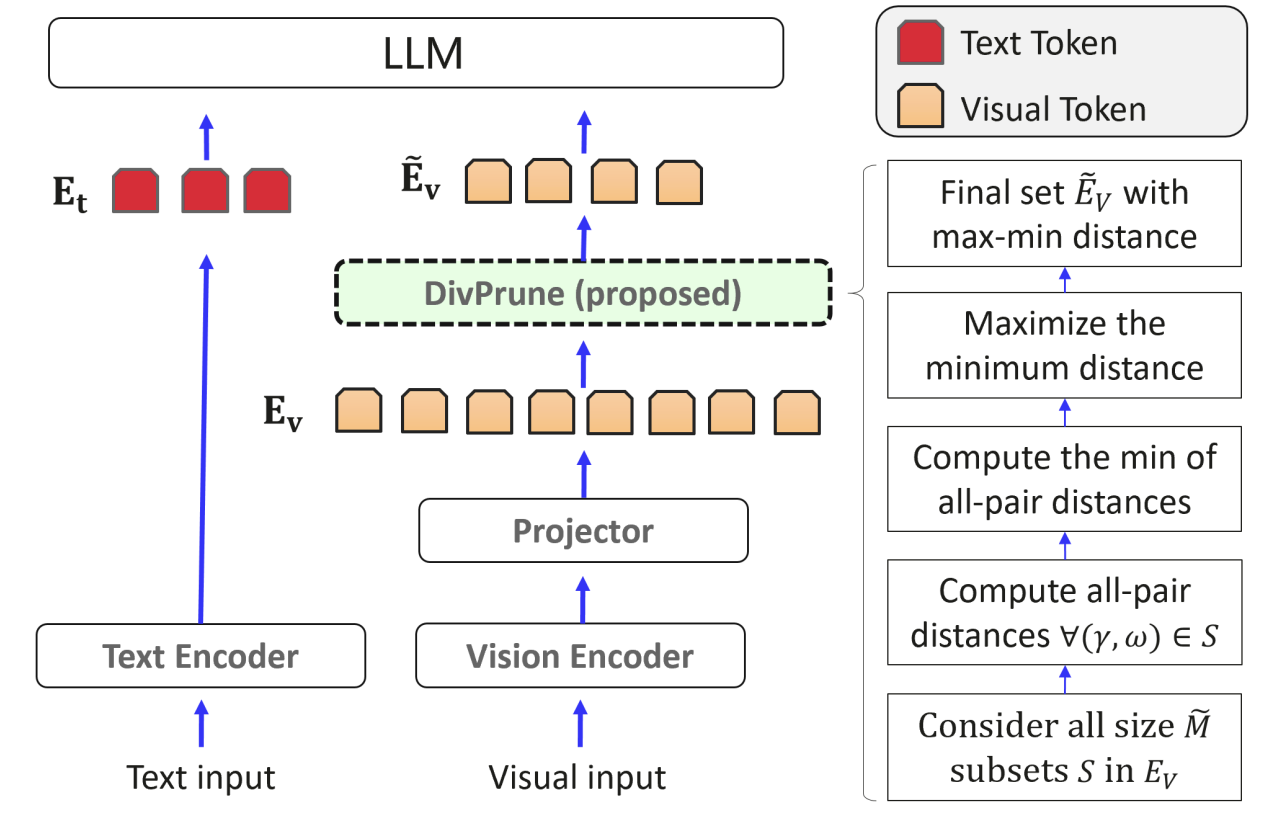
이러한 문제를 해결하기 위해 제안된 방법이 DivPrune 입니다. DivPrune은 토큰의 중요도를 Attention이 아니라 토큰 간의 다양성(Diversity) 관점에서 판단합니다. 이 접근의 출발점은 많은 시각 토큰들이 서로 중복된 정보를 포함하고 있다는 점입니다. 예를 들어 하늘이나 벽과 같은 넓고 균일한 영역에서는 여러 패치 토큰이 서로 매우 유사한 시각 표현을 가지게 됩니다. 이러한 토큰들을 모두 유지하는 것은 새로운 정보를 거의 추가하지 않기 때문에 비효율적입니다. |
|
|
출처: DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models (Alvar et al., 2025)
DivPrune은 이 문제를 Maximum Minimum Diversity Problem (MMDP) 형태로 정의합니다. 목표는 토큰들 사이의 중복을 최소화하면서 서로 최대한 다른 토큰들의 부분 집합을 선택하는 것입니다. 즉 이미지의 다양한 시각 정보를 대표할 수 있는 토큰들을 고르게 선택하여 정보 다양성이 높은 토큰 집합을 구성하는 것을 목표로 합니다.
토큰 선택 과정은 다음과 같은 방식으로 진행됩니다. 먼저 후보 토큰들 사이의 거리 정보를 이용해 다른 토큰들과 가장 구별되는 토큰 하나를 초기 토큰으로 선택합니다. 이후 선택된 토큰 집합과 남아 있는 후보 토큰들 사이의 거리를 계산하여, 현재 선택된 토큰들과 가장 멀리 떨어진 토큰을 하나씩 추가합니다. 이러한 과정을 반복하여 선택된 토큰의 수가 미리 정해진 개수 K에 도달하면 선택 과정이 종료됩니다. |
|
|
Hybrid Vision Token Pruning |
|
|
Attention 기반 방법과 Diversity 기반 방법은 서로 다른 장단점을 가지고 있습니다. Attention 기반 방법은 모델 내부에서 이미 계산되는 Attention 값을 활용할 수 있기 때문에 비교적 간단하게 적용할 수 있으며, 장면에서 지배적인 객체에 집중하는 경향이 있습니다. 반면 Diversity 기반 방법은 토큰 간의 중복을 줄이고 이미지의 다양한 영역을 보다 균형 있게 유지할 수 있다는 장점이 있습니다.
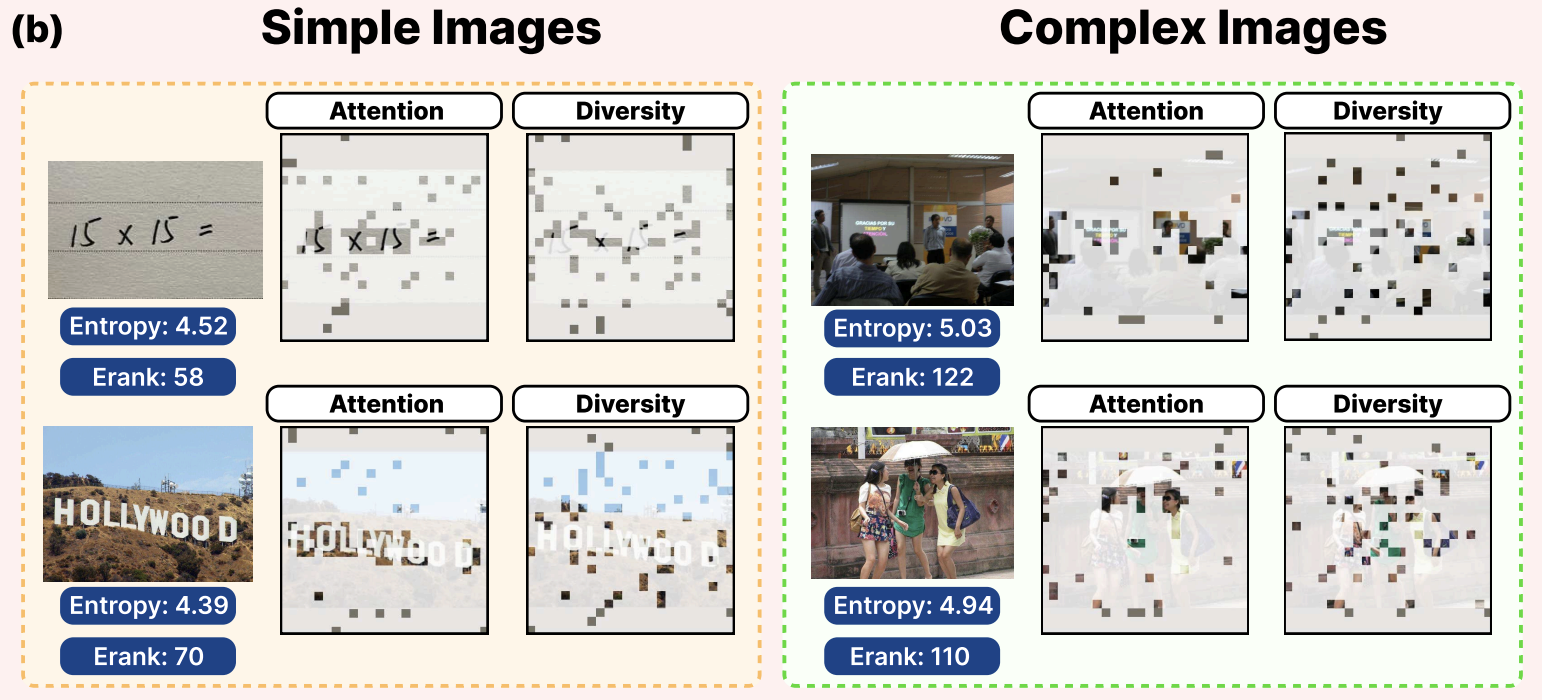
실제 이미지의 구조와 복잡도는 매우 다양합니다. 어떤 이미지는 중요한 정보가 소수의 영역에 집중되어 있는 반면, 어떤 이미지는 장면 전체에 걸쳐 의미 있는 정보가 분산되어 있을 수 있습니다. 예를 들어 단순한 장면에서는 특정 객체 주변에 핵심 정보가 모여 있기 때문에 Attention 기반 선택이 효과적으로 작동할 수 있습니다. 반대로 복잡한 장면에서는 여러 객체와 배경 요소가 함께 등장하므로, 다양한 영역의 정보를 유지하는 Diversity 기반 접근이 더 적합할 수 있습니다.
그러나 기존 연구들은 대부분 하나의 기준만을 사용해 토큰을 선택하는 정적인 방식을 사용해 왔습니다. 이러한 방식은 이미지의 구조나 복잡도에 따라 달라지는 시각 정보의 특성을 충분히 반영하지 못한다는 한계가 있습니다. 따라서 이미지의 특성에 따라 Pruning 전략을 조정하는 Image-aware 접근의 필요성이 제기되었습니다. 이러한 문제를 해결하기 위해 제안된 연구가 바로 AgilePruner 입니다. AgilePruner는 이미지의 특성에 따라 두 전략을 유연하게 결합하는 Hybrid Vision Token Pruning 방법을 제안합니다. |
|
|
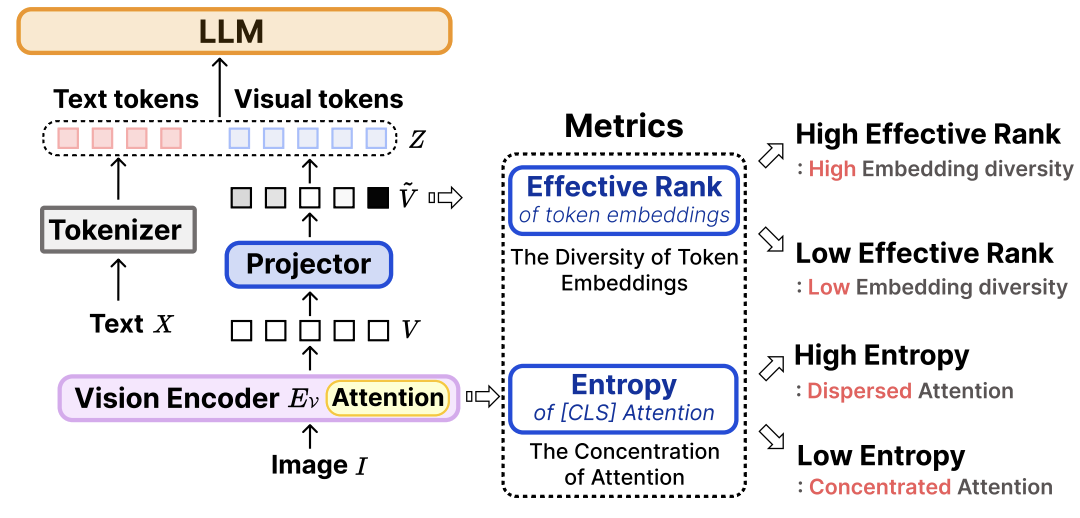
AgilePruner는 먼저 이미지의 복잡도(image complexity)를 추정하기 위해 두 가지 지표를 사용합니다.
첫 번째는 Attention Entropy입니다. 이는 Vision Encoder에서 클래스 토큰([CLS])이 각 시각 토큰을 얼마나 바라보는지를 측정하는 지표입니다. 이를 위해 Vision Encoder의 끝에서 두 번째 레이어에서 얻은 Head-averaged Attention Score를 사용합니다. 이때 [CLS] 토큰의 Self-attention을 제외한 뒤, 나머지 Attention 값을 확률 분포 p로 정규화합니다. 이후 이 분포에 대해 Shannon entropy를 계산하면 attention entropy가 얻어집니다. |
|
|
이 값이 작을수록 Attention이 소수의 토큰에 집중되어 있음을 의미하고, 값이 클수록 여러 토큰에 고르게 분산되어 있음을 의미합니다. 따라서 이 지표는 이미지의 중요한 정보가 특정 영역에 집중되어 있는지, 혹은 여러 영역에 분산되어 있는지를 나타내는 데 사용됩니다.
두 번째 지표는 Token Embedding의 다양성을 측정하는 Effective Rank (Erank)입니다. Erank는 토큰 임베딩 행렬이 실제로 얼마나 다양한 차원을 활용하고 있는지를 나타냅니다. 이를 계산하기 위해 먼저 토큰 임베딩 행렬에 대해 특이값 분해(SVD)를 수행하여 특이값(σ_i)을 구한 뒤, 이를 정규화하고 Entropy 기반 수식을 통해 Erank 값을 계산합니다. |
|
|
Erank 값이 작을수록 토큰 임베딩이 소수의 주요 차원에 집중되어 있음을 의미하며, 값이 클수록 여러 차원에 걸쳐 정보가 분산되어 있음을 의미합니다. 따라서 Erank는 이미지가 얼마나 다양한 시각 정보를 포함하고 있는지를 정량적으로 나타내는 지표로 활용됩니다. |
|
|
출처: AgilePruner: An Empirical Study of Attention and Diversity for Adaptive Visual Token Pruning in Large Vision-Language Models (Baek et al., 2026)
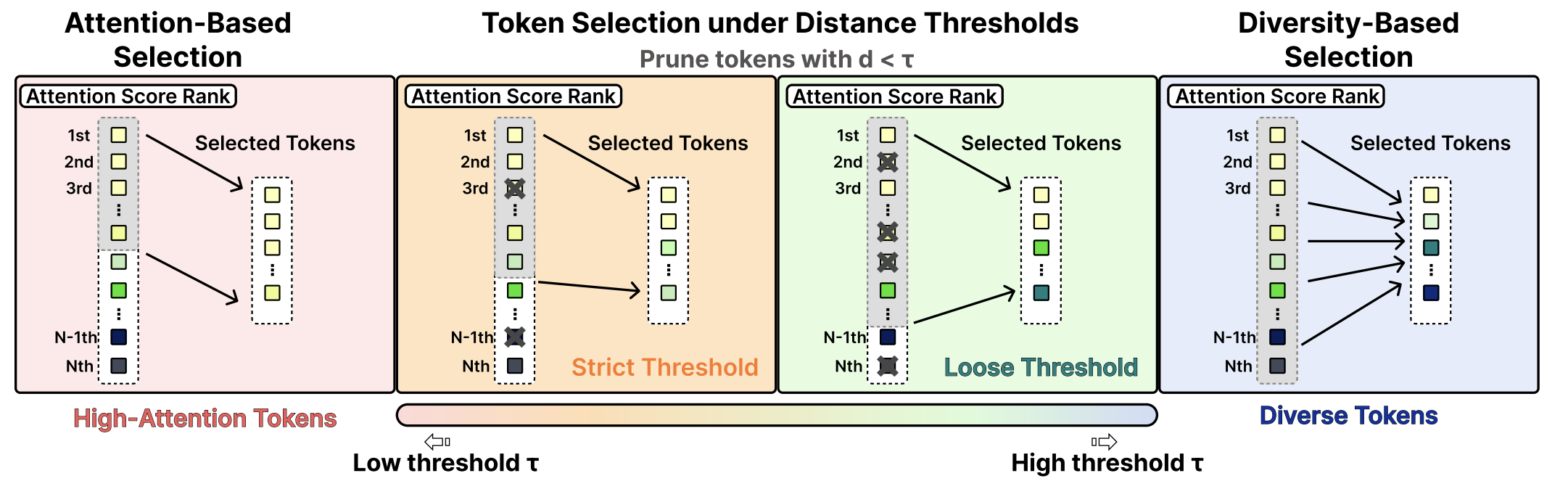
구체적으로, AgilePruner는 먼저 Attention score를 기준으로 시각 토큰들을 정렬하고, 높은 attention을 받는 토큰부터 순차적으로 선택합니다. 그러나 단순히 attention 순위만을 기준으로 토큰을 선택하면 동일한 객체 주변의 패치들이 함께 선택되어 선택된 토큰이 특정 영역에 집중되는 문제가 발생할 수 있습니다. 이를 방지하기 위해 AgilePruner는 이미 선택된 토큰들과의 특징 공간 거리도 함께 고려합니다.
이 과정에서 사용되는 것이 바로 유사도 임계값 τ입니다. 새로운 후보 토큰이 이미 선택된 토큰과 매우 유사하여 거리 d가 임계값보다 작으면 (d<τ) 해당 토큰은 제외됩니다. 반대로 충분히 다른 특징을 가지는 토큰은 선택됩니다.
유사도 임계값은 attention 기반 선택과 diversity 기반 선택 사이의 균형을 조절하는 역할을 합니다. 임계값이 작은 경우에는 Attention score가 높은 토큰 중심의 선택이 이루어지고, 임계값이 커질수록 더 다양한 영역의 토큰이 유지되면서 Diversity가 높은 토큰 집합이 형성됩니다. 결과적으로 AgilePruner는 임계값을 통해 Attention과 Diversity 사이의 균형을 조절하여 이미지의 특성에 맞는 토큰 선택 전략을 유연하게 적용할 수 있습니다. |
|
|
지금까지 Vision Token Pruning이 어떤 문제에서 출발했으며, 어떤 방식으로 발전해 왔는지 살펴보았습니다. 모델의 성능을 높이기 위해 더 많은 연산을 사용하는 것도 중요하지만, 더 나아가 연산을 어디에, 어떻게 사용할지 결정하는 것 또한 중요한 문제입니다.
이처럼 연산의 최적화와 배분은 단순히 모델의 추론 속도를 높이는 기술적 성취를 넘어, 인공지능 연구의 지속 가능성(Sustainability)을 담보하는 핵심적인 과제입니다. 거대 모델의 등장이 가속화됨에 따라 이를 학습하고 운영하는 데 소모되는 전력량과 그로 인한 탄소 배출량은 이미 환경적 임계점에 도달하고 있습니다. 이제는 성능을 유지하면서 자원을 절약할 수 있는 효율적인 AI 시스템을 구현하는것을 고민해봐야 할 때입니다. |
|
|
안녕하세요, 다시 한번 인사드립니다. 에디터 잭잭입니다. 🦜
2024년 10월부터 약 1년 반 동안 뉴스레터 팀에서 글을 써 왔는데요. 그 사이 학부생이었던 저는 대학원생이 되었습니다. 많은 것이 변했지만, 뉴스레터를 미리미리 쓰지 못하고 마감 직전에 밤을 새며 글을 쓰고 있는 모습은 여전히 그대로네요. (웃음)
저는 이번 호를 마지막으로 뉴스레터 팀에서 하차하려고 합니다. 대학원생의 본분을 다 하기 위해, 한동안 오롯이 연구에만 집중하려고 합니다. 제가 쓴 글들이 인공지능을 막 공부하기 시작한 분들이나, 이 길이 정말 나에게 맞는지 고민하고 있는 누군가에게 조금이나마 도움이 되었기를 바랍니다. 그동안 제 뉴스레터를 읽어주셔서 진심으로 감사드립니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|