기존 토큰화의 한계와 BabyLM에 실험한 형태론적 토큰화 방법을 소개합니다. #118 위클리 딥 다이브 | 2025년 11월 19일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- BabyLM의 연구 주제와 목표를 정리했습니다.
- 대표적인 토크나이저 BPE의 한계점을 정리했습니다.
- BabyLM에 적용해본 형태론적 토큰화 방법을 소개합니다.
|
|
|
안녕하세요, 에디터 배니입니다.
지난 5일부터 9일까지 몇몇 에디터분들과 함께 중국 쑤저우에서 열린 EMNLP 2025에 참여했습니다. NLP 분야에 특화된 학회인 만큼 다양한 연구 주제들과 새로운 토픽들이 많이 오갔는데요. LLM Agent의 다양한 케이스스터디부터 Steering Vector와 같이 생소한 개념들까지 한 자리에서 접할 수 있는 좋은 경험이었습니다. 학회는 보통 메인 컨퍼런스 그리고 워크샵과 튜토리얼로 이뤄져 있습니다. 전체 기간을 참여하면서 평소 관심 있던 분야의 워크샵도 주의 깊게 봤는데요, 특정한 주제나 데이터셋으로 연구가 이뤄지는 만큼 훨씬 깊이 있고 흥미로운 주제들이 논의됐습니다. |
|
|
중국 쑤저우에서 열린 EMNLP 2025 현장
ⓒ deep daiv.
|
|
|
그중 하나가 바로 BabyLM 워크샵입니다. 올해로 벌써 3번째를 맞은 BabyLM은 1억 개(100M) 이하의 단어로 이뤄진 데이터셋으로 모델을 학습시키는 것을 목표로 합니다. 또한 데이터셋의 내용은 주로 아이들이 읽는 동화, 아이들의 발화, 간단한 지식들로 이뤄져 있습니다. 일반적인 파운데이션 모델이 조(Trillion) 단위의 토큰으로 다양한 난이도의 데이터를 학습하는 것을 목표로 하는 것과 달리, BabyLM은 아기가 언어를 공부해나가듯 언어 모델을 학습시키는 것을 목표로 합니다. 즉, 인간이 언어를 인식하고 학습해나가는 방식을 탐구하면서 이를 언어 모델에 적용하고자 하는 것이죠.
BabyLM 워크샵에는 모델의 학습 난이도를 점점 높여가는 커리큘럼 러닝(Curriculum Learning), 제한적인 데이터셋 속에서 학습을 최적화하기 위한 샘플 효율적인 모델링(Sample-efficient Modeling) 등과 관련된 연구들이 제안됐습니다. 그중에서도 제 흥미를 끌었던 것은 바로 토큰화(Tokenization) 관련 연구였습니다. EMNLP 메인 컨퍼런스에서는 쉽게 보기 어려운 주제인 토큰화 연구가 왜 BabyLM 워크샵에서 다뤄졌을까요? 토큰화와 인간이 언어를 학습해나가는 과정은 어떤 관련이 있을까요? 이번주 뉴스레터는 BabyLM 워크샵에서 발표된 토큰화 관련 연구를 알아 보도록 하겠습니다.
|
|
|
토큰은 모델이 이해할 수 있는 자연어의 최소 단위라고 볼 수 있습니다. 인간이 문장에서 의미 성분을 나누고 이해하는 것처럼, 언어 모델도 사전에 학습된 토크나이저(Tokenizer)에 따라 입력 문장을 쪼개어 이해합니다. 최근 공개된 대부분의 언어 모델에는 보통 BPE 방식의 토크나이저를 활용합니다. BPE는 전체 말뭉치(Corpus)에서 자주 등장하는 문자 쌍으로 묶어 하나의 단어로 취급합니다. 단어는 사용자가 지정한 개수에 도달할 때까지 추가됩니다. BPE를 활용하면 단어쌍이 등장하는 통계에 따라 자동적으로 단어 사전(Vocabulary)이 구성됩니다. 덕분에 토크나이저에 각각의 언어가 가진 문법적 규칙을 따로 적용할 필요가 없고, 대다수의 언어 말뭉치에서 강건한 모습을 보입니다. 이 압도적인 장점 덕분에 BPE는 사실상 표준이 되어, 많은 연구에 관성적으로 적용되고 있습니다. |
|
|
💡 BPE(Byte Pair Encoding)
BPE는 1994년에 제안된 데이터 압축 알고리즘으로, 연속적으로 가장 많이 등장하는 문자 쌍을 찾아 하나의 단위로 병합하는 방식입니다. 자연어 처리에 적용될 때는 먼저 모든 단어를 문자 단위로 분리한 후, 말뭉치에서 가장 빈번하게 연속으로 등장하는 문자 쌍을 찾아 하나의 토큰으로 병합합니다. 예를 들어, 'hug'와 'bug'가 자주 등장하는 말뭉치에서 'u'와 'g'가 연속으로 가장 많이 나타난다면, 이 둘을 'ug'라는 하나의 토큰으로 병합합니다. |
|
|
그러나 이런 방식의 토큰화는 한계가 존재합니다. 우선, 사용자가 모델에 사용할 단어 개수(Vocab Size)를 직접 지정해야 합니다. 모델에 사용할 수 있는 단어 개수가 많아지면 의미 단위로 더 자연스럽게 끊을 수 있고, 문장의 압축률도 높아집니다. 간단히 ‘도서관’으로 예를 들어보자면, 단어 개수가 제한적이어서 ‘도서관’이 하나의 단어 사전에 추가되지 않고 ‘도서’와 ‘관’으로 쪼개질 수 있습니다. 물론, 이런 경우에는 모델이 적절하게 ‘도서’와 ‘관’의 관계를 학습하여 큰 문제는 없을 것입니다. 그러나 하나의 의미를 갖는 단어가 두 개의 토큰으로 쪼개지면서 동일한 문장에 사용되는 토큰 수가 늘어나는 비효율이 발생합니다.
그나마 의미에 맞게 쪼개지면 다행이겠지만, 말뭉치에 따라 ‘도’, ‘서관’처럼 쪼개질 수도 있습니다. 즉, 실제로 의미가 결합되는 방식과 다르게 토큰화가 될 수 있다는 것입니다. 특히, 모델이 텍스트로된 숫자를 인식하거나, 신조어를 해석하는 데 어려움을 겪기 쉽습니다. ChatGPT 같이 똑똑한 모델이라도 여전히 앞글자를 따서 삼행시를 만들거나, 라임을 맞춘 문장을 만들기 어려워하는 것도 같은 맥락입니다. 우리가 원하는 대로 단어를 쪼갤 수 없고 이미 고정된 단어 사전에 따라서만 쪼갤 수 있습니다. 또한, 예시의 ‘서관’처럼 희소한 단어가 추가되게 되면 그 의미를 적절하게 학습하지 못할 수도 있고 이는 전체적인 성능 저하로 이어질 수 있습니다. |
|
|
지금의 빈도 기반 토큰화가 유용한 것은 사실이지만, 본질적으로 인간이 언어를 이해하는 방식과 다릅니다. 인간은 맥락에 따라 유동적으로 단어를 쪼개어 인식합니다. 언어 모델을 인간의 인지 모델에 따라 모델링하겠다는 목표를 세웠다면, 이 토큰화 문제부터 짚어보는 것은 자명해보입니다. |
|
|
토큰화에 인간이 언어를 이해하는 방식을 적용하자 |
|
|
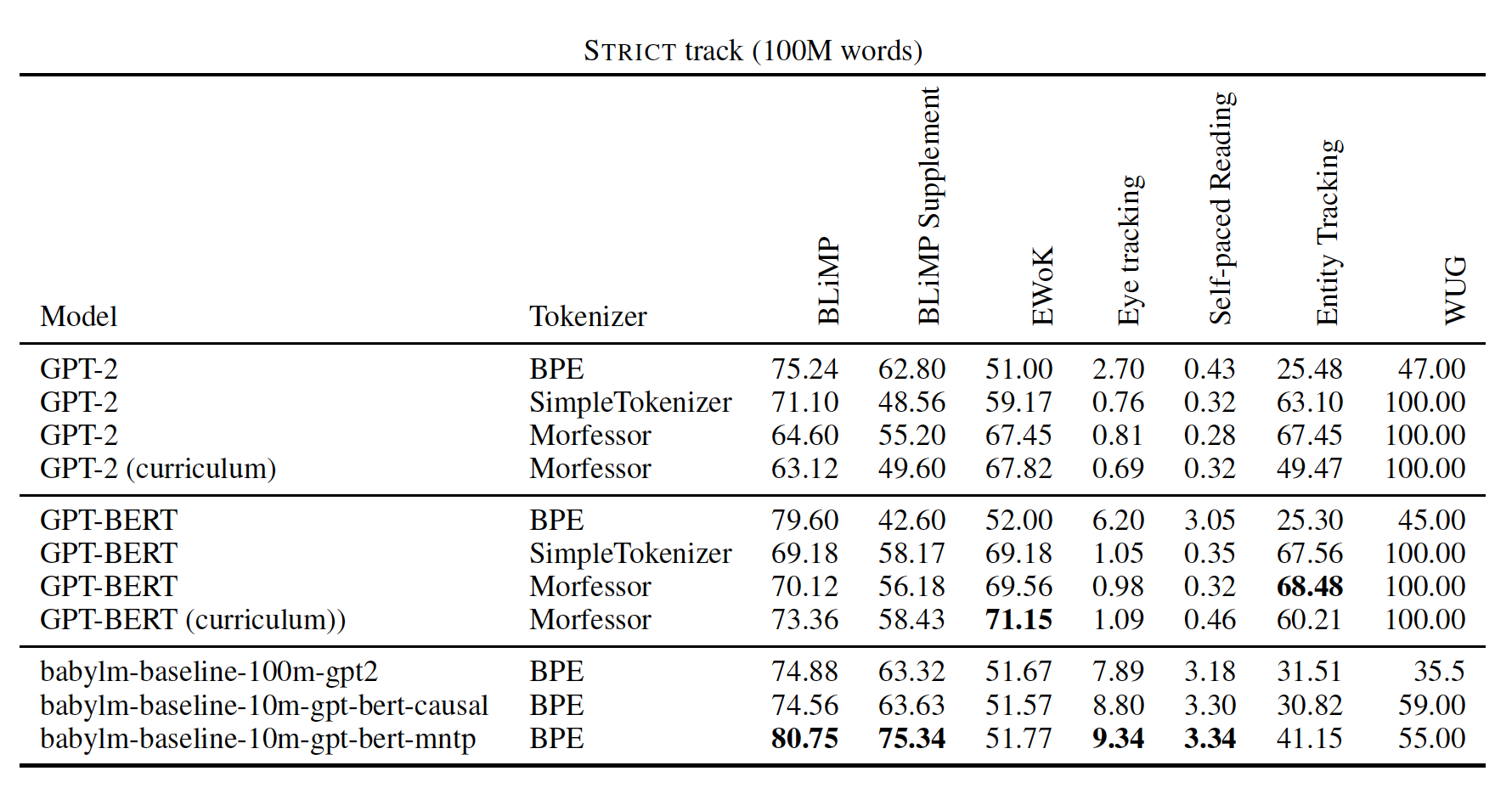
그렇다면 인간이 언어를 이해하는 방식에 따라 토큰화하려면 어떻게 해야 할까요? BabyLM 워크샵에서 발표된 <A Morpheme-Aware Child-Inspired Language Model> 연구에서는 형태론적 토큰화를 제안합니다. 형태론적 토큰화란 단어를 의미 있는 형태소 단위로 분리하는 방법입니다. 형태론적 토큰화를 수행하는 다양한 방법이 있지만, 이 연구에서 사용된 Morfessor는 비지도 학습 방식으로 언어학적 특성을 분석합니다. Morfessor는 말뭉치에서 관찰된 단어들을 가장 효율적으로 설명할 수 있는 형태소 목록을 찾는 것을 목표로 하는데요. 어휘 크기(형태소 목록의 복잡도)와 데이터 설명 비용(형태소로 단어를 인코딩하는 비용) 사이의 균형을 맞춰 토큰화를 하는 것입니다. 이 과정에서 주로 뜻을 나타내는 어근이 추출되고, 이는 대부분의 언어에서 비슷한 패턴을 보이기에 특정 언어에 구애 받지 않고 적용할 수 있다는 장점이 있습니다. |
|
|
위 예시에서 볼 수 있듯이, BPE를 사용했을 때는 과도하게 토큰화하는 경우가 많지만, Morfessor를 적용한 경우에는 실제 의미 단위에 따라 적절하게 토큰화한 것을 볼 수 있습니다. 연구진은 아이들의 언어 습득 과정에서 착안하였다고 밝혔습니다. 아이들은 먼저 어휘를 구축한 후 형태론과 구문론을 학습하며, 서로 다른 단어 형태와 단어 간의 관계를 나중에 배우게 됩니다. 또한, 이러한 특성을 반영하여 커리큘럼 학습도 적용했는데요. 형태론적 정보를 점진적으로 훈련시키며 점차 더 어려운 구조를 이해하는 방식으로 학습시킨 것입니다. |
|
|
그렇다면 이 토크나이저를 적용한 모델의 성능은 어떤 차이가 있었을까요? 실험 결과는 형태론적 토큰화의 효과를 명확히 보여줍니다. 1천 만 단어 데이터셋에서 Morfessor를 사용한 GPT-2 모델은 BPE 토크나이저 대비 EWoK(기본 세계 지식) 점수가 약 20%p 향상되었고, Entity Tracking 점수는 약 40%p 이상 향상되었습니다. WUG 과제에서는 100%의 완벽한 점수를 기록하며, 새로운 단어 형태에 대한 형태론적 일반화 능력이 뛰어났습니다. |
|
|
💡 WUG
WUG(Wug Test)는 언어학자 Jean Berko Gleason이 1958년 개발한 테스트로, 'wug'와 같은 가상의 단어를 사용하여 화자가 언어 규칙을 얼마나 잘 적용하는지 측정합니다. 예를 들어, "This is a wug. Now there are two of them. There are two ____"라는 질문에 'wugs'라고 답할 수 있는지 테스트합니다. 언어 모델 평가에서는 모델이 본 적 없는 새로운 단어 형태(복수형, 과거형 등)를 생성할 수 있는지 테스트하여 형태론적 생산성과 일반화 능력을 평가합니다. |
|
|
다만, 이는 빈도 기반 토큰화보다 형태론적 토큰화가 항상 좋다는 것을 의미하는 것이 아닙니다. 위 결과에서도 볼 수 있듯이, 일부 태스크에서는 여전히 BPE가 우세를 보이기도 합니다. 또한, 설령 형태론적 토큰화가 일부 태스크에서 우세를 보인다고 하더라도, BabyLM이 아닌 다른 태스크에서 일반화될 수 있을지는 미지수입니다. 연구진은 튀르키예어 같이 형태론적 특성이 크게 나타나는 다른 언어에서는 더 큰 성능 향상을 기대할 수 있다고 말했는데요. 학습 자원이 한정적인 상황에서 토크나이저를 다르게 적용하는 것이 유용할 수 있다는 점에 의의가 있습니다.
다른 한편으로는 아직 연구될 게 많은 상황을 의미하기도 합니다. 앞서 언급한 것처럼 모델과 데이터셋의 크기가 커질 때에도 일관된 결과가 나오는지, 왜 그러한 결과가 나오는지 파악해야 합니다. 또한, 방법론적으로도 토큰화가 왜 인간이 학습하는 방식이 기계에는 적용되지 않는지, 만약 인간의 학습 방식을 완벽하게 모방하지 못했다면 어떻게 개선할 수 있는지 분석이 필요하죠. |
|
|
그러나 형태론적 분석도 앞서 말한 토큰화의 한계를 벗어나기 어렵습니다. 형태론적으로 완벽하게 분석했다고 하더라도, 사용 가능한 단어는 여전히 고정되어 있고 모델을 새롭게 업데이트하지 않는 한 새로운 단어를 추가하거나 제외하기 어렵습니다. 이에 대안적으로 Tokenizer-free 방식이 제안되기도 합니다. 고정된 토크나이저를 사용하는 대신 적절한 규칙을 기반으로 맥락에 맞게 토큰화를 적용하는 것인데요. 대표적으로는 지난해 12월, Meta에서 공개된 Byte Latent Transformer가 있습니다.
BabyLM의 기조는 인간의 학습 방식을 모방하고자 했지만, 아직까지 눈에 띄는 시사점을 던지진 못했습니다. 어쩌면 언어 모델이 우리가 언어를 인식하는 것과 다른 것이 당연한 것일 수도 있습니다. 또한 우리가 옳다고 믿어왔던 방식이 사실을 비효율적이었던 것일 수도 있고요. 아마도 AI 분야는 지속적으로 발전해나가면서 우리의 상식을 뒤엎을 것입니다. 그렇게 패러다임이 바뀌었을 때, AI는 인간과 더 닮았을까요? 아니면 인간이 기계를 닮아가야 할까요? |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|