MoE의 구조로 알아보는 오해와 진실 #107 위클리 딥 다이브 | 2025년 9월 3일
에디터 배니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- 최근 주목받고 있는 MoE의 특징을 요약했습니다.
- 직관과 다르게 동작하는 MoE 모델의 실제 원리를 정리했습니다.
- 앞으로 MoE가 해결해야 할 문제를 짚어봤습니다.
|
|
|
안녕하세요, 에디터 배니입니다.
딥러닝의 작동 원리를 두고 흔히 인간의 뇌가 정보를 처리하는 방식에서 착안했다고 얘기합니다. 모델 구조에 ‘신경망(Neural)’이라는 표현을 쓰는 것에서 그 흔적을 찾을 수 있죠. 초기에는 뇌의 메커니즘을 모사하기 위해 노력했지만, 어느 순간부터 매우 다른 길을 걷기 시작했습니다. 그 결과, 실제 뇌의 작동 방식과 무관한 현대 딥러닝 모델 구조가 형성됐습니다.
하지만, 학습의 관점에서 보면 여전히 우리가 생각하는 방식과 많이 닮아 있습니다. 장기 기억과 단기 기억을 구분하여 처리한다든가, 입력 정보의 구성 요소 중 어떤 점에 ‘집중’할지 결정하는 것처럼요. 그리고 최근 몇 년 사이 주목 받고 있는 방법론이 있는데요. 바로, MoE입니다.
MoE는 Mixture of Experts의 줄임말로, 여러 Expert 모델을 하나의 모델 속에 섞어 학습하는 방법론입니다. Experts 모델이 무엇인지 몰라도 직관적으로 어떤 방식으로 동작할지 추측할 수 있죠. 이는 인간이 질문 내용과 관련된 전문가를 찾아가 해답을 구하는 과정과 유사합니다.
사실 이 과정은 우리 머릿속에서도 비슷하게 일어납니다. 일례로, 시각 정보를 처리하는 영역과 언어 정보를 처리하는 영역이 구분되어 있습니다. 덕분에 동시에 두 가지 정보가 입력되더라도 효율적으로 처리할 수 있죠. 이보다 더 세부적으로 언어만 두고 보더라도, 언어를 이해하는 영역과 언어를 생성하는 영역도 나뉘어 있습니다. (전자를 베르니케 영역, 후자를 브로카 영역이라고 부릅니다.) 이는 앞서 언급한 것처럼 특정 역할을 담당하는 전문가에게 업무를 맡기는 것과 유사합니다.
여기서 주목할 부분은 정보를 처리할 때 매번 모든 영역이 활성화되는 것이 아니라는 점입니다. 그러나 기존 딥러닝 모델은 매번 모든 영역이 사용됩니다. 일부 레이어 연산을 건너 뛰거나 특정 부분만 활성화하는 방식이 적용되지 않았죠. 초기에는 큰 문제가 되지 않았지만 모델의 크기는 점차 커져 가면서 점차 효율적으로 처리할 수 있는 방법이 필요했습니다.
MoE 구조는 이런 추세에 좋은 대안이 되었고, 최근 많은 모델에 적용되고 있습니다. 그중 대표적인 모델이 지난 8월 초에 공개된 gpt-oss입니다. gpt-oss는 120B 모델과 20B 모델로 공개됐는데요. 모델 크기가 너무 커서 아무나 사용하지 못할 것 같았지만 실제로 활성화되는 영역은 일부에 불과합니다. OpenAI는 120B 모델과 20B 모델은 추론 시 각각 5.1B 파라미터와 3.6B 파라미터만이 활성화된다고 밝혔습니다. 여기에 양자화와 같은 테크닉을 곁들인다면 20B 모델은 16GB의 VRAM을 가지고 있는 GPU에서 동작이 가능합니다. 이 정도 GPU 사양은 일반적인 고성능 게이밍 PC 정도 수준에 불과한데요. 좋은 컴퓨터를 가지고 있는 일반인이라면 어렵지 않게 서버 없이 GPT 모델을 사용할 수 있는 것이죠. |
|
|
GPT-2 모델 이후 두 번쨰로 공개한 OpenAI의 오픈웨이트 모델로 주목 받은 gpt-oss. MoE 구조로 되어 있어 모델 크기에 비해 사용 접근성이 높다. 누구나 HuggingFace에서 가중치를 받을 수 있다.
출처: OpenAI Blog, <Introducing gpt-oss> |
|
|
뛰어난 성능을 가진 모델을 가볍게 구동할 수 있다는 점에서 MoE는 앞으로 발전할 가치가 높아보이는데요. 그러나 MoE는 이런 설명은 큰 오해를 부를 수 있습니다. MoE에 대해 이렇게 설명만 듣는다면, 정말 ‘전문화된’ 영역만 활성화될 것 같지만 실제 작동 방식은 그렇지 않은데요. 이번 뉴스레터에는 MoE의 구조를 자세히 들여다 보면서 직관과 어떻게 다른지 짚어보도록 하겠습니다. |
|
|
Experts 모델은 ‘분야’의 전문가들이 아니다? |
|
|
MoE 모델은 여러 개의 Expert 모델을 결합한 것입니다. 모델은 주어진 입력을 가장 잘 처리할 수 있는 Expert에게 할당하여 처리할 수 있도록 해야 합니다. 이를 위해서 Gating, 다른 말로 Routing 기법을 적용합니다. 쉽게 말하면, 입력값을 보고 Router가 판단하여 어떤 Expert에 할당하면 좋을지 확률적으로 제시하고 실제로 일부 Expert만 활성화될 수 있도록 넘기는 것이죠. (Router가 어떤 원리로 동작하는지 수식과 개념에 대해 더 자세히 알고 싶다면 이전 뉴스레터를 참고해주세요.)
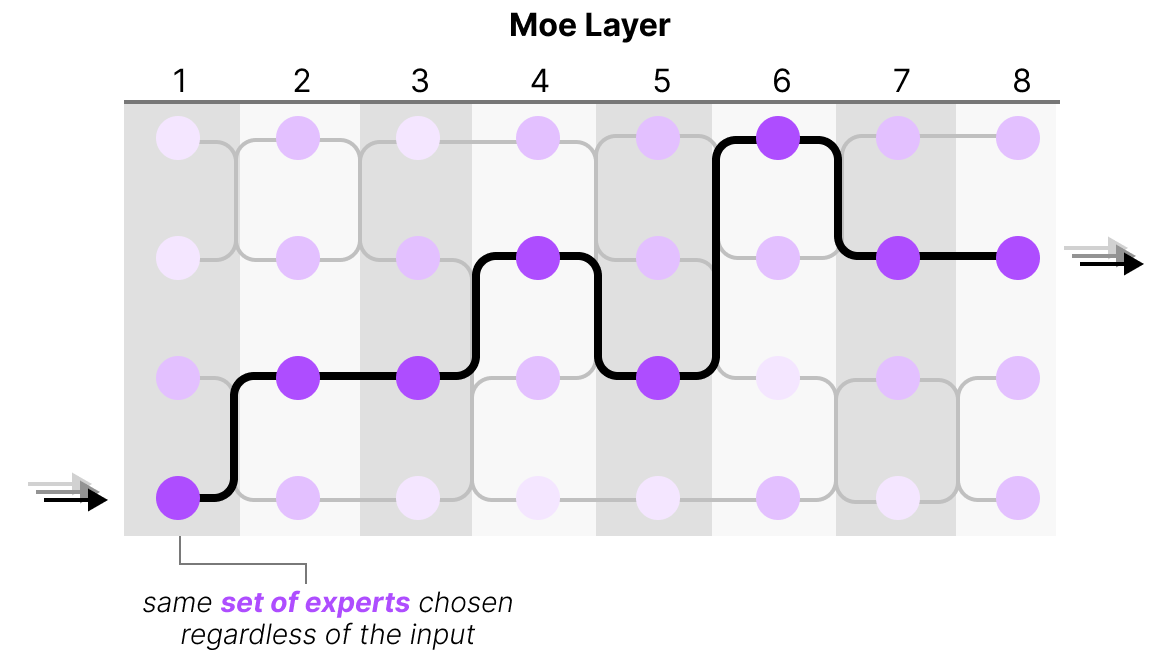
직관적으로는 수학 문제가 주어지면 수학을 담당하는 Expert 모델이 활성화되고, 사회 문제가 주어지면 사회 문제를 담당하는 Expert 모델이 활성화되어야 할 것 같지만 실상은 그렇지 않습니다. Experts 모델이 처리하는 입력 단위는 바로 ‘토큰’입니다. 즉, “1+1은?”이 입력으로 주어지더라도 수학 Expert 모델이 한 번에 모든 것을 처리하는 것이 아니라 1 / + / 1 / 은 / ? 토큰 각각마다 다른 Expert에 할당되는 것입니다. 심지어 레이어마다 다른 Expert가 적용되기 때문에 다소 무작위처럼 보이기도 합니다. |
|
|
물론, 여기서도 우리가 기대했던 대로 모든 토큰이 하나의 전문가에 할당된다면 그나마 직관과 유사한 동작 원리를 기대할 수 있을 것입니다. 하지만 위의 그림은 기대와는 다른 양상을 보여줍니다. 하나의 코드 문제에서도 실제로 여러 전문가에 할당됩니다. 즉, 하나의 입력 문장이 대다수의 전문가들을 고르게 활용하고 있는 것입니다.
그러나 이는 오히려 의도된 것에 가깝습니다. 만약 한 입력에 대해서 하나의 전문가만 활성화되게 된다면 전문가간 불균형이 발생하고, 갑자기 성능이 악화되는 현상인 붕괴(Collapse)가 발생할 수 있기 때문입니다. 이를 막기 위해 강제로 모든 Expert가 학습 기회를 얻을 수 있도록 토큰을 여러 Expert에 분산시키는데요. 이를 Load Balancing이라고 합니다. 이로써 각 전문가가 고르게 학습 기회를 가지며, 결과적으로 일반화 성능이 높아집니다. 즉, 실제로는 한 명의 전문가가 아닌 여러 전문가들이 모여 답을 추론하는 것과 유사한 양상인 것이죠. |
|
|
💡 Load Balancing
Load Balancing은 MoE에서 특정 Expert에 토큰이 몰리지 않도록 제어하는 Auxiliary Loss(보조 손실)입니다. 각 Expert의 사용 빈도와 Routing 확률의 분산을 줄이는 방식으로 구현됩니다. 이를 통해 Expert 간 불균형을 막고, 모든 Expert가 고르게 학습 기회를 얻을 수 있습니다. |
|
|
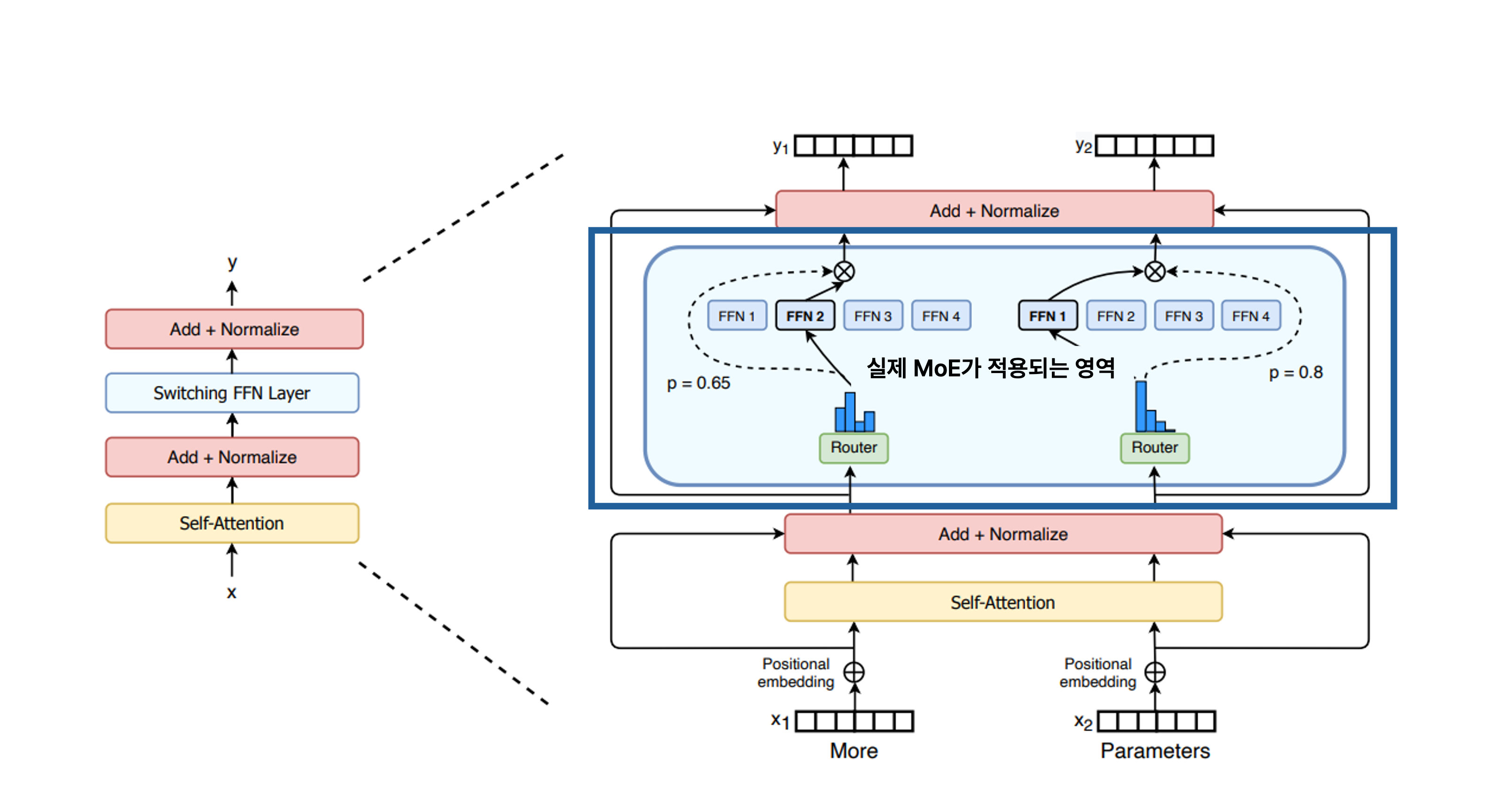
전문가가 다르다면 일반적으로 알려진 각 토큰의 관계는 어떻게 포착하는 것일까요? MoE 모델 구조에도 여전히 동일한 Attention 메커니즘이 적용됩니다. 즉, 토큰별 전문가에 관계 없이 Attention 구조가 적용되는 것이죠. 전문가가 적용되는 영역은 바로 Attention 이후에 나타나는 FFN 부분입니다. 일반적으로는 해당 부분이 토큰에 관계 없이 하나의 FFN 모델에 동일하게 처리되지만, MoE 구조는 이 FFN을 대체하여 Router와 여러 개의 FFN, 즉 Experts 모델에 적용하여 처리합니다. |
|
|
💡 FFN(Feed-forward Network)
보통 2개의 선형 변환과 비선형 활성화 함수(ReLU, GELU)로 이루어진 단순한 MLP입니다. Transformer 블록의 핵심 구성 요소로, 주로 Self-Attention 뒤에 위치합니다. Attention 블록에서 FFN은 Attention에서 모은 정보를 비선형적으로 변환하고 특징을 강화하는 역할을 합니다. |
|
|
이렇게 통과되어 나온 값은 다음 Attention 블럭에 그대로 입력됩니다. 이후로는 우리가 알고 있는 Decoder 구조와 크게 다르지 않죠. |
|
|
MoE 구조에 엄청난 반전은 없었습니다. 기존 Attention 블록 안에 있던 FFN을 확장한 형태에 불과합니다. 물론, Experts 모델 구조를 MLP가 아닌 CNN, Attention 등으로 변형한 연구도 있지만 MoE 연구에서 중요하게 다루는 부분은 아닙니다. 그보다는 어떤 토큰에 어떻게 Expert를 할당해야 더욱 좋은 성과를 얻을 수 있을까 연구하는 데 더욱 집중하고 있다고 봐야 합니다. 즉, 우리 뇌가 적절하게 필요한 정보를 할당받아 처리하는 방법을 알게 된 것처럼 어떻게 학습해야 모델이 일부분이 필요한 정보를 받아 처리할 수 있는지 밝혀내고 있는 것이죠.
비유하자면 지금은 언어를 처리하는 영역을 발견하는 단계에 가깝습니다. 그리고 실제로 뇌도 정확하게 해당 영역만 사용한다기보다는 전체적으로 상호작용하면서 일부분이 크게 활성화되는 것으로 이해하는 게 맞습니다. 어쩌면 우리가 생각하는 것보다 이미 더 뇌 구조와 닮아 있을 수도 있습니다.
아직까지 MoE의 전망은 밝아 보입니다. 이런 Gating 원리는 모델 수준을 넘어 적용되기도 합니다. 확실하게 밝혀진 바는 없지만, GPT-5에는 Gating이 적용되어 필요한 ‘모델’을 불러와 동작하도록 되어 있다고 하는데요. 그밖에도 모달리티 단위에서 Gating이 적용되는 연구, Dynamic Routing 연구 등 다양한 연구가 진행되고 있습니다. 이런 모델을 하나에 통합할 수 있다면 어떤 문제에 대해서도 우리 뇌와 가깝게 동작할지도 모릅니다. 꼭 뇌와 유사하지 않더라도, 새로운 방식으로 인공지능 학습 방법론을 뒤바꿀지도 모르고요. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|