LLaVA 모델에 대해 알아봅시다 🌋 #105 위클리 딥 다이브 | 2025년 8월 20일
에디터 져니 |
|
|
💡 이번주 뉴스레터에는 이런 내용을 담았어요!
- LLaVA에 대해 전체적으로 알아봅니다.
- MLLM의 구조에 대해 정리합니다.
- 미래의 멀티모달의 기준에 대해 제시합니다.
|
|
|
🌋 LLaVA는 어떻게 멀티모달의 기준이 되었는가? |
|
|
안녕하세요! 에디터 져니입니닷😊
멀티모달(Multimodal)이라는 단어을 들어보신 적 있으신가요? 멀티모달이란, 여러가지 모달리티(Modality)를 함께 다루는 분야를 일컫습니다. 여기서 모달리티는 데이터의 표현 형식을 말합니다. 텍스트, 이미지, 오디오, 비디오가 각각 하나의 모달리티입니다. 이미지에 대해 물어보는 작업부터 카메라, LiDAR, GPS등 다양한 모달리티를 사용하는 자율주행과 같은 복합적인 작업 모두가 멀티모달의 영역에 포함되죠.
다양한 멀티모달에 대한 연구나 논문을 접하다 보면, 유독 눈에 들어오는 모델이 있는데요. 바로 'LLaVA'라는 모델입니다. |
|
|
'LLaVA'는 '라바'로 읽혀서 그런지, 저는 LLaVA를 들을 때마다 이런 강렬한 용암과 같은 이미지가 떠오르곤 합니다. 수많은 멀티모달 연구에서 만날 수 있는 용암처럼 핫한 이 모델, 왜 빼놓을 수 없는 모델이 되었을까요? 왜 멀티모달의 중심에는 하필 LLaVA가 있을까요? |
|
|
멀티모달 분야에서 사용하는 모델은 주로 MLLM(Multimodal Large Language Model)이라고 부릅니다. LLaVA 역시 MLLM에 속하죠.
MLLM은 이름에서 유추할 수 있듯이, 대형 언어 모델인 LLM(Large Language Model)이 다양한 모달리티를 처리할 수 있도록 만들어진 모델입니다. 높은 성능을 가진 LLM이 텍스트 이외의 작업이 가능하도록 확장한 셈입니다. |
|
|
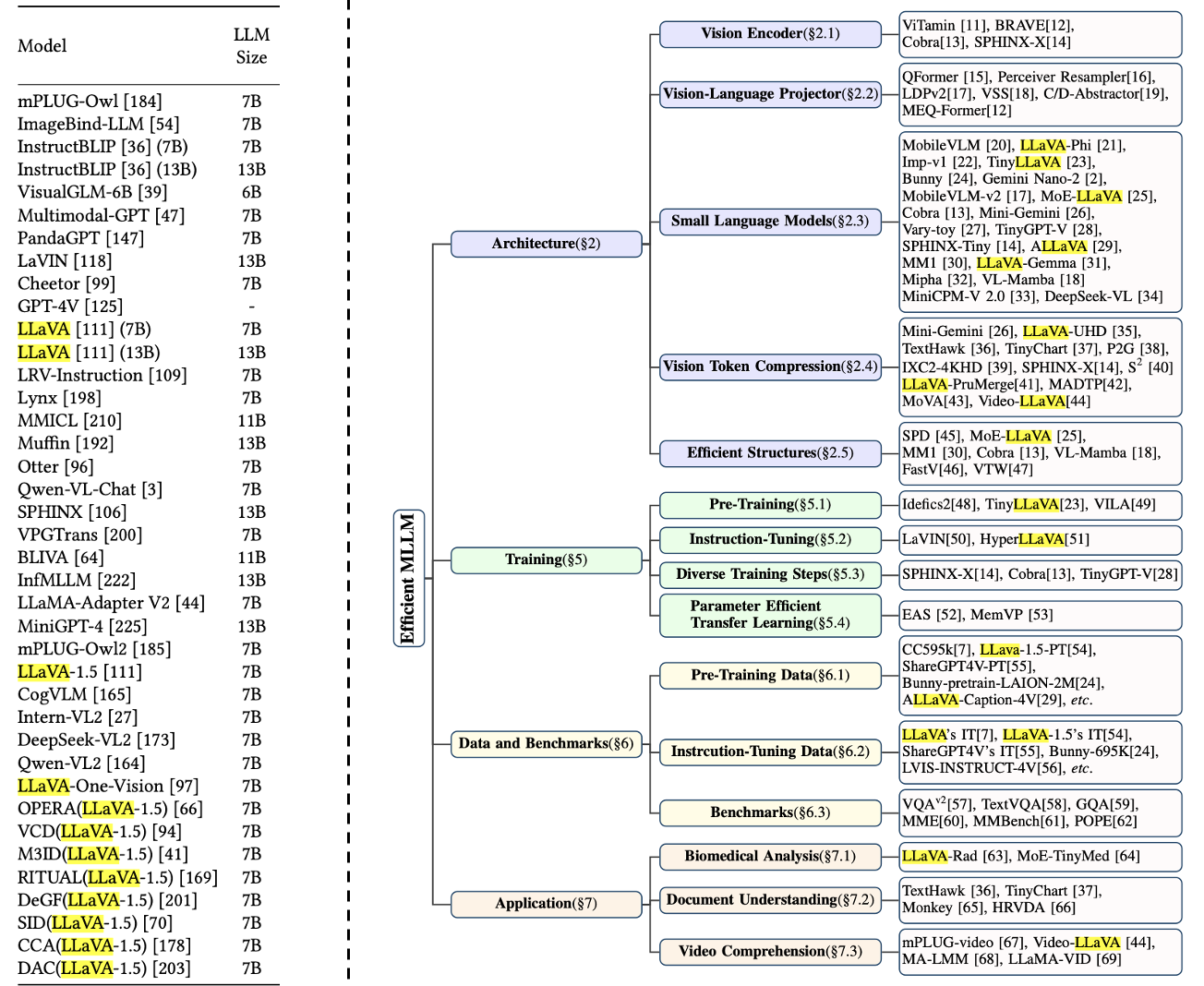
MLLM의 기본적인 파이프라인
출처: ⓒ deep daiv. |
|
|
여기서 핵심은 MLLM이 LLM의 토대 위에서 구조를 만들고 있다는 것입니다. 크게 3가지의 모듈로 이루어져 있습니다. 토대가 될 LLM과 모달리티의 특징을 얻을 수 있는 Modality Encoder가 있죠. 마지막으로 Modality Encoder에서 추출된 비언어적 특징을 LLM이 이해할 수 있는 형식으로 변환하고 정렬하는 Connector가 존재합니다. 이러한 형식을 이용해서 다른 모달리티를 LLM에 통합하는 형식인 거죠. |
|
|
|
LLaVA의 구조를 보면 그 장점을 명확히 알 수 있습니다. LLaVA는 Vision Encoder을 통해 시각적 특징(Visual Feature)을 받습니다. 이를 LLM에 통합하기 위해선 Connector의 역할이 필요한데요, LLaVA의 Connector은 다른 MLLM에 비해 굉장히 직관적이면서 단순합니다.
LLaVA의 Connector는 다층 퍼셉트론인 MLP(Multi Layer Perceptron)를 통해 이미지 특징을 LLM 임베딩 공간에 직접적으로 매핑하는 구조입니다. |
|
|
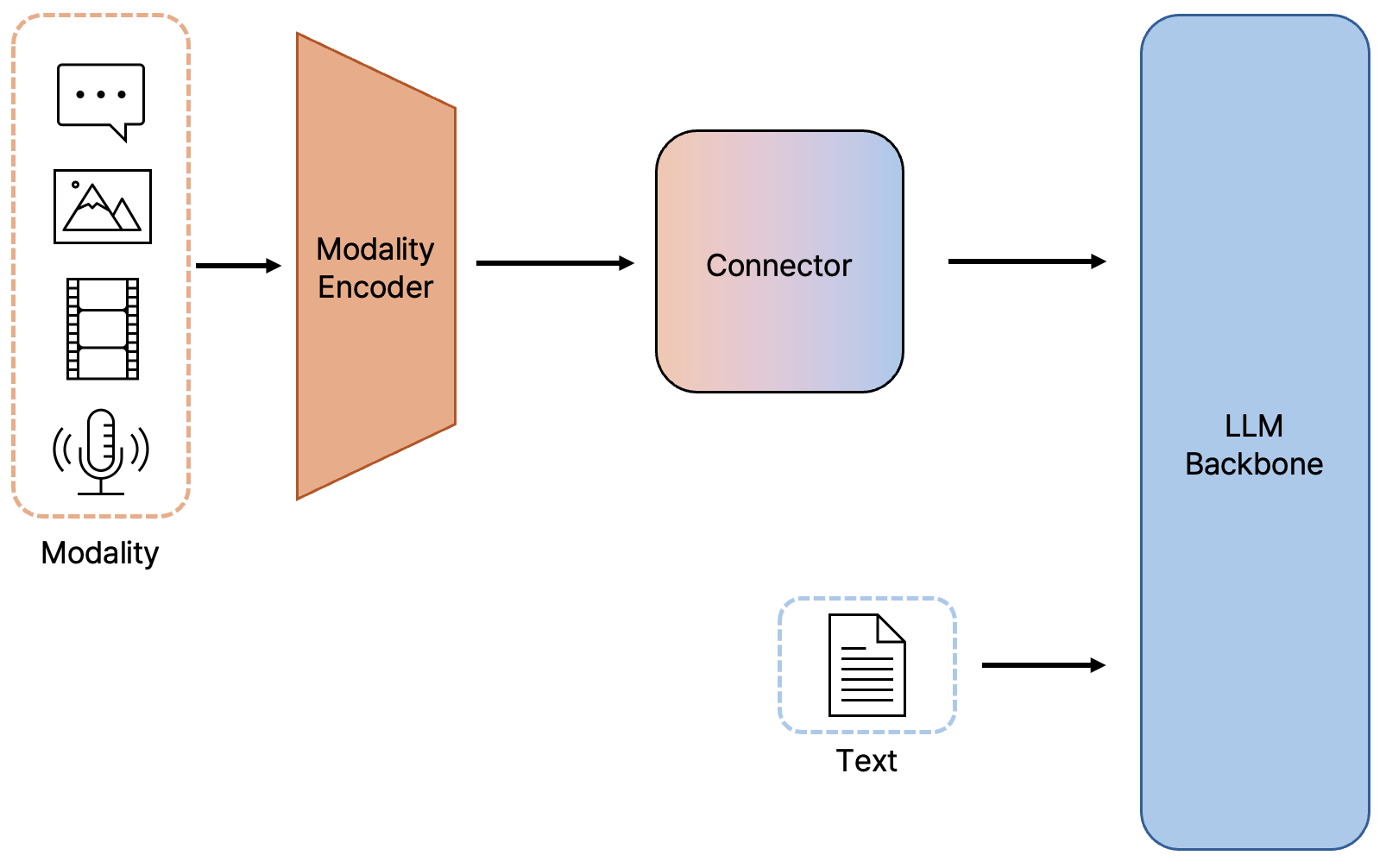
MLP(Multi Layer Perceptron)의 구조
출처: ⓒ deep daiv. |
|
|
MLP는 인공지능에서 가장 기본적이며 단순한 신경망 구조 중 하나입니다. 오직 MLP를 통해서 이미지 특징을 LLM에 전달한다는 것은 최대한 간단한 접속 모델을 통해 두 모달리티를 연결하고자 했다고 해석할 수 있습니다. MLP가 아닌 다른 Connector는 대개 어텐션(Attention)기반 모듈을 사용합니다. 이는 텍스트 토큰과 다른 모달리티의 토큰의 관계성을 파악하는 역할을 합니다. 이 경우 모듈은 더욱 복잡해지고, 토큰마다 관계성을 알아보는 어텐션으로 인해 연산량이 많아집니다. MLP를 이용한 Connector는 효율적이기도 한 셈이죠. |
|
|
LLaVA의 단순하면서 효율적인 구조는 오픈소스 모델로서 큰 장점을 가집니다.
이 직관적인 흐름 덕분에 연구자들은 새로운 아이디어를 자유롭게 실험할 수 있습니다. 복잡한 모듈 대신 블록처럼 쌓아올린 설계 덕분에 더 정교한 Connector를 붙이거나 다른 Vision Encoder로 교체하는 것도 어렵지 않습니다. 결국 LLaVA는 하나의 완성된 모델이면서도, 멀티모달 연구를 위한 실험 플랫폼으로 기능하게 되었습니다.
또한, LLaVA의 또 다른 강점은 효율성입니다. 대규모 상용 모델은 뛰어난 성능에도 불구하고, 그 내부 구조가 공개되지 않았거나 막대한 자원을 요구하기 때문에 자원이 충분하지 않은 개인이나 연구실에서는 다루기 어렵습니다. 반면 LLaVA는 효율적인 구조 덕분에 훨씬 적은 연산 자원으로도 학습과 실험이 가능합니다. 코드와 데이터셋까지 공개되어 있어 누구나 손쉽게 접근하고 재현할 수 있습니다. 이는 곧 멀티모달 연구의 진입 장벽을 낮추고, 적극적으로 실험에 뛰어들 수 있게 만들었습니다.
이러한 LLaVA는 단순한 구조적 장점에 그치지 않고, 실제로 높은 성능을 달성했습니다. |
|
|
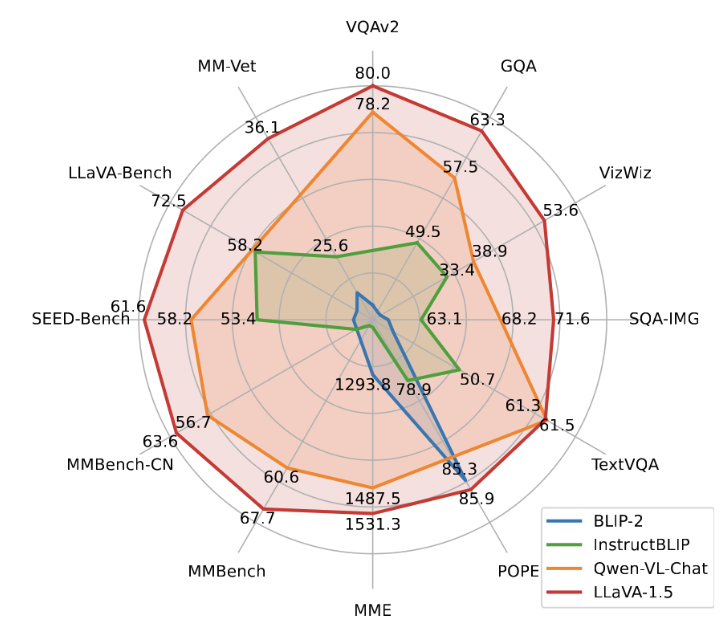
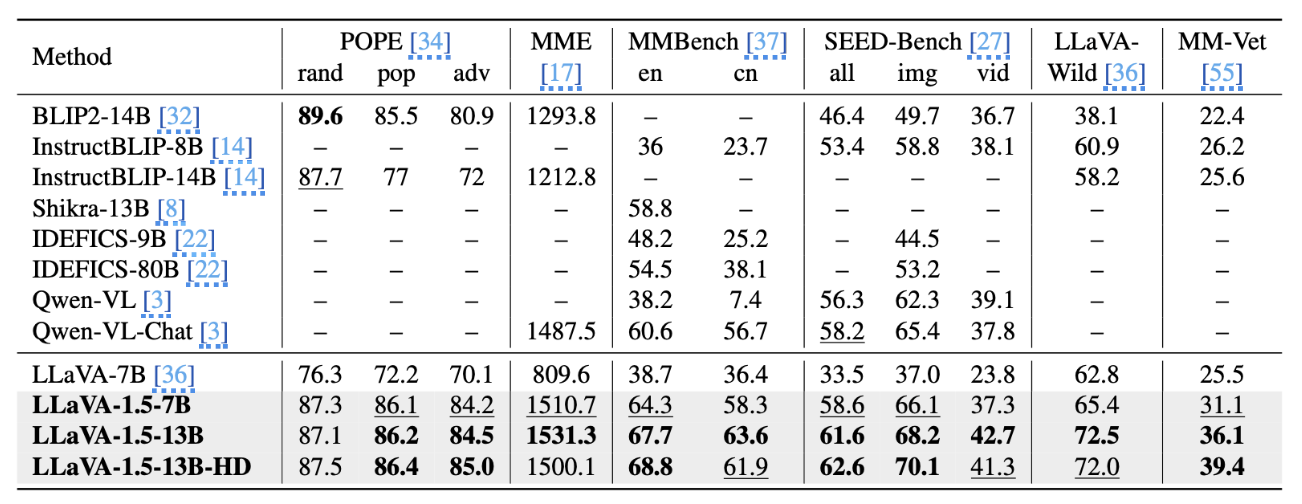
위 그래프는 LLaVA의 모델 중 하나인 LLaVA-1.5가 가지는 성능을 다른 오픈소스 모델과 비교해서 보여줍니다. 다양한 면에서 우수한 성능을 보인다는 것을 확인할 수 있죠. |
|
|
LLaVA-1.5과 다른 모델과의 성능 비교 표
출처: Improved Baselines with Visual Instruction Tuning(Haotian Liu, et al., 2024) |
|
|
어떠한 연구에서도 성능을 공정하게 평가하려면 모두가 납득할 수 있는 기준선이 필요합니다. 바로 이 역할을 한 것이 LLaVA-1.5입니다. LLaVA-1.5는 Improved Baselines로 채택되며 모델의 설계 방향을 체계적으로 제시했습니다. 그래서 LLaVA-1.5는 다양한 범용 벤치마크에서 대표적인 비교 대상이 되었습니다. 이러한 특성은 신뢰할 만한 평가 체계를 제공했고, 그 결과 LLaVA 계열 모델은 높은 성능을 유지하며 멀티모달 연구의 사실상 표준 모델로 자리매김하게 되었습니다. 덕분에 이후의 연구를 통해 등장한 수많은 파생 모델들은 모두 LLaVA-1.5와 동일한 학습 레시피를 따르며 개발되어, 단순히 성능 경쟁만이 아니라 같은 조건에서 얼마나 효율적이고 최적화되어 있는지를 공정하게 비교할 수 있었습니다. |
|
|
LLaVA-1.5에는 기존 모델보다 한층 강화된 Visual Instruction Tuning이 적용됐습니다. Visual Instruction Tuning은 LLaVA가 이미지를 보고, 사람이 내린 지시에 따라 답변할 수 있도록 훈련하는 과정을 의미합니다. LLaVA가 이미지를 보고 말하는 능력을 키워준 핵심 기법이죠.
이후에는 LLaVA-1.5를 더욱 발전시킨 LLaVA-NeXT가 등장했습니다. 이 모델은 기존 구조의 장점을 유지하면서도 더욱 강화된 Vision Encoder를 도입하여 성능을 크게 끌어올렸습니다.
그리고 LLaVA-OneVision도 발표했습니다. OneVision은 더 이상 이미지와 텍스트에만 국한되지 않고, 비디오까지 단일 모델로 통합해 처리할 수 있는 능력을 보여주었습니다. LLaVA-OneVision은 단일 이미지, 다중 이미지, 비디오라는 세 가지를 모두 다룰 수 있는 최초의 단일 멀티모달 오픈소스 모델로 평가받고 있습니다. |
|
|
멀티모달의 기준은 어떻게 바뀔까? LLaVA는 그 속에 있을까? |
|
|
LLaVA는 직관·효율이라는 미덕으로 출발해, 공개 레시피와 재현 가능한 학습 절차를 통해 연구자들이 공정하게 비교하고 개량할 수 있는 토대를 만들었습니다. 그 정점이 LLaVA-1.5였죠. “오픈소스 멀티모달 모델은 이렇게 설계·평가하자”는 기준을 확립했습니다. 그리고 지속적인 업데이트를 통해 범용성 확장의 장점도 가지고 있습니다. LLaVA-OneVision 같이 다양한 모달리티를 다루려는 노력 역시 이뤄지고 있죠.
지금의 LLaVA의 토대 위에서 만들어진 다양한 멀티모달 모델은 표준 벤치마크에서는 강하지만, 더 현실적인 시험으로 갈수록 아직 격차가 존재합니다. 모달리티를 진짜로 해석해야만 풀 수 있는 문제들에 대해서는 성능 하락이 있다는 뜻입니다.
그렇다면 다음 세대의 멀티모달 ‘기준’은 어디로 이동할까요? 제 생각에 이제 초점은 “오픈·재현·전이”라는 LLaVA 모델이 가졌던 덕목을 넘어서,
"다양한 모달리티의 통합 처리"
"토큰·속도·메모리 효율성"
"환각 억제·설명 가능성을 가진 높은 신뢰도"
"엄정한 벤치마크에서의 일관된 성능 유지"
등을 가진 모델로 이동하지 않을까 싶습니다.
그렇다면 LLaVA 모델은 멀티모달의 기준에서 밀려나게 될까요? 아직은 섣부른 예측이라고 생각합니다. LLaVA 계열은 이미지·비디오 과제 전반에서 경쟁력을 유지하고 있습니다. 동시에 초거대 폐쇄형과 최신 대형 모델들 속에서도 상위권을 다투고 있습니다. 여전히 '강한 기준선이자 경쟁자'로 볼 수 있다는 것이죠. 실제로 LLaVA 생태계는 Interleave/Video/OneVision으로 모달리티 통합 방향을 선점하고, 토큰 효율·장문맥·지속 학습을 겨냥한 후속 연구도 빠르게 축적되고 있습니다.
지금 이 순간에도 LLaVA 계열과 그 파생 모델들은 탄탄한 토대와 높은 재현성을 무기로 실전 최적화와 범용성 확장을 병행하고 있죠. 위에서 언급한 다양한 기준을 넘는 새로운 모델이 나오지 않는다면, 멀티모달 분야에서 'LLaVA = 신뢰 가능한 기준선'이라는 위상은 계속 유지될 가능성이 큽니다. 그리고 다음 세대의 표준 모델은 위의 기준을 뛰어넘는 모델이 될 것입니다. 그럼에도 그 속에서 직관적인 LLaVA의 핵심은 여전히 연구자들에게 든든한 버팀목이 될 겁니다. |
|
|
SNS를 팔로우하면
최신 소식을 가장 빠르게 확인하실 수 있습니다 😆
지금 읽고 있는 뉴스레터를 매주 받아 보고 싶다면
아래 '구독하기' 버튼을 클릭해주세요 😉
|
|
|
deep daiv.
manager@deepdaiv.com
|
|
|
|
|